在 精读《DOM diff 原理》 一文中,我们提到了 Vue 使用了一种贪心 + 二分的算法求出最长上升子序列,但并没有深究这个算法的原理,因此特别开辟一章详细说明。
另外,最长上升子序列作为一道算法题,是非常经典的,同时在工业界具有实用性,且有一定难度的,因此希望大家务必掌握。
什么是最长上升子序列?就是求一个数组中,最长连续上升的部分,如下图所示:
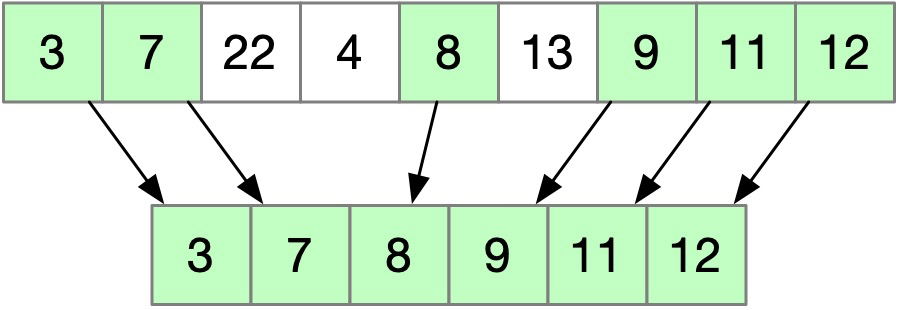
如果序列本身就是上升的,那就直接返回其本身;如果序列没有任何一段是上升的,则返回任何一个数字都可以。图中可以看到,虽然 3, 7, 22 也是上升的,但因为 22 之后接不下去了,所以其长度是有 3,与 3, 7, 8, 9, 11, 12 比起来,肯定不是最长的,因此找起来并不太容易。
在具体 DOM diff 场景中,为了保证尽可能移动较少的 DOM,我们需要 保持最长上升子序 不动,只移动其他元素。为什么呢?因为最长上升子序列本身就相对有序,只要其他元素移动完了,答案也就出来了。还是这个例子,假设原本的 DOM 就是这样一个递增顺序(当然应该是 1 2 3 4 连续的下标,不过对算法来说是否连续间隔不影响,只要递增即可):

如果保持最长上升子序不变,只需要移动三次即可还原:

其他任何移动方式都不会小于三步,因为我们已经最大程度保持已经有序的部分不动了。
那么问题是,如何将这个最长上升子序列找出来?比较容易想到的解法分别有:暴力、动态规划。
时间复杂度: O(2ⁿ)
我们最终要生成一个最长子序列长度,那么就来模拟生成这个子序列的过程吧,只不过这个过程是暴力的。
暴力模拟生成一个子序列怎么做呢?就是从 [0,n] 范围内每次都尝试选或不选当前数,前提是后选的数字要比前面的大。由于数组长度为 n,每个数字都可以选或不选,也就是每个数字有两种选择,所以最多会生成 2ⁿ 个结果,从里面找到最长的长度,即为答案:

这么傻试下去,必然能试出最长的那一段,在遍历过程中记录最长的那一段即可。
由于这个方法效率太低了,所以并不推荐,但这种暴力思维还是要掌握的。
时间复杂度: O(n²)
如果用动态规划思路考虑此问题,那么 DP(i) 的定义按照经验为:以第 i 个字符串结尾时,最长子序列长度。
这里有个经验,就是动规一般 DP 返回值就是答案,字符串问题常常是以第 i 个字符串结尾,这样扫描一遍即可。而且最长子序列是有重复子问题的,即第 i 个的答案运算中,包括了前面一些的计算,为了不重复计算,才使用动态规划。
那么就看第 i 项的结果和前面哪些结果有关系了,为了方便理解如图所示:

假设我们看 8 这个数字,也就是 DP(4) 是多少。由于此时前面的 DP(0), DP(1) ... DP(3) 都已经算出来了,我们看看 DP(4) 和前面的计算结果有什么关系。
简单观察可以发现,如果 nums[i] > nums[i-1],那么 DP(i) 就等于 DP(i-1) + 1,这个是显而易见的,即如果 8 比 4 大,那么 8 这个位置的答案,就是 4 这个位置的答案长度 + 1,如果 8 这个位置数值是 3,小于 4,那么答案就是 1,因为前面的不满足上升关系,只能用 3 这个数字孤军奋战啦。
但仔细想想会发现,这个子序列不一定非要是连续的,万一第 i 项和第 i-2, i-3 项组合一下,也许会比与第 i-1 项组合起来更长哦?我们可以举个反例:
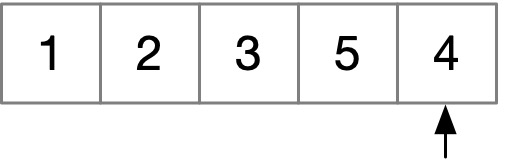
很显然,1, 2, 3, 4 组合起来是最长的上升子序列,如果你只看 5, 4,那么得出的答案只能是 4。
正是由于不连续这个特点,我们对于第 i 项,需要和第 j 项依次对比,其中 j=[0,i-1],只有和所有前项都比一遍,我们才放心,第 i 项找到的结果确实是最长的:

那么时间复杂度怎么算呢?动态规划解法中,我们首先从 0 循环到 n,然后对于其中每个 i,都做了一遍 [0,i-1] 的额外循环,所以计算次数是 1 + 2 + ... + n = n * (n + 1) / 2,剔除常数后,数量级是 O(n²)。
时间复杂度: O(nlogn)
说实话,一般能想到动态规划解法就很不错了,再进一步优化时间复杂度就非常难想了。如果你没做过这道题,并且想挑战一下,读到这里就可以停止了。
好,公布答案了,说实话这个方法不像正常人类思维想出来的,具有很大的思维跳跃性,因此我也无法给出思维推导过程,直接说结论吧:贪心 + 二分法。
如果非要说是怎么想的,我们可以从时间复杂度上事后诸葛亮一下,一般 n² 时间复杂度再优化就会变成 nlogn,而一次二分查找的时间复杂度是 logn,所以就拼命想办法结合吧。
具体方案就一句话:用栈结构,如果值比栈内所有值都大则入栈,否则替换比它大的最小数,最后栈的长度就是答案:
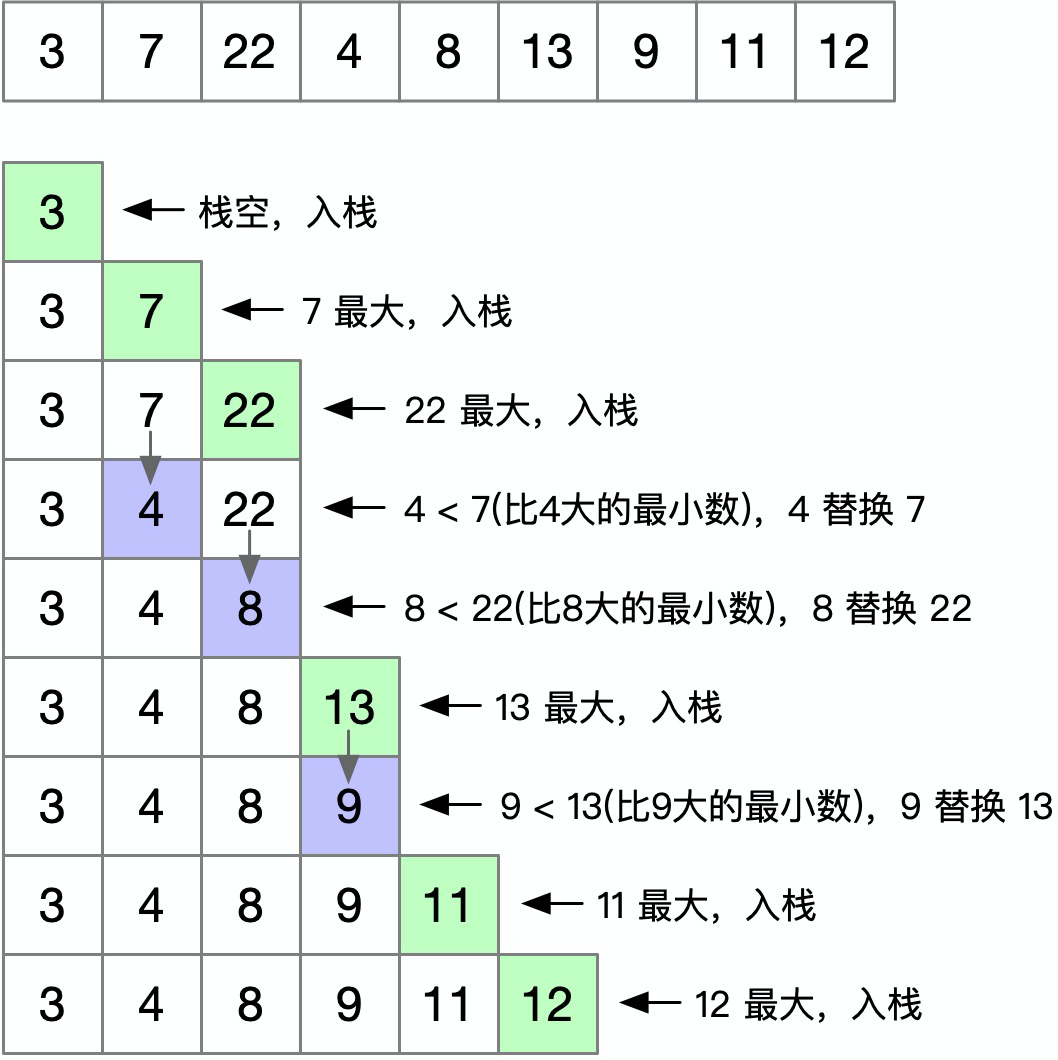
先解释下时间复杂度,因为操作原因,栈内存储的数字都是升序的,因此可以采用二分法比较与插入,复杂度为 logn,外层 n 循环,所以整体时间复杂度为 O(nlogn)。另外这个方案的问题是,答案的长度是准确的,但栈内数组可能是错误的。如果要完全理解这句话,就得完全理解这个算法的原理,理解了原理才知道如何改进以得到正确的子序列。
接着要解释原理了,开始的思考并不复杂,可以边喝茶边看。首先我们要有个直观的认识,就是为了让最长上升子序列尽可能的长,我们就要尽可能保证挑选的数字增速尽可能的慢,反之就尽可能的快。比如如果我们挑选的数字是 0, 1, 2, 3, 4 那么这种贪心就贪的比较稳,因为已经尽可能增长缓慢了,后面遇到的大概率可以放进来。但如果我们挑选的是 0, 1, 100 那挑到 100 的时候就该慌了,因为一下增加到 100,后面 100 以内的数字不就都放弃了吗?这个时候要 100 不见得是明智的选择,丢掉反而可能未来空间更大,这其实就是贪心的思考,所谓局部最优解就是全局最优解。
但上面的思路显然不完整,我们继续想,如果读到 0, 1, 100 的时候,万一后面没有数字了,那么 100 还是可以放进来的嘛,虽然 100 很大,但毕竟是最后一个,还是有用的。所以从左到右遍历的时候,遇到更大的数字优先要放进来,重点在于,如果继续往后读取,读到了比 100 还小的数字,怎么办?
到这里如果无法做出思维的跳跃,分析就只能止步于此了。你可能觉得还能继续分析,比如遇到 5 的时候,显然要把 100 挤掉啊,因为 0, 1, 5 和 0, 1, 100 长度都是 3,但 0, 1, 5 的 “潜力” 明显比 0, 1, 100 大,所以长度不变,一个潜力更大,肯定要替换!这个思路是对的,但换一个场景,如果遇到的是 3, 7, 11, 15, 此时你遇到了 9,怎么换?如果出于潜力考虑,3, 7, 9 的潜力最好,但长度从 4 牺牲到了 3,你也搞不清楚后面是不是就没有比 9 大的了,如果没有了,这个长度反而没有原来 4 来的更优;如果出于长度考虑,留着 3, 7, 11, 15,那万一后面连续来几个 10, 12, 13, 14 也傻眼了,有点鼠目寸光的感觉。
所以问题就是,遇到下一个数字要怎么处理,才不至于在未来产生鼠目寸光的情况,要 “抓住稳稳的幸福”。这里开始出现跳跃性思维了,答案就是上面方案里提到的 “如果值比栈内所有值都大则入栈,否则替换比它大的最小数”。这里体现出跳跃思维,实现现在和未来两手抓的核心就是:牺牲栈内容的正确性,保证总长度正确的情况下,每一步都能抓住未来最好的机遇。 只有总长度正确了,才能保证得到最长的序列,至于牺牲栈内容的正确性,确实付出了不小的代价,但换来了未来的可能性,至少长度上可以得到正确结果,如果内容也要正确的话,可以加一些辅助手段解决,这个后面再说。所以总的来说,这个牺牲非常值得,下面通过图来介绍,为什么牺牲栈内容正确性可以带来长度的正确以及抓住未来机遇。
我们举一个极端的例子:3, 7, 11, 15, 9, 11, 12,如果固守一开始找到的 3, 7, 11, 15,那长度只有 4,但如果放弃 11, 15,把 3, 7, 9, 11, 12 连起来,长度更优。按照贪心算法,我们首先会依次遇到 3 7 11 15,由于每个数字都比之前的大,所以没什么好思考的,直接塞到栈里:
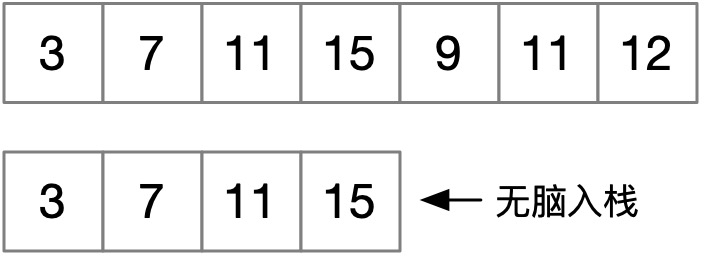
遇到 9 的时候精彩了,此时 9 不是最大的,我们为了抓住稳稳的幸福,干脆把比 9 稍大一点的 11 替换了,这样会产生什么结果?
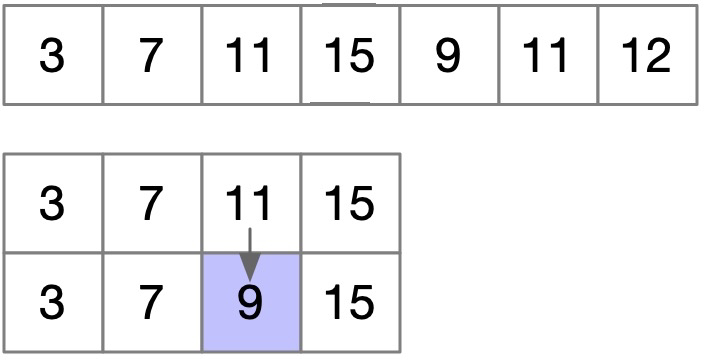
首先数组长度没变,因为替换操作不会改变数组长度,此时如果 9 后面没有值了,我们也不亏,此时输出的长度 4 依然是最优的答案。我们继续,下一步遇到 11,我们还是把比它稍大的 15 替换掉:

此时我们替换了最后一个数字,发现 3, 7, 9, 11 终于是个合理的顺序了,而且长度和 3, 7, 11, 15 一样,但是更有潜力,接下来 12 就理所应当的放到最后,拿到了最终答案:5。
到这里其实并没有说清楚这个算法的精髓,我们还是回到 3, 7, 9, 15 这一步,搞清楚 9 为什么可以替换掉 11。
假设 9 后面是一个很大的 99,那么下一步 99 会直接追加到后面:
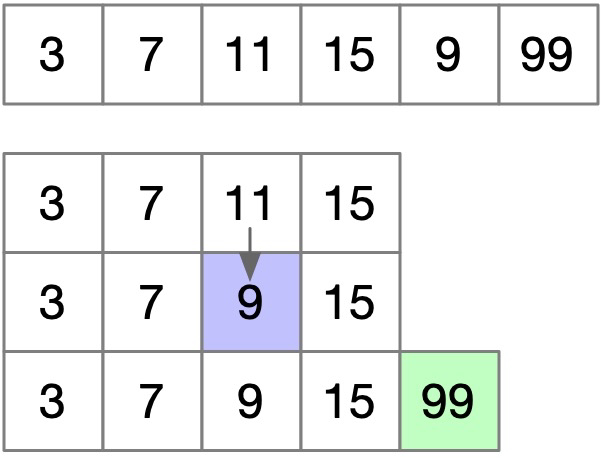
此时我们拿到的是 3, 7, 9, 15, 99,但是你仔细看会发现,原序列里 9 在 15 后面的,因为我们的插入导致 9 放到 15 前面了,所以这显然不是正确答案,但长度却是正确的,因为这个答案就相当于我们选择了 3, 7, 11, 15, 99!为什么可以这么理解呢?因为 只要没有替换到最后一个数,我们心里的那个队列其实还是原始队列。
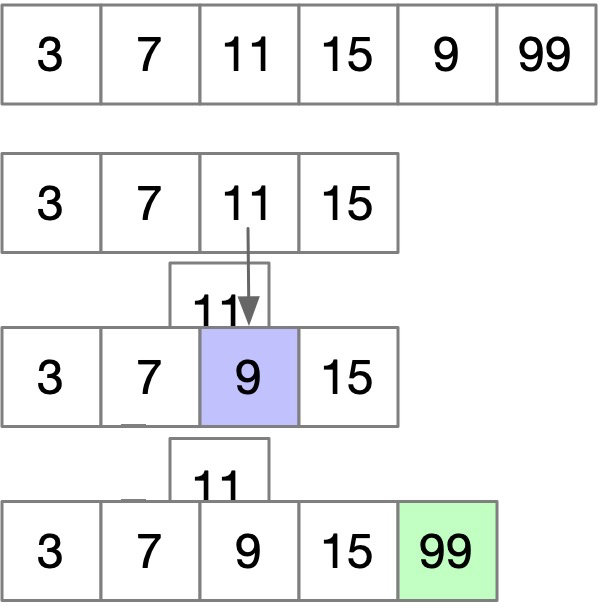
即,只要栈没有被替换完,新插入的值永远只起到一个占位作用,目的是为了让新来的值好插入,但如果真的没有新来的值可插入了,那虽然栈内容不对,但至少长度是对的,因为 9 在没替换完的时候其实不是 9,它只是一个占位,背后的值还是 11。所以不管怎么换,只要没替换掉最后一个,这个替换操作都是无效的,我们再拿一个例子来看:
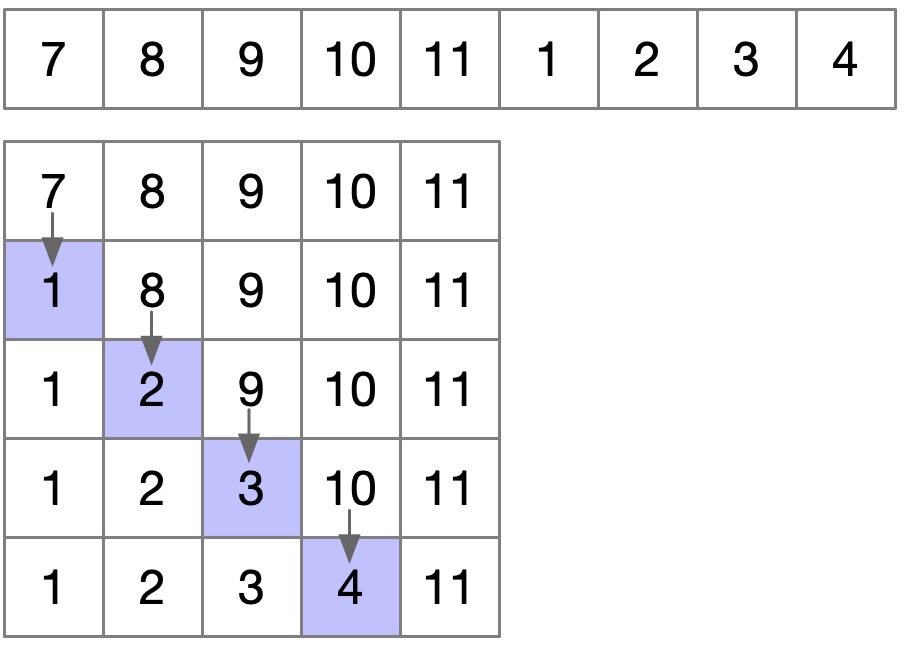
可见,1, 2, 3, 4 不能把 7, 8, 9, 10, 11 都替换完,因此最后结果是 1, 2, 3, 4, 11,但这没关系,只要没替换完,答案就是 7, 8, 9, 10, 11,只是我们没有记录下来罢了,但仅看长度的话,这两个没有任何区别啊,所以是没问题的。那如果 1, 2, 3, 4, 5, 6 呢?我们看看能替换完是什么情况:
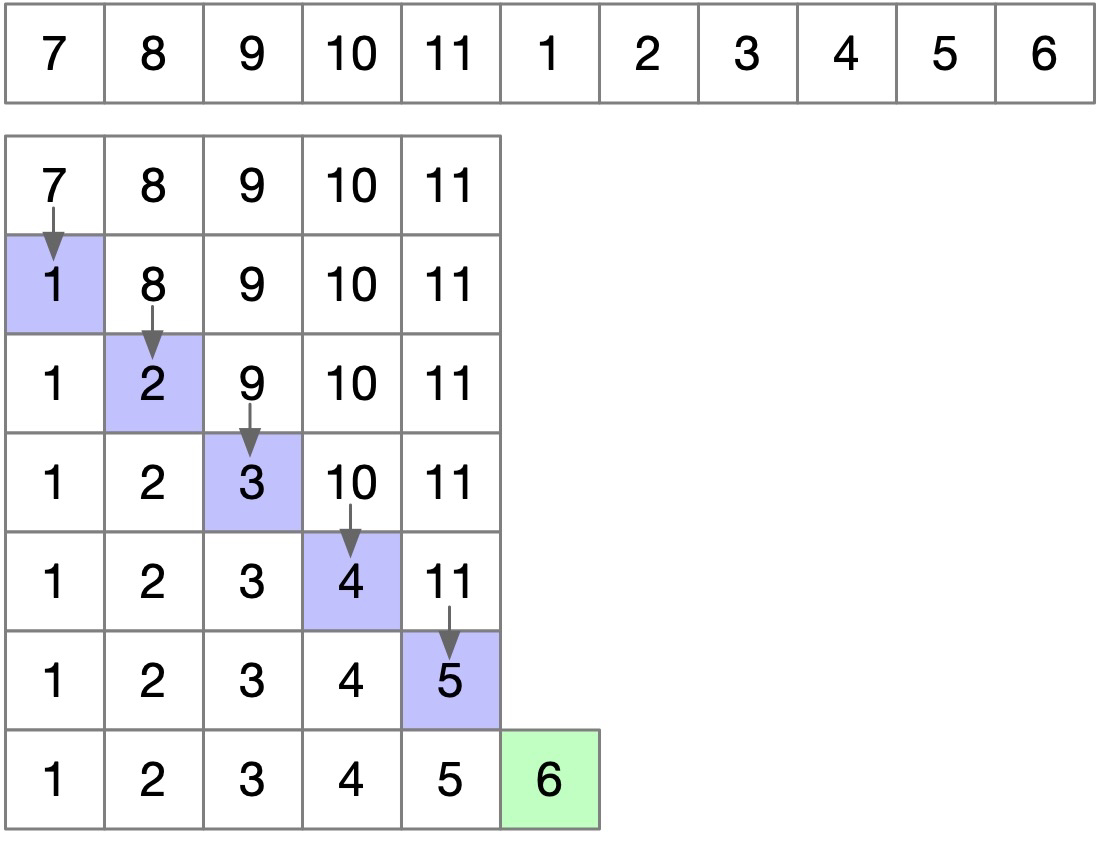
可见,当替换到 5 的时候,这个序列顺序就正确了,因为 1, 2, 3, 4, 5 已经完全能代替 7, 8, 9, 10, 11 了,而且潜力比它大,我们找到了最优局部解。所以 1, 2, 3, 4, 11 这里的 1, 2, 3, 4 就像卧底一样,在 11 还在的时候,还忍气吞声的称 7, 8, 9, 10, 11 为老大(其实是 1 称 7 为老大,2 称 8 为老大,依此类推),但当 5 进来的时候,1, 2, 3, 4, 5 就可以和 7, 8, 9, 10, 11 翻脸了,因为它的实力已经超出原来老大实力了。
那我们前面看似无关紧要的替换,其实就为了不断寻找未来可能的最优解,直到有出头之日那一天,如果没有出头之日,做一个小弟也挺好,长度还是对的;如果有出头之日,那最大长度就更新了,所以这种贪心可以同时兼顾正确性与效率。
最后我们看看,如何在找到答案的同时,还能找到正确的序列呢?
找出正确的序列并不容易,让我们看下面这个情况:
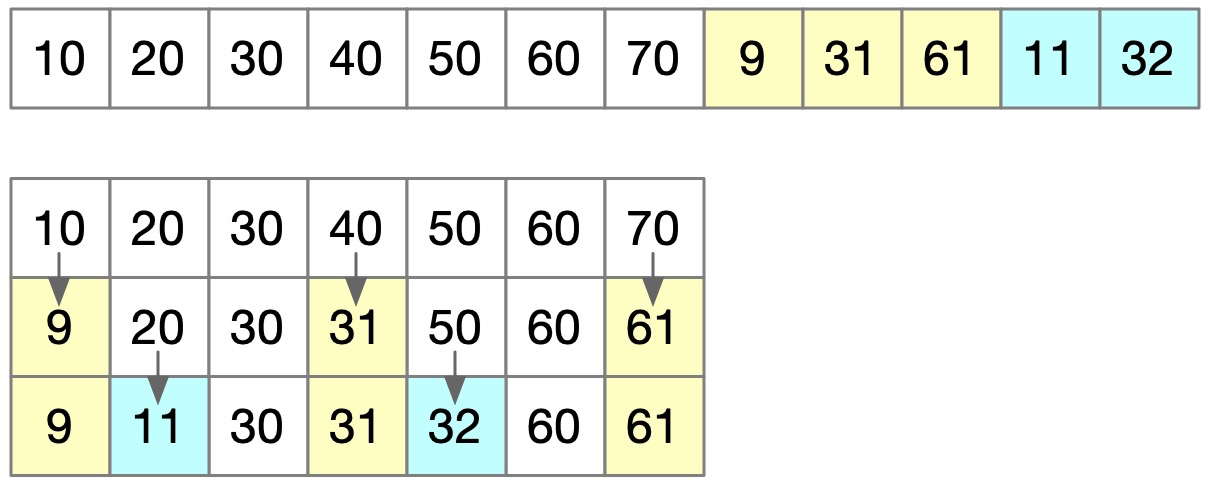
贪心算法结束后,总长度是对的,但很明显顺序还是错的。为了方便计算,我们存储时转化为下标:
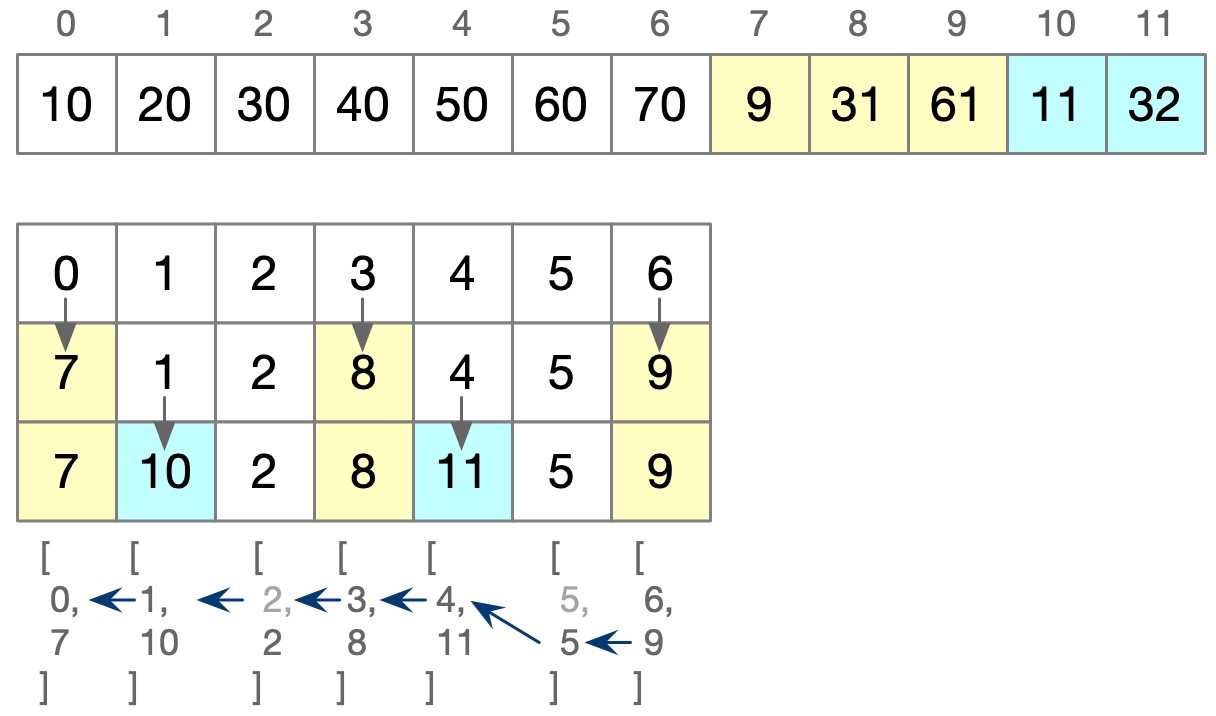
并且使用二维数组存储,这样被替换的数字可以被保留下来。当计算完毕后,我们从最后一位开始向前查找,一旦发现一个值不是单调递减的,就向数组上方继续查找,直到首节点。
因此上面的例子,最终顺序下标是 [0, 1, 2, 3, 4, 5, 9],对应数字为 [10, 20, 30, 40, 50, 60, 61],而且这个数字是潜力最大的最长子序列。
那么 Vue 最终采用贪心计算最长上升子序列,付出了多少代价呢?其实就是 O(n) 与 O(nlogn) 的关系,我们看图:
可以看到,O(nlogn) 时间复杂度增长趋势勉强可以接受,特别是在工程场景中,一个父节点的子节点个数不可能太多的情况下,不会占用太多分析的时间,带来的好处就是最少的 DOM 移动次数。是比较完美的算法与工程结合的实践。
如果你想参与讨论,请 点击这里,每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。
关注 前端精读微信公众号

版权声明:自由转载-非商用-非衍生-保持署名(创意共享 3.0 许可证)