Sequences #72
Comments
|
One idea I've been pondering is to have a single, fairly-general For a (@interface func (export ...) (param $vec i32) (result (seq u8))
(i32.load offset=4 (local.get $vec)) ;; vec.end()
let (local $end i32)
(i32.load offset=0 (local.get $vec)) ;; vec.begin()
memory-to-sequence (func (param $p i32) (result u8 i32 bool)
(lift-int i32 u8 (i32.load8_u (local.get $p))) ;; *p
(i32.add (local.get $p) (i32.const 1)) ;; p = p + sizeof(uint8_t)
(lift-bool (i32.eq (dup) (local.get $end))) ;; (p == end)
)
end
)Inlining the lambda function into the The neat thing though is that the same (@interface func (export ...) (param $list i32) (result (seq u8))
(i32.load offset=0 (local.get $list)) ;; list.begin()
memory-to-sequence (func (param $p i32) (result u8 i32 bool)
(lift-int i32 u8 (i32.load8_u (local.get $p))) ;; *p
(i32.load offset=4 (local.get $p)) ;; p->next
(lift-bool (i32.eq (dup) (i32.const 0))) ;; (p == nullptr)
)
)Lowering is a separate topic, but WDYT about this lifting? |
|
All those wasm .. end sequences are pretty clumsy.
As an alternate to an embedded lambda it would perhaps be more in keeping
with wasm to have special looping blocks. This is the approach I have been
toying with in the scenarios. That way you can make invoking a helper to
its own thing.
The lifting and lowering constructs need to be designed in tandem --
because they have to be rewritten in tandem.
It does look like we are all converging on something though...
Francis
…On Tue, Sep 24, 2019 at 10:12 AM Luke Wagner ***@***.***> wrote:
One idea I've been pondering is to have a single, fairly-general
memory-to-sequence lifting instruction that takes a function immediate
with signature: [i32]→[T,i32,bool] where: the incoming i32 is the pointer
to the element which is to be turned into a T element (for a seq<T>), the
bool result indicates whether there is a next element and, if so, the i32
result is a pointer to it.
For a std::vector<uint8_t> this would look like (using Nick's wasm idea
<#67>, and pulling
in let from function-references
<https://github.com/WebAssembly/function-references/blob/master/proposals/function-references/Overview.md#local-bindings>
):
***@***.*** func (export ...) (param $vec i32) (result (seq u8))
wasm
(i32.load offset=4 (local.get $vec)) ;; vec.end()
end
let (local $end i32)
wasm
(i32.load offset=0 (local.get $vec)) ;; vec.begin()
end
memory-to-sequence (func (param $p i32) (result u8 i32 bool)
wasm
(i32.load8_u (local.get $p)) ;; *p
end
lift-int i32 u8
wasm
(i32.add (local.get $p) (i32.const 1)) ;; p = p + sizeof(uint8_t)
(i32.eq (dup) (local.get $end)) ;; (p == end)
end
lift-bool
)
end
)
Inlining the lambda function into the memory-to-sequence instruction's
implied for loop, this adapter could be compiled fairly easily into a
pretty-efficient loop in machine code. Optimizing this further into a
memcpy would involve some fairly simple analysis, but it's possible that
this would feel arbitrary enough to motivate a more-specialized instruction
that was guaranteed to map to a memcpy.
The neat thing though is that the same memory-to-sequence+lambda design
would allow mapping a std::list<uint8_t> to a sequence just as easily:
***@***.*** func (export ...) (param $list i32) (result (seq u8))
wasm
(i32.load offset=0 (local.get $list)) ;; list.begin()
end
memory-to-sequence (func (param $p i32) (result u8 i32 bool)
wasm
(i32.load8_u (local.get $p)) ;; *p
end
lift-int i32 u8
wasm
(i32.load offset=4 (local.get $p)) ;; p->next
(i32.eq (dup) (i32.const 0)) ;; (p == nullptr)
end
lift-bool
)
)
Lowering is a separate topic, but WDYT about this lifting?
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
<#72?email_source=notifications&email_token=AAQAXUHSFUHMXFKXBRCMGNTQLJDA7A5CNFSM4IZWL2YKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD7PDNYA#issuecomment-534656736>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AAQAXUH2COGLFYTUMCQ3K4DQLJDA7ANCNFSM4IZWL2YA>
.
--
Francis McCabe
SWE
|
|
Yeah, the So for the looping block idea: is the idea that the Agreed that lifting/lowering have to be designed in tandem, but I was trying to keep the post at least somewhat byte-sized and digestible. |
|
What I wound up doing for the wasm instructions in my polyfill was just reimplement them as
Yeah, in the same way that string-to-mem + mem-to-string is very clearly optimizable to memcpy (ish), seq-to-mem + mem-to-seq would be a way of making it clear that that works. We just also need a more general primitive. Which order we ship them in is less important so long as we design both to the point where we're confident.
This sounds like a great document for the working notes :D |
|
A question I have is, are there other data structures that should map to sequences? Stacks and queues should, but their internal memory layout is (probably) similar to a vector. (Hash)Maps are a collection, but need to store a key associated with each element. Do we want to pass sets across an interface? Does it make sense to convert from set to (say) vector? Writing this out, I think the question of "should we let people publish an API that takes collections and call it with the wrong kind of thing?" is answered with "how could we even stop them in theory?" Are there other ways of laying out data in memory aside from contiguously, or spread out with pointers? |
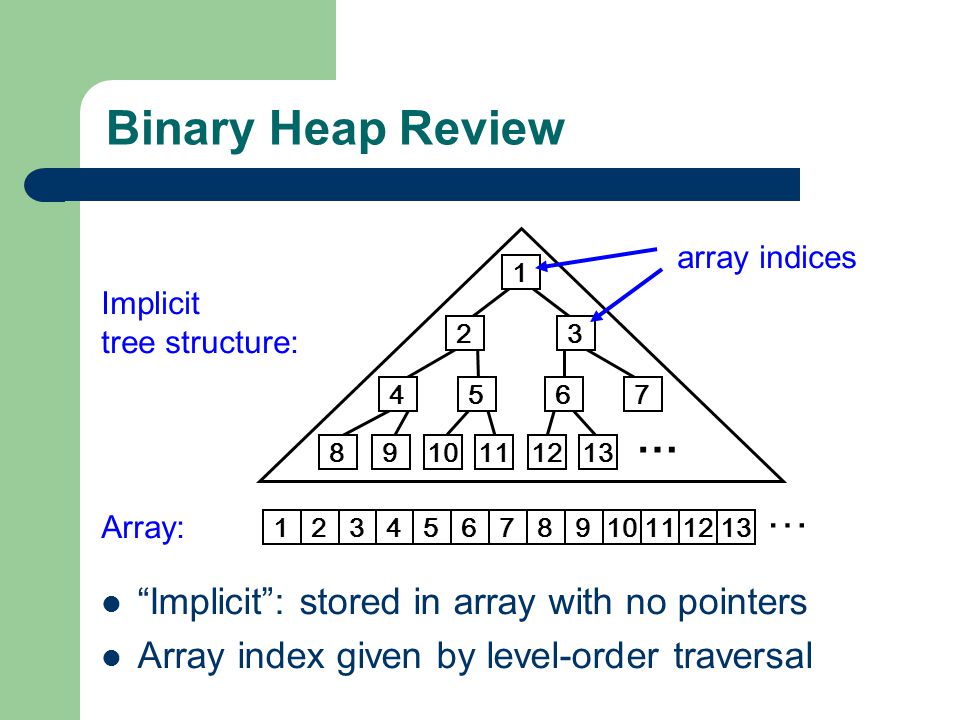{kind=link}
|
We kind of don't/should not care about non-sequence sequences.
Francis
…On Wed, Sep 25, 2019 at 10:07 AM Jacob Gravelle ***@***.***> wrote:
A question I have is, are there other data structures that should map to
sequences?
Stacks and queues should, but their internal memory layout is (probably)
similar to a vector. (Hash)Maps are a collection, but need to store a key
associated with each element.
Do we want to pass sets across an interface? Does it make sense to convert
from set to (say) vector?
If yes, the same principles apply as a linked list, where we may not
expect things to be fast and can always fall back to constructing a value
by repeatedly calling an add_elem export. A sample implementation of a
set could model the data as a tree. If the tree is stored as
explicitly-modeled nodes with pointers to their children, the data is
spread out and we can't expect any magic. If the tree is stored as implicitly-modeled
nodes
<https://slideplayer.com/slide/5107901/16/images/3/Binary+Heap+Review+%E2%80%A6+%E2%80%A6+Implicit+%3A+stored+in+array+with+no+pointers.jpg>,
then we may be able to read the data out (in some order) with a contiguous
memcpy, but in order to maintain the tree invariants if we write data back
in, we need to call exports.
Writing this out, I think the question of "should we let people publish an
API that takes collections and call it with the wrong kind of thing?" is
answered with "how could we even stop them in theory?"
Are there other ways of laying out data in memory aside from contiguously,
or spread out with pointers?
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#72?email_source=notifications&email_token=AAQAXUCK262ZZ3ZBPV2ZYGTQLOLDFA5CNFSM4IZWL2YKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD7SUI6Y#issuecomment-535118971>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AAQAXUEEBUDFAFLWLSYDYRDQLOLDFANCNFSM4IZWL2YA>
.
--
Francis McCabe
SWE
|
|
Right, my point there is not that we need to add anything for non-sequential collections, but that the primitives we have are already enough for people to sequence their non-sequential data. We can (and should) continue to not care about them, but people will use them, and they will mostly work. A related question is what are the essential properties of a sequence. Well-ordered is probably one. Isomorphic across representations could be one? i.e. for all X,Y where X is a type of sequence and Y is a type of sequence, for all n where n is a collection of values, then X(Y(X(n))) == X(n). |
|
Sequence<T> is highly likely to be one of our standard types.
For any given language whose compiler supports generating adapters there
will be a 'language representative' for sequences.
Other data structures in that language will likely need to be coerced into
the language native variant of sequence.
There is a related question though: what about supporting arbitrary generic
collection types. IMO this is doable simply by an elaboration of our
current thinking for record types: with the addition of being able to
plug-in adapters.
E.g., if we had a type:
CCTransaction<Item>
where CCTransaction is some type that models a credit card transaction, and
Item is something that one might purchase with a credit card, then
a. any actual transaction will have a type that grounds the Item type
variable. (This does rule out some higher-order patterns)
b. where Item shows up in the representation of a CCTransaction value,
instead of a fixed lifting/lowering there would have to be code that
lifted/lowered the actual transaction information.
…On Wed, Sep 25, 2019 at 10:24 AM Jacob Gravelle ***@***.***> wrote:
Right, my point there is not that we need to add anything for
non-sequential collections, but that the primitives we have are already
enough for people to sequence their non-sequential data. We can (and
should) continue to not care about them, but people will use them, and they
will mostly work.
A related question is what are the essential properties of a sequence.
Well-ordered is probably one. Isomorphic across representations could be
one? i.e. for all X,Y where X is a type of sequence and Y is a type of
sequence, for all n where n is a collection of values, then X(Y(X(n))) ==
X(n).
For example let n = [1, 2, 2, 3], X = Vector, Y = List, then
Vector(List(Vector([1, 2, 2, 3]))) == Vector([1, 2, 2, 3]), whereas if Y =
Set then we would drop the duplicated 2 so the isomorphism fails to hold.
I don't think we have any mechanism to disallow a user from mapping a set
to a sequence. But we don't have to care about what happens in that case.
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#72?email_source=notifications&email_token=AAQAXUHD53YFMF3VBQ5IEUDQLONFPA5CNFSM4IZWL2YKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD7SV7KQ#issuecomment-535125930>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AAQAXUGFMJVAWHOXE6LVLULQLONFPANCNFSM4IZWL2YA>
.
--
Francis McCabe
SWE
|
Here's a dump of what I've been thinking about sequences so far. This is informed generally by the experimenting I've been doing in my polyfill/interpreter. This isn't so much an "I have answers" so much as it is a "here's why I'm thinking this is tricky"
Core use cases (in order of importance)
Sample sequences
C++ alone has three immediate options:
T*buffer (plus length separately)std::vector<T>std::list<T>Assume vector is implemented as a struct with a pointer to a buffer, a length, and a current capacity.
Assume list is implemented as a doubly-linked list, with pointers to the front and back.
I'm using C++ here because it can represent this in a variety of ways. For any given language I expect we only need to idiomatically support a single style. So for C++ we can have compiler support to autogenerate buffer adapters, but not linked lists, whereas in Scheme we could natively support linked lists but not necessarily anything else.
Complications
Assume we model a buffer of arbitray bytes as
seq<u8>. To support a maximally-efficient copy, we need to have primitives that can be optimized into a single memcpy.For the C-style simple buffer, we can do something similar to
memory-to-string/string-to-memory, which takes ptr + length and produces a seq, and vice-versa (open question: does this handle only u8, or is it parameterized, and what type is it parameterized on, interface types or wasm types?).For the linked list case, this is fundamentally impossible (and that's ok). We do need to be able to build a sequence from a linked list, so we will at minimum need another pair of primitives to do so. In my polyfill I tried
fold-seqandrepeat-until(using helper functions), to go from seq to list and vice-versa.The vector case is surprisingly tricky to handle. On the one hand we can reuse the buffer-copying logic to marshal the actual data over. On the other hand, we need to maintain the vector invariants as we go (length, capacity). We either need to use a fold primitive and call in to the C++ code to push_back every element (and let C++ maintain the invariants), use the mem-to-seq instructions and fix up the invariants at the end, or move the invariant-maintaining logic in to the body of the folds. The only one of those that is amenable to optimization is to defer fixing up the internal state. I can't quite imagine how to express that without hand-writing the adapter, however (although for std::vector, as part of the standard library, we are technically able to do so).
For simplicity of specification it may be nice to just have a single kind of general primitive, some form of fold or loop, and have clear rules for where it is optimized away into a memcpy. It is also probably better to start with the more general primitive, and add alternative more-optimal ones later on.
The text was updated successfully, but these errors were encountered: