Releases: concourse/concourse
v6.3.1
🔗 security
- Fix Gitlab connector configuration using Full Name instead of Username
- Any Concourse teams configured with Gitlab users may need to be updated. Previously a Gitlab users Full Name was used to add them to a Concourse team. Now the users Username in Gitlab is used by Concourse to verify team membership. If the Full Name and Username are the same then no change is necessary.
v6.4.0
🔗 feature
- @mouellet added a way of renaming pipeline resources while preserving version history by updating the resource name (as well as any reference in steps) and specifying its old name as
old_name. After the pipeline has been configured, theold_namefield can be removed. #5833
🔗 feature
🔗 fix
- Fixed a regression where builds could be stuck pending forever if an input was pinned by partially specifying a version via the
version:on agetstep,version:on a resource config or by runningfly pin-resource. #5780
🔗 fix
- @evanchaoli fixed a regression that prevented using both static vars and dynamic vars simultaneously in a task. #5758
🔗 fix
- Pipelines can be re-ordered in the dashboard when filtering. This was a regression introduced in 6.0. #5821
🔗 feature
- Style improvements to the sidebar. #5778
🔗 fix
- The sidebar can now be expanded in the UI - no more long pipeline names being cut off! #5782
🔗 feature
- Add
--include-archivedflag forfly pipelinescommand. #5673
🔗 fix
fly loginnow accepts arbitrarily long tokens when pasting the token manually into the console. Previously, the limit was OS dependent (with OSX having a relatively small maximum length of 1024 characters). This has been a long-standing issue, but it became most noticeable after 6.1.0 which significantly increased the size of tokens. Note that the pasted token is now hidden in the console output. #5770
🔗 feature
- Add
--teamflag forfly set-pipelinescommand #5805
🔗 fix
- Fix a validation issue where a step can be set with 0 attempts causing the ATC to panic. #5830
🔗 fix
- Fix tooltip on pipeline names. PR: #5855
🔗 feature
- Refactor existing step structure to simplify introducing new steps. The primary user facing changes are stricter validation and slightly different step validation messages. Previously, fields that were not part of a step wouldn't have failed validation,however, now they will. This will impact stateful actions such as
set-pipeline. PR: #5504, #5878
🔗 feature
- @tlwr updated the
set_pipelinestep to be used across teams. This is 'experimental' for now, please share your feedback in the thread. PR: #5729
🔗 feature
- @evanchaoli added OPA integration to Concourse to enable policy enforcement. The RFC #41 for the integration is still in progress so it is considered 'experimental'. PR: #5034
🔗 feature
v6.3.0
🔗 breaking
- This release bundles
gdnv1.19.12, which assumes the existence of the procfs mount/proc/sys/net/ipv4/tcp_keepalive_time. This mountpoint does not exist inside user namespaces in versions of the Linux kernel before v4.5, so the concourse worker process will fail in such scenarios. The most notable use case affected is docker-compose deployments (which run the concourse worker in a user namespace) on Ubuntu 16.04 LTS which is based on the LTS 4.4 Linux kernel release series. Due to this breaking change, users deploying via docker-compose must ensure they are running at least Linux 4.5 -- most have success by upgrading their operating system to Ubuntu 18.04 LTS based on Linux 4.15.
🔗 feature
-
After switching the default resource checking component to be
lidarduring the v6.0.0 release, users have noticed the resource checking rate has been very spiky. This spiky behaviour is caused by the fact thatlidarruns all the checks that have been queued up at once, causing the spikes of checks to happen all at the same time when the checker runs on its interval.We added a rate limit to resource checking in order to help spread out the rate of checks. Before, without the rate limit resource checking was like .|.|.|.| and now it's like ~~~~~~~.
This rate limit is defaulted to be determined by calculating the number of checkables (resources and resource types) that need to be checked per second in order to check everything within the default checking interval. This means that if there are 600 checkables and the default checking interval is 60 seconds, we would need to run 10 checks per second in order to check everything in 60 seconds. This rate limit of checks can be modified through the
max-checks-per-secondflag to be a static number and also turned off by setting it to-1.On top of adding a rate limit, we also changed the default for the
lidar-scanner-intervalto be10 secondsrather than the previous default of1 minute. This will also help spread out the number of checks to happen on more intervals of the checker. #5676When we upgraded our large deployment to v6.3.0 with the default rate limiter on resource checking, we saw that the number of checks started became much more spread out when compared to before. This first metric shows the number of resource checks started per minute before v6.3.0.
The following metric shows the number of checks started per minute after adding the rate limiting.


🔗 feature
- When distributed tracing is configured, Concourse will now emit spans for several of its backend operations, including resource scanning, check execution, and job scheduling. These spans will be appropriately linked when viewed in a tracing tool like Jaeger, allowing operators to better observe the events that occur between resource checking and build execution. #5659
🔗 feature
-
When distributed tracing is configured, all check, get, put, and task containers will be run with the
TRACEPARENTenvironment variable set, which contains information about the parent span following the w3c trace context format:TRACEPARENT=version-trace_id-parent_id-trace_flagsUsing this information, your tasks and custom
resource_typescan emit spans to a tracing backend, and these spans will be appropriately linked to the step in which they ran. This can be particularly useful when integrating with downstream services that also support tracing. #5653
🔗 feature
- The
set_pipelinestep now supports vars within its plan configuration (thefile:,vars:, andvar_files:fields), thanks to @evanchaoli! #5277
🔗 feature
- When the scheduler tries to start a build with a version that does not exist, it will print an error message to the pending preparation build page. This should help give visibility into why a build is stuck pending. #5477
🔗 feature
- When the scheduler starts a build, it will send a notification to the build tracker to run it. Without this notification from the scheduler to the build tracker, it can take up to approximately 10 seconds before your build gets run after being in a started state. #5631
🔗 feature
- Proxy support for NewRelic emitter
🔗 feature
- Add tracing to allow users and developers to observe volume streaming from source to destination volumes. #5579
🔗 feature
- @evanchaoli added spans for the
load_varandset_pipelinesteps when distributed tracing is enabled. #5706
🔗 fix
- Fixed a bug introduced in v6.1.0 that caused admin users to no longer be able to login to any team. #5741
🔗 fix
- The algorithm within the job scheduler component will now take into account whether or not a version exists in the database while determining a set of input versions for the next build of a job. Previously, when you had an input with passed constraints, it could pick a version that did not exist in the database because it picked versions purely based on if they have passed the upstream passed constraint jobs, regardless if that version did not exist anymore. This fix makes the algorithm skip over versions that do not exist. #5724
🔗 fix
- Fixed a bug where task caches were getting garbage collected everytime you set the pipeline. #5497
🔗 fix
- Fixed a bug "invalid memory address or nil pointer dereference" in NewRelic emitter. #5697
v6.2.0
🔗 breaking
- This release bundles
gdnv1.19.12, which assumes the existence of the procfs mount/proc/sys/net/ipv4/tcp_keepalive_time. This mountpoint does not exist inside user namespaces in versions of the Linux kernel before v4.5, so the concourse worker process will fail in such scenarios. The most notable use case affected is docker-compose deployments (which run the concourse worker in a user namespace) on Ubuntu 16.04 LTS which is based on the LTS 4.4 Linux kernel release series. Due to this breaking change, users deploying via docker-compose must ensure they are running at least Linux 4.5 -- most have success by upgrading their operating system to Ubuntu 18.04 LTS based on Linux 4.15.
🔗 feature
-
Operators can now limit the number of concurrent API requests that your web node will serve by passing a flag like
--concurrent-request-limit action:limitwhereactionis the API action name as they appear in the action matrix in our docs.If the web node is already concurrently serving the maximum number of requests allowed by the specified limit, any additional concurrent requests will be rejected with a
503 Service Unavailablestatus. If the limit is set to0, the endpoint is effectively disabled, and all requests will be rejected with a501 Not Implementedstatus.Currently the only API action that can be limited in this way is
ListAllJobs-- we considered allowing this limit on arbitrary endpoints but didn't want to enable operators to shoot themselves in the foot by limiting important internal endpoints like worker registration. If theListAllJobsendpoint is disabled completely (with a concurrent request limit of 0), the dashboard reflects this by showing empty pipeline cards labeled 'no data'.It is important to note that, if you use this configuration, it is possible for super-admins to effectively deny service to non-super-admins. This is because when super-admins look at the dashboard, the API returns a huge amount of data (much more than the average user) and it can take a long time (over 30s on some clusters) to serve the request. If you have multiple super-admin dashboards open, they are pretty much constantly consuming some portion of the number of concurrent requests your web node will allow. Any other requests, even if they are potentially cheaper for the API to service, are much more likely to be rejected because the server is overloaded by super-admins. Still, the web node will no longer crash in these scenarios, and non-super-admins will still see their dashboards, albeit without nice previews. To work around this scenario, it is important to be careful of the number of super-admin users with open dashboards. #5429, #5529
🔗 breaking
- The above-mentioned
--concurrent-request-limitflag replaces the--disable-list-all-jobsflag introduced in v5.2.8 and v5.5.9. To get consistent functionality, change--disable-list-all-jobsto--concurrent-request-limit ListAllJobs:0in your configuration. #5429
🔗 breaking
- It has long been possible to configure concourse either by passing flags to the binary, or by passing their equivalent
CONCOURSE_*environment variables. Until now we had noticed that when an environment variable is passed, the flags library we use would treat it as a "default" value -- this is a bug. We issued a PR to that library adding stricter validation for flags passed via environment variables. What this means is that operators may have been passing invalid configuration via environment variables and concourse wasn't complaining -- after this upgrade, that invalid configuration will cause the binary to fail. Hopefully it's a good prompt to fix up your manifests! #5429
🔗 feature
- @shyamz-22, @HannesHasselbring and @tenjaa added a metric for the amount of tasks that are currently waiting to be scheduled when using the
limit-active-tasksplacement strategy. #5448
🔗 fix
- Close Worker's registration connection to the TSA on application level keepalive failure
- Add 5 second timeout for keepalive operation. #5802
🔗 fix
- Improve consistency of auto-scrolling to highlighted logs. #5457
🔗 fix
- @shyamz-22 added ability to configure NewRelic insights endpoint which allows us to use EU or US data centers. #5452
🔗 fix
- Fix a bug that when
--log-db-queriesis enabled only part of DB queries were logged. Expect to see more log outputs when using the flag now. #5520
🔗 fix
- Fix a bug where a Task's image or input volume(s) were redundantly streamed from another worker despite having a local copy. This would only occur if the image or input(s) were provided by a resource definition (eg. Get step). #5485
🔗 fix
- Previously, aborting a build could sometimes result in an
erroredstatus rather than anabortedstatus. This happened when step code wrapped theerrreturn value, fooling our==check. We now useerrors.Is(new in Go 1.13) to check for the error indicating the build has been aborted, so now the build should be correctly given theabortedstatus even if the step wraps the error. #5604
🔗 fix
- @lbenedix and @shyamz-22 improved the way auth config for teams are validated. Now operators cannot start a web node with an empty
--main-team-configfile, andfly set-teamwill fail if it would result in a team with no possible members. This prevents scenarios where users can get accidentally locked out of concourse. #5596
🔗 feature
-
Support path templating for secret lookups in Vault credential manager.
Previously, pipeline and team secrets would always be searched for under "/prefix/TEAM/PIPELINE/" or "/prefix/TEAM/", where you could customize the prefix but nothing else. Now you can supply your own templates if your secret collections are organized differently, including for use in
var_sources. #5013
🔗 fix
- @evanchaoli enhanced to change the Web UI and
fly teamsto show teams ordering by team names, which allows users who are participated in many teams to find a specific team easily. #5622
🔗 fix
- Fix a bug that crashes web node when renaming a job with
old_nameequal toname. #5639
🔗 fix
- @evanchaoli enhanced task step
varsto support interpolation. #5620
🔗 fix
- Fixed a bug where fly would no longer tell you if the team you logged in with was invalid. #5624
🔗 fix
- @evanchaoli changed the behaviour of the web to retry individual build steps that fail when a worker disappears. #5192
🔗 fix
- Added a new HTTP wrapper that returns HTTP 409 for endpoints listed in concourse/rfc#33 when the requested pipeine is archived. #5549
🔗 fix
🔗 feature
- Added tracing to the lidar component, where a single trace will be emitted for each run of the scanner and the consequential checking that happens from the checker. The traces will allow for more in depth monitoring of resource checking through describing how long each resource is taking to scan and check. #5575
🔗 fix
- @ozzywalsh added the
--teamflag to thefly unpause-pipelinecommand. #5617
v6.1.0
🔗 breaking
- This release bundles
gdnv1.19.12, which assumes the existence of the procfs mount/proc/sys/net/ipv4/tcp_keepalive_time. This mountpoint does not exist inside user namespaces in versions of the Linux kernel before v4.5, so the concourse worker process will fail in such scenarios. The most notable use case affected is docker-compose deployments (which run the concourse worker in a user namespace) on Ubuntu 16.04 LTS which is based on the LTS 4.4 Linux kernel release series. Due to this breaking change, users deploying via docker-compose must ensure they are running at least Linux 4.5 -- most have success by upgrading their operating system to Ubuntu 18.04 LTS based on Linux 4.15.
🔗 feature, breaking
-
"Have you tried logging out and logging back in?"
- Probably every concourse operator at some pointIn the old login flow, concourse used to take all your upstream third party info (think github username, teams, etc) figure out what teams you're on, and encode those into your auth token. The problem with this approach is that every time you change your team config, you need to log out and log back in. So now concourse doesn't do this anymore. Instead we use a token directly from dex, the out-of-the-box identity provider that ships with concourse.
This new flow does introduce a few additional database calls on each request, but we've added some mitigations (caching and batching) to help reduce the impact. If you're interested in the details you can check out the original issue or the follow up with some of the optimizations.
NOTE: And yes, you will need to log out and log back in after upgrading. Make sure you sync
flyusingfly sync -c <concourse-url>before logging in.
🔗 fix, breaking
-
Remove
Queryargument fromfly curlcommand.When passing curl options as
fly curl <url_path> -- <curl_options>, the first curl option is parsed as query argument incorrectly, which then causes unexpected curl behaviour. #5366With fix in #5371,
<curl_options>functions as documented and the way to add query params tofly curlis more intuitive as following:fly curl <url_path?query_params> -- <curl_options>
🔗 fix, breaking
- When looking up credentials, we now prefer pipeline scoped credential managers over global ones. #5506
🔗 fix, breaking
- In a previous release, we made the switch to using
zstdfor compressing artifacts before they get streamed all over the place. This has proved to be unreliable for all our use cases so we switched the default back togzip. We did make this configurable though so you can continue to usezstdif you so choose. #5398
🔗 feature, breaking
-
@pnsantos updated the Material Design icon library version to
5.0.45. #5397note: some icons changed names (e.g.
mdi-github-circlewas changed tomdi-github) so after this update you might have to update someicon:references.
🔗 fix, breaking
- @tjhiggins updated the flag for configuring the interval at which concourse runs its internal components.
CONCOURSE_RUNNER_INTERVAL->CONCOURSE_COMPONENT_RUNNER_INTERVAL. #5432
🔗 feature
-
Implemented the core functionality for archiving pipelines RFC #33. #5368
note: archived pipelines are neither visible in the web UI (#5370) nor in
fly pipelines.note: archiving a pipeline will nullify the pipeline configuration. If for some reason you downgrade the version of Concourse, unpausing a pipeline that was previously archived will result in a broken pipeline. To fix that, set the pipeline again.
🔗 feature
- Since switching to using dex tokens, we started using the client credentials grant type to fetch tokens for the TSA. This seemed like a good opportunity to start
bcrypting client secrets in the db. #5459
🔗 fix
- Thanks to some outstanding debugging from @agurney, we've fixed a deadlock in the notifications bus which caused the build page not to load under certain conditions. #5519
🔗 feature
- @evanchaoli added a global configuration to override the check interval for any resources that have been configured with a webhook token. #5091
🔗 feature
-
We've updated the way that hijacked containers get garbage collected
We are no longer relying on garden to clean up hijacked containers. Instead, we have implemented this functionality in concourse itself. This makes it much more portable to different container backends. #5305
🔗 feature
-
@ebilling updated the way that containers associated with failed runs get garbage collected.
Containers associated with failed runs used to sit around until a new run is executed. They now have a max lifetime (default - 120 hours), configurable via 'failed-grace-period' flag. #5431
🔗 fix
- Fix rendering pipeline previews on the dashboard on Safari. #5375
🔗 fix
- Fix pipeline tooltips being hidden behind other cards. #5377
🔗 fix
- Fix log highlighting on the one-off-build page. Previously, highlighting any log lines would cause the page to reload. #5384
🔗 fix
- Fix regression which inhibited scrolling through the build history list. #5392
🔗 feature
- We've moved the "pin comment" field in the Resource view to the top of the page (next to the currently pinned version). The comment can be edited inline.
🔗 feature
- Add loading indicator on dashboard while awaiting initial API/cache response. #5458
🔗 fix
- Allow the dashboard to recover from the "show turbulence" view if any API call fails once, but starts working afterward. This will prevent users from needing to refresh the page after closing their laptop or in the presence of network flakiness. #5496
🔗 feature
- Updated a migration that adds a column to the pipelines table. The syntax initially used is not supported by Postgres 9.5 which is still supported. Removed the unsupported syntax so users using Postgres 9.5 can run the migration. Our CI pipeline has also been updated to ensure we run our tests on Postgres 9.5. #5479
🔗 fix
- We fixed a bug where if you create a new build and then trigger a rerun build, both the builds will be stuck in pending state. #5452
🔗 feature
- We added a new flag (
CONCOURSE_CONTAINER_NETWORK_POOL) to let you configure the network range used for allocating IPs for the containers created by Concourse. This is primarily intended to support the experimental containerd worker backend. Despite the introduction of this new flag,CONCOURSE_GARDEN_NETWORK_POOLis still functional for the (stable and default) Garden worker backend. #5486
🔗 feature
- We added support for the configuration of the set of DNS resolvers to be made visibile (through
/etc/resolv.conf) to containers that Concourse creates when leveraging the experimental containerd worker backend. #5465
🔗 feature
- Added support to the experimental containerd worker backend to leverage the worker's DNS proxy to allow name resolution even in cases where the worker's set of nameservers are not reachable from the container's network namespace (for instance, when deploying Concourse workers in Docker, where the worker namerserver points to 127.0.0.11, an address that an inner container wouldn't be able to reach without the worker proxy). #5445
v5.5.11
🔗 breaking
- This release bundles
gdnv1.19.11, which assumes the existence of the procfs mount/proc/sys/net/ipv4/tcp_keepalive_time. This mountpoint does not exist inside user namespaces in versions of the Linux kernel before v4.5, so the concourse worker process will fail in such scenarios. The most notable use case affected is docker-compose deployments (which run the concourse worker in a user namespace) on Ubuntu 16.04 LTS which is based on the LTS 4.4 Linux kernel release series. Due to this breaking change, users deploying via docker-compose must ensure they are running at least Linux 4.5 -- most have success by upgrading their operating system to Ubuntu 18.04 LTS based on Linux 4.15.
🔗 feature
-
Operators can now limit the number of concurrent API requests that your web node will serve by passing a flag like
--concurrent-request-limit action:limitwhereactionis the API action name as they appear in the action matrix in our docs.If the web node is already concurrently serving the maximum number of requests allowed by the specified limit, any additional concurrent requests will be rejected with a
503 Service Unavailablestatus. If the limit is set to0, the endpoint is effectively disabled, and all requests will be rejected with a501 Not Implementedstatus.Currently the only API action that can be limited in this way is
ListAllJobs-- we considered allowing this limit on arbitrary endpoints but didn't want to enable operators to shoot themselves in the foot by limiting important internal endpoints like worker registration.It is important to note that, if you use this configuration, it is possible for super-admins to effectively deny service to non-super-admins. This is because when super-admins look at the dashboard, the API returns a huge amount of data (much more than the average user) and it can take a long time (over 30s on some clusters) to serve the request. If you have multiple super-admin dashboards open, they are pretty much constantly consuming some portion of the number of concurrent requests your web node will allow. Any other requetss, even if they are potentially cheaper for the API to service, are much more likely to be rejected because the server is overloaded by super-admins. Still, the web node will no longer crash in these scenarios, and non-super-admins will still see their dashboards, albeit without nice previews. To work around this scenario, it is important to be careful of the number of super-admin users with open dashboards. #5484
🔗 breaking
- It has long been possible to configure concourse either by passing flags to the binary, or by passing their equivalent
CONCOURSE_*environment variables. Until now we had noticed that when an environment variable is passed, the flags library we use would treat it as a "default" value -- this is a bug. We issued a PR to that library adding stricter validation for flags passed via environment variables. What this means is that operators may have been passing invalid configuration via environment variables and concourse wasn't complaining -- after this upgrade, that invalid configuration will cause the binary to fail. Hopefully it's a good prompt to fix up your manifests! #5484
🔗 feature
- Add loading indicator on dashboard while awaiting initial API response. #5427
🔗 fix
- Now the dashboard will not initiate a request for more data until the previous request finishes. The dashboard page refreshes its data every 5 seconds, and until now, it was possible (especially for admin users) for the dashboard to initiate an ever-growing number of concurrent API calls. This would unnecessarily consume browser, network and API resources, and in some cases could even overload the web node to the point that it would crash. #5472
v6.0.0
Concourse v6.0: it does things gooder.™
A whole new algorithm for deciding job inputs has been implemented which performs much better for Concourse instances that have a ton of version and build history. This algorithm works in a fundamentally different way, and in some situations will decide on inputs that differ from the previous algorithm. (More details follow in the actual release notes below.)
In the past we've done major version bumps as a ceremony to celebrate big shiny new features. This is the first time it's been done because there are backwards-incompatible changes to fundamental pipeline semantics.
We have tested this release against larger scale than we ever tried to support before, and we've been using it in our own environments for a while now. Despite all that, we still recommend that anyone using Concourse for mission-critical workflows (e.g. shipping security updates) wait for the next few releases, just in case any edge cases are found.
IMPORTANT: Please expect and prepare for some downtime when upgrading to v6.0. On our large scale deployments we have observed 10-20 minutes of downtime as the database is migrated, but this will obviously vary depending on the amount of data.
As this is a significant release with changes that may affect user workflows, we will be taking some time after this release to listen for feedback before moving on to the next big thing.
Please leave any v6.0 feedback you have, good or bad, in issue #5360!
🔗 feature, fix, breaking
-
A new algorithm for determining inputs for jobs has been implemented.
This new algorithm significantly reduces resource utilization on the
webanddbnodes, especially for long-lived and/or large-scale Concourse installations.The old algorithm used to load up all the resource versions, build inputs, and build outputs into memory then use brute-force to figure out what the next inputs would be. This method worked well enough in most cases, but with a long-lived deployment with thousands or even millions of versions or builds it would start to put a lot of strain on the
webanddbnodes just to load up the data set. In the future, we plan to collect all versions of resources, which would make this even worse.The new algorithm takes a very different approach which does not require the entire dataset to be held in memory and cuts out nearly all of the "brute force" aspect of the old algorithm. We even make use of fancy
jsonbindex functionality in Postgres; a successful build's set of resource versions are stored in a table which we can easily "intersect" in order to find matching candidates when evaluatingpassedconstraints.For a more detailed explanation of how the new algorithm works, check out the section on this in the v10 blog post.
Before we show the shiny charts showing the improved performance, let's cover the breaking change that the new algorithm needed:
-
Breaking change: for inputs with
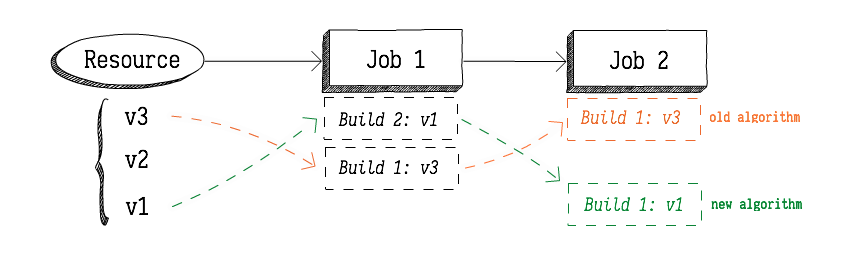
passedconstraints, the algorithm now chooses versions based on the build history of each job in thepassedconstraint, rather than version history of the input's resource.This might make more sense with an example. Let's say we have a pipeline with a resource (
Resource) that is used as an input to two jobs (Job 1andJob 2):Resourcehas three versions:v1(oldest),v2, andv3(newest).Job 1hasResourceas an unconstrained input, so it will always grab the latest version available -v3. In the scenario above, it has done this forBuild 1but then a pipeline operator pinnedv1, soBuild 2then ran withv1. So now we have bothv1andv3having "passed"Job 1, but in
reverse order.The difference between the old algorithm and the new one is which version
Job 2will use for its next build whenv1is un-pinned.With the old algorithm,
Job 2would choosev3as the input version as shown by the orange line. This is because the old algorithm would start from the latest version and then check if that version satisfies thepassedconstraints.With the new algorithm,
Job 2will instead end up withv1, as shown by the green line. This is because the new algorithm starts with the versions from the latest build of the jobs listed inpassedconstraints, searching through older builds if necessary.The resulting behavior is that pipelines now propagate versions downstream from job to job rather than working backwards from versions.
This approach to selecting versions is much more efficient because it cuts out the "brute force" aspect: by treating the
passedjobs as the source of versions, we inherently only attempt versions which already satisfy the constraints and passed through the same build together.The remaining challenge then is to find versions which satisfy all of the
passedconstraints, which the new algorithm does with a simple query utilizing ajsonbindex to perform a sort of 'set intersection' at the database level. It's pretty neato! -
Improved metrics: now that the breaking change is out of the way, let's take a look at the metrics from our large-scale test environment and see if the whole thing was worth it from an efficiency standpoint.
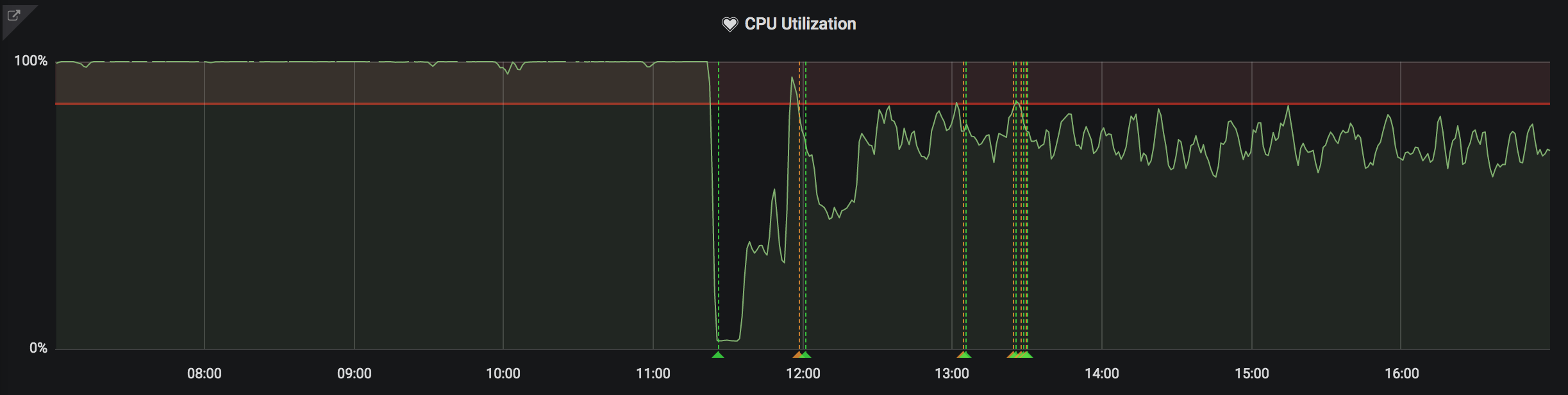
The first metric shows the database CPU utilization:
The left side shows that the CPU was completely pegged at 100% before the upgrade. This resulted in a slow web UI, slow pipeline scheduling performance, and complaints from our Concourse tenants.
The right side shows that after upgrading to v6.0 the usage dropped to ~65%. This is still pretty high, but keep in mind that we intentionally gave this environment a pretty weak database machine so we don't just keep scaling up and pretending our users have unlimited funds for beefy hardware. Anything less than 100% usage here is a win.
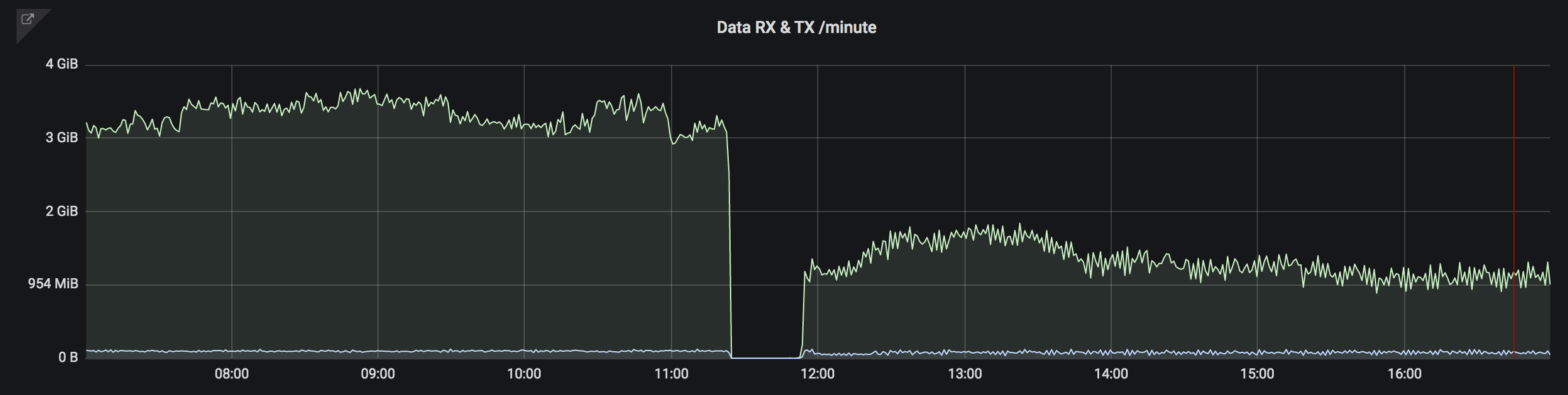
This next metric is shows database data transfer:
This shows that after upgrading to 6.0 we do a lot less data transfer from the database, because we no longer have to load the full algorithm dataset into memory.
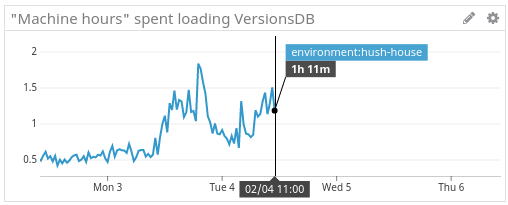
Not having to load the versions DB is also reflected in the amount of time it took just do do it as part of scheduling:
This graph shows that at the time just before the upgrade, the
webnode was spending 1 hour and 11 minutes of time per half-hour just loading the dataset. This entire step is gone, as reflected by the graph ending upon the upgrade to 6.0.Another optimization we've made is to simply not do work that doesn't need to be done. Previously Concourse would schedule every job every 10 seconds, but now it'll only schedule jobs which actually need to be scheduled.
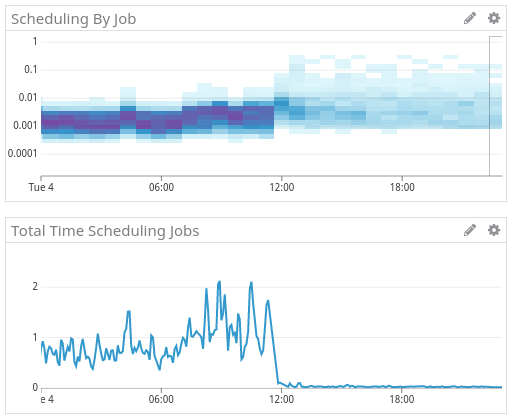
This heat-map, combined with the graph below, shows the before vs. after distribution of job scheduling time, and shows that after 6.0 there is much less time being spent scheduling jobs, freeing the
webnode to do other more important things:Note that while the per-job scheduling time has increased in duration and variance, as shown in the heat map, this is not really a fair comparison: the data for the old algorithm doesn't include all the time spent loading up the dataset, which is done once per pipeline every 10 seconds.
The fact that the new algorithm is able to schedule some jobs in the same amount of time that the older, CPU-bound, in-memory, brute-force algorithm took is actually pretty nice considering it now involves going over the network to querying the database.
Note: this new approach means that we need to carefully keep tabs on state changes so that we know when jobs need to be scheduled. If you have a job doesn't seem to be queuering new builds, and you think it should, try out the new
fly schedule-jobcommand; it's been added just in case we missed a spot. This command will mark the job as 'needs to be scheduled' and the scheduler will pick it up on the next tick. -
Migrating existing data: you may be wondering how the upgrade's data migration works with such a huge change to how the scheduler uses data.
The answer is: very carefully.
If we were to do an in-place migration of all of the data to the new format used by the algorithm, the upgrade would take forever. To give you an idea of how long, even just adding a column to the
buildstable in our environment took about 16 minutes. Now imagine that multiplied by all of the inputs and outputs for each build.So instead of doing it all at once in a migration on startup, the algorithm will lazily migrate data for builds as it needs to. Overall, this should result in very little work to do as most jobs will have a satisfiable set of inputs without having to go too far back in the history of upstream jobs.
-
Bonus feature: along with the n...
v5.2.8
🔗 fix
- Fix an edge case of CVE-2018-15798 where redirect URI during login flow could be embedded with a malicious host.
🔗 fix
- Added a flag,
--disable-list-all-jobs. When this flag is passed, the /api/v1/jobs endpoint (which is known to have performance issues) will always return an empty JSON array instead of making complex and expensive database operations. The most significant end-user impact of this change should be that the dashboard will no longer display pipeline previews. #5340
v5.8.1
🔗 fix
- Bump golang.org/x/crypto module from
v0.0.0-20191119213627-4f8c1d86b1batov0.0.0-20200220183623-bac4c82f6975to address vulnerability in ssh package.
🔗 fix
- Fix an edge case of CVE-2018-15798 where redirect URI during login flow could be embedded with a malicious host.