Cache MethodHandles in LocalCacheFactory and NodeFactory #905
Conversation
|
|
|
Thanks! Can you add this to FactoryBenchmark and report the results? You can optionally prefix the command with the java version (e.g. ./gradlew jmh -PincludePattern=FactoryBenchmark --no-daemonWhen I run it locally the throughput seemed fine, but maybe I overlooked something like an internal lock that slows it down. I don't know NewRelic's code, but it sounds excessive to create an instance on every apm transaction. I would have expected a shared cache with a unique transaction id, a lifecycle to clean up explicitly, and maybe weak references as a safety net. The tests compile on Graal JIT, but I don't know the native side enough to bootstrap the full test suite. It might make sense to have a subset for a sanity check, e.g. in examples if others would benefit. Perhaps an easy approach would be to set up a native build using a framework like quarkus or micronaut and piggyback on them having figured it out. |

| return CONSTRUCTORS.computeIfAbsent(className, LocalCacheFactory::newConstructor) | ||
| .construct(builder, cacheLoader, async); |
There was a problem hiding this comment.
A computeIfAbsent can become a bottleneck if present due to pessimistic locking. Our feedback led to some partial improvements in Java 9, but it still remains if unlucky. Caffeine will always do a full prescreen by being optimistic that the entry is present, which would be my preference for CHM to adopt. You can read Doug's rational wrt safepoints, bias locking, etc.
In these cases you can avoid the problem by a lock-free prescreen like,
var factory = CONSTRUCTORS.get(className);
if (factory == null) {
factory = CONSTRUCTORS.computeIfAbsent(className, LocalCacheFactory::newConstructor);
}
return factory.construct(builder, cacheLoader, async);|
I tried porting your idea into the benchmark, which I still feel may not be representative if your profiling is accurate. Last time I ran it on jdk11 and this time on jdk20 which optimized the call much better. It looks like a 19% speedup, though in practice I would expect that to be equivalent (adding the map lookup and being an unlikely bottleneck). This seems like something @franz1981 or @uschindler would know more about than I do. I also feel like you should start a discussion with NewRelic in case they can make a better improvement (e.g. fewer allocations).
diffdiff --git a/caffeine/src/jmh/java/com/github/benmanes/caffeine/FactoryBenchmark.java b/caffeine/src/jmh/java/com/github/benmanes/caffeine/FactoryBenchmark.java
index 00f87b8c..1b4b5c0d 100644
--- a/caffeine/src/jmh/java/com/github/benmanes/caffeine/FactoryBenchmark.java
+++ b/caffeine/src/jmh/java/com/github/benmanes/caffeine/FactoryBenchmark.java
@@ -15,6 +15,7 @@
*/
package com.github.benmanes.caffeine;
+import java.lang.invoke.LambdaMetafactory;
import java.lang.invoke.MethodHandle;
import java.lang.invoke.MethodHandles;
import java.lang.invoke.MethodType;
@@ -24,7 +25,15 @@ import org.openjdk.jmh.annotations.Benchmark;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.State;
+import com.google.common.base.Throwables;
+
/**
+ * This benchmark can be run by optionally specifying the target jvm in the command.
+ * <p>
+ * <pre>{@code
+ * JAVA_VERSION=20 ./gradlew jmh -PincludePattern=FactoryBenchmark --no-daemon
+ * }</pre>
+ *
* @author ben.manes@gmail.com (Ben Manes)
*/
@State(Scope.Benchmark)
@@ -48,6 +57,11 @@ public class FactoryBenchmark {
return methodHandleFactory.invokeExact();
}
+ @Benchmark
+ public Alpha methodHandle_metafactory() {
+ return methodHandleFactory.invokeExact();
+ }
+
@Benchmark
public Alpha reflection() {
return reflectionFactory.newInstance();
@@ -58,12 +72,17 @@ public class FactoryBenchmark {
private static final MethodType METHOD_TYPE = MethodType.methodType(void.class);
private final MethodHandle methodHandle;
+ private final Factory factory;
MethodHandleFactory() {
try {
methodHandle = LOOKUP.findConstructor(Alpha.class, METHOD_TYPE);
- } catch (NoSuchMethodException | IllegalAccessException e) {
- throw new RuntimeException(e);
+ factory = (Factory) LambdaMetafactory.metafactory(LOOKUP, "construct",
+ MethodType.methodType(Factory.class), methodHandle.type().changeReturnType(Alpha.class),
+ methodHandle, methodHandle.type()).getTarget().invokeExact();
+ } catch (Throwable t) {
+ Throwables.throwIfUnchecked(t);
+ throw new RuntimeException(t);
}
}
@@ -82,6 +101,10 @@ public class FactoryBenchmark {
throw new RuntimeException(e);
}
}
+
+ Alpha metafactory() {
+ return factory.construct();
+ }
}
static final class ReflectionFactory {
@@ -104,6 +127,10 @@ public class FactoryBenchmark {
}
}
+ interface Factory {
+ Alpha construct();
+ }
+
static final class Alpha {
public Alpha() {}
} |

|
@ben-manes I updated the benchmark to use blackholes and I got reasonable results on JDK11: I have also updated the computeIfAbsent usage and moved the package lookup into the cached method. |

|
Please @yuzawa-san if you can attach a profiler (async profiler jmh plugin works great) would be great... |
|
Thanks for fixing the blackhole issue. I was under the impression that jmh did that automatically when returning the value (e.g. this thread confirms), but maybe that changed. This lgtm but will wait for other feedback before merging. 🙂 |
|
@ben-manes in theory JMH is doing it, and depending by the version it can use compiler assisted black holes (less noisy, cheaper but sadly, broken in few Jdk versions) or normal ones (heavier, more noisy but works across many different Jdk versions). |
|
Hi, you asked me also about my comment. I can't tell much about the JMH discussion here but about using LambdaMetaFactory: I think the good thing here is that the cache contains a functional interface implementation, so the code (getting the entry from cache and then calling the method can optimized easily) while the previous code using invoke (without exact) needed to do adaptions possibly on every call. I would expect that calling the LambdaMetaFactory is only done relatively seldom and it won't create too many anonymous classes, so basically I think this should behave better. I am a bit afraid, how many different implementations of the interface will be created in normal life. For typical usage of LambdaMetafactory, the number of classes generated by the factory is limited by the number of lambdas in your code (which is bound by the code size and number of lambdas). Here is may be more dynamic, but from looking at the code without knowing when those factory/constructor instances are created I cannot give an opinion. I am just a bit afraid not only because of many classes, but also because of the number of instances makes invoking the interface possibly poly- or megamorphic. This is not covered in your benchmark. So pro/con: I am not sure if this is always a good idea to cache an (possibly) unbound number functional interface implementations instead of Alternatively: Why not simple put the (direct) constructor MethodHandles into the cache? This requires an invokeExact() but this may not be much slower when you have many different cache entries. |
|
I really appreciate the insights @uschindler. For context, these factories are only called when the cache is created by the The reason for all of this was to code generate optimized cache and entry classes (541 total variants). This way we can reduce the memory overhead, such as only including the entry's expiration timestamp or weight if needed. A back-of-the-envelope estimate showed a per-entry range of 54 bytes to 146 bytes, but that lacks the maximal feature configuration which would be higher. An application uses a few cache types so only a couple of these classes will be loaded and there is no runtime cost for an unloaded class on disk. This tradeoff was nice in the pre-AOT JVM, but I understand it is a little annoying for Graal AOT users to whitelist our implementation classes. I'm not sure about why I used invoke instead of invokeExact, it may have been an oversight. When I originally tried using method handles in Java 8 we ran into a memory leak (#222) fixed in Java 10. When preparing v3 for Java 11, I might have reintroduced that too hasselly and used the less optimal variant. A much older implementation didn't use reflection and made direct calls, but that had bytecode bloat and slow classloading to statically map the class types. |
|
Hi,
I would just cache the methodhsndles with correctly adapted types. The problem why you may have used invoke instead of invokeExact might be that constructors by default return exact type. By adapting the methodhandles to the abstract type and then cache them, you can then use invokeExact with the cached handle. We have a similar cache for Attributes in Lucene.
LambdaMetafactory will produce byte code bloat again. 😁 You just wouldn't see it. |
Update LocalCacheFactory.java
f71ec45 to
557aa49
Compare
|
The ahead of time compilation fails to find the lambdas and fails with spring native with this sample application: package com.jyuzawa.springnativecaffeine;
import java.util.concurrent.TimeUnit;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.cache.caffeine.CaffeineCacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Service;
import org.springframework.web.reactive.function.server.RequestPredicates;
import org.springframework.web.reactive.function.server.RouterFunction;
import org.springframework.web.reactive.function.server.RouterFunctions;
import org.springframework.web.reactive.function.server.ServerResponse;
import com.github.benmanes.caffeine.cache.Caffeine;
@EnableCaching
@SpringBootApplication
public class SpringnativecaffeineApplication {
@Bean
public Caffeine<Object, Object> caffeineConfig() {
return Caffeine.newBuilder()
.expireAfterWrite(5, TimeUnit.SECONDS)
.initialCapacity(10);
}
@Bean
public CacheManager cacheManager(Caffeine caffeine) {
CaffeineCacheManager caffeineCacheManager = new CaffeineCacheManager();
caffeineCacheManager.setCaffeine(caffeine);
return caffeineCacheManager;
}
@Bean
RouterFunction<ServerResponse> getEmployeeByIdRoute(MyService myService) {
return RouterFunctions.route(RequestPredicates.GET("/employees/{id}"),
req -> ServerResponse.ok().bodyValue(
myService.getAddress(Long.parseLong(req.pathVariable("id")))));
}
public static void main(String[] args) {
SpringApplication.run(SpringnativecaffeineApplication.class, args);
}
@Service
public static class MyService {
@Cacheable("nameById")
public String getAddress(long customerId) {
System.out.println("CACHE MISS" + customerId);
return String.valueOf(customerId);
}
}
}dependencies {
implementation 'org.springframework.boot:spring-boot-starter-cache'
implementation 'org.springframework.boot:spring-boot-starter-webflux'
implementation 'com.github.ben-manes.caffeine:caffeine:3.1.7-SNAPSHOT'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation 'io.projectreactor:reactor-test'
}I'm decided to cache the method handles for now and that works with that sample application right now. This should be a fair compromise. |
|
Thanks @yuzawa-san, What if we used your LambdaMetafactory idea but use our code generator instead of relying on the JVM to generate the bytecode? Then you could cache instances of your This is already done for The This would make the factory caches more useful and give you the performance of the direct call. It would probably require anyone using AOT to update their class listings to the new types, but they signed up for that when breaking our encapsulation. What do you think? |
| constructor = CONSTRUCTORS.computeIfAbsent(className, LocalCacheFactory::newConstructor); | ||
| } | ||
| try { | ||
| return (BoundedLocalCache<K, V>) constructor.invoke(builder, cacheLoader, async); |
There was a problem hiding this comment.
use invokeExact here after changing the thing below.
| MethodHandle handle = LOOKUP.findConstructor(clazz, FACTORY); | ||
| return (BoundedLocalCache<K, V>) handle.invoke(builder, cacheLoader, async); | ||
| Class<?> clazz = Class.forName(LocalCacheFactory.class.getPackageName() + "." + className); | ||
| return LOOKUP.findConstructor(clazz, FACTORY); |
There was a problem hiding this comment.
Change to: return LOOKUP.findConstructor(clazz, FACTORY).changeReturnType(BoundedLocalCache.class)
This will adapt the return type, so the above call will have correct typoeninformation and invokeExact works.
There was a problem hiding this comment.
One additional thing: Since Java 11 I'd use: https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/lang/invoke/MethodHandles.Lookup.html#findClass(java.lang.String)
So instead of a plain Class.forName() you can use LOOKUP.findClass(), so both fits together much better. This uses the accessibility of the used Lookup and so it ensure that the class is visible and can be loaded. It also simplifies access checks.
use invokeExact and findClass
|
I've updated to use invokeExact and findClass. My spring native project works with this. After reading #552 I'm hesitant to wade into these waters (at least in this PR). Personally, I don't use the native-image stuff and don't know enough about AOT compilation. Like you mentioned in that thread, would prefer that some stakeholders suggest/contribute a possible solution. I thoroughly enjoy this project's usage of codegen to make super fast subclasses of abstract classes and this is not a problem in JIT environments. |
|
Sounds good, thanks @yuzawa-san. I'll take a longer look over the weekend, try to set up a native image for testing, and may switch to caching the factories instead of the method handles. That can done now as |
caffeine/src/main/java/com/github/benmanes/caffeine/cache/LocalCacheFactory.java
Outdated
Show resolved
Hide resolved
|
Sorry that I did not get to this over the weekend, as I am in the midst of rewriting the build to use modern Gradle practices rather than those I learned during its 1.0 infancy. Migrating to kotlin pre-compiled script plugins is time consuming, still has sharp edges, and slow compile cycles. There are some nice qualities and given it is now the default, I thought it best to follow the community to minimize deprecation and compatibility surprises. My plan is to likely not make any java-poet changes to avoid breaking graal user configurations, add some tests, and switch to caching the |
|
@ben-manes no worries. i think i may have a solution. am i on the right track here? i have not rigorously tested this yet. |
|
yep! That's pretty great. I think your change wouldn't impact Graal AOT as its a static field on the class and the current configuration people use by cache class name would continue to work. |
added slow path for our AOT friends
|
@ben-manes just pushed my latest changes:
|
|
Thanks @yuzawa-san. That sounds pragmatic as the slow path is still very inexpensive and only on initialization, so subsequent calls benefit from your cached factory. Thanks for testing it on graal, can you provide your AOT sample somewhere? I'd like to eventually add some AOT tests to the build. fyi, the CI breaks are due to a new cdn added by Gradle that I need to add into our allow list. The network access is restricted to prevent attacks that might modify our binary (e.g. codevcov, circleci, jetbrains incidents). I am making progress on the build rewrite (v3.dev) which includes that fix, so hopefully it will wrap up soon. |
|
@ben-manes this was the native spring app i was referring to #905 (comment) and here is the full build.gradle file plugins {
id 'java'
id 'org.springframework.boot' version '3.0.5'
id 'io.spring.dependency-management' version '1.1.0'
id 'org.graalvm.buildtools.native' version '0.9.20'
}
group = 'com.jyuzawa'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '17'
repositories {
mavenLocal()
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-cache'
implementation 'org.springframework.boot:spring-boot-starter-webflux'
implementation 'com.github.ben-manes.caffeine:caffeine:3.1.7-SNAPSHOT'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation 'io.projectreactor:reactor-test'
}
tasks.named('test') {
useJUnitPlatform()
}it seems a bit intense to run. wonder if there is something simpler. it takes like 10 minutes to build locally. i'll see if i can make it more minimalist by removing all of the spring stuff. |
37b47ce to
9ee97d9
Compare
| public <K, V> BoundedLocalCache<K, V> newInstance(Caffeine<K, V> builder, | ||
| @Nullable AsyncCacheLoader<? super K, V> cacheLoader, boolean async) { | ||
| try { | ||
| return (BoundedLocalCache<K, V>) methodHandle.invokeExact(builder, cacheLoader, |
Check warning
Code scanning / QDJVMC
Unchecked warning
| return (NodeFactory<K, V>) handle.invoke(); | ||
| var clazz = LOOKUP.findClass(Node.class.getPackageName() + "." + className); | ||
| var constructor = LOOKUP.findConstructor(clazz, FACTORY); | ||
| return (NodeFactory<Object, Object>) constructor |
Check warning
Code scanning / QDJVMC
Unchecked warning
|
Thanks @yuzawa-san! I merged this into the v3.dev branch so that I can fix up some of these static analyzer warnings, then I'll merge it into master. Thanks @uschindler and @franz1981 for the help reviewing this! |
|
merged to master with a graal-native example that is run as part of the ci |
|
I wrote a benchmark since we skipped that step as your changes were obviously better. As one would expect, your caching of the factories has a nice speedup. It may be uncommon to make them so frequently, but it is a measurable improvement. In Caffeine's unbounded case it is merely an adapter to a
|
|
Released in 3.1.7 |
This is a performance improvement. I was looking at a flame/icicle CPU graph and found that the class lookup and constructor MethodHandle invoke was happening on every cache build:
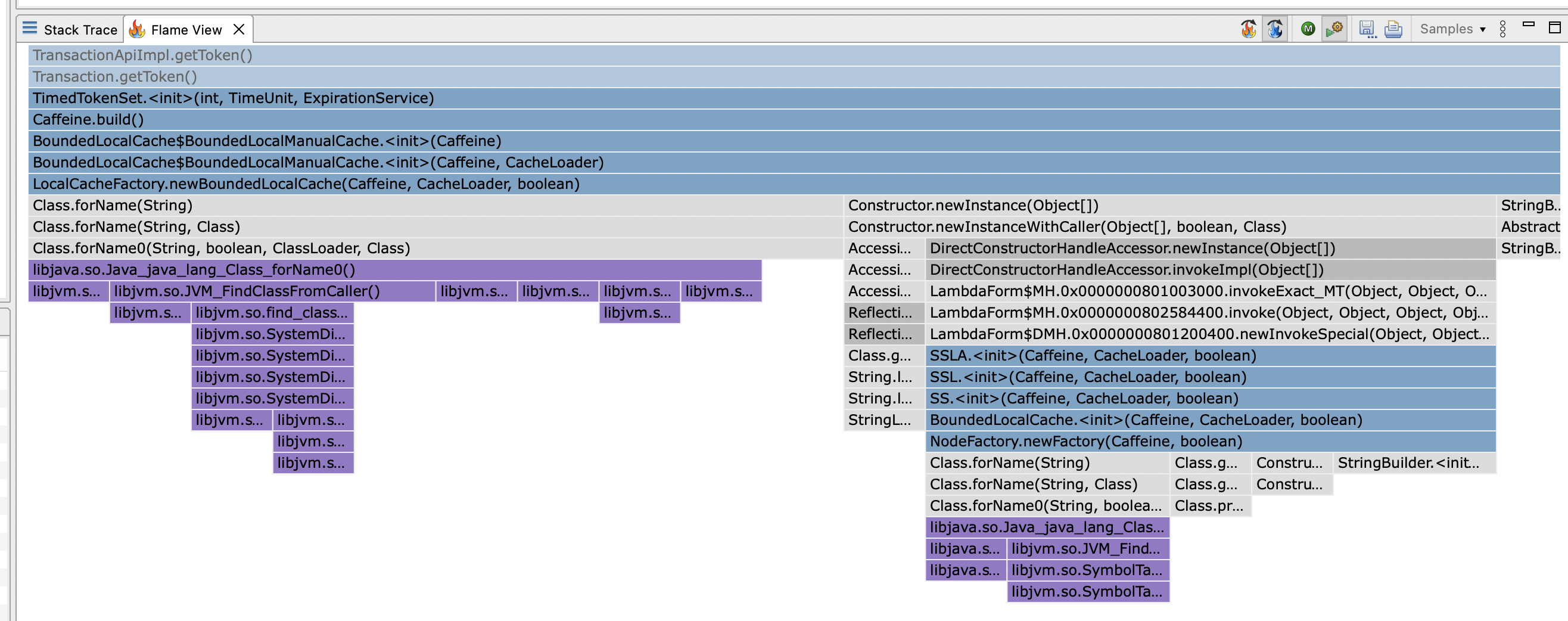
Specifically a new cache is created on each transaction in newrelic's java agent https://github.com/newrelic/newrelic-java-agent/blob/3062016206be7a87e7be9aa65507156d84913a59/newrelic-agent/src/main/java/com/newrelic/agent/TimedTokenSet.java#L39
At first I cached just the constructor's MethodHandle, but then I was able to create lambda implementation using the LambdaMetafactory which should be the fastest way to call these constructors in a dynamic manner.
I think this should be graalvm native safe, but will the github actions verify this?