Rework kernel and session architecture #7252
Conversation
|
Thanks for making a pull request to JupyterLab! To try out this branch on binder, follow this link: |
078896a
to
b893d5c
Compare
|
CC @kevin-bates and @Zsailer. If you have time, please look over the rough architecture overview and see how that meshes with the server kernel work you mention in jupyter-server/jupyter_server#90 (comment)? Are the two efforts orthogonal enough to proceed independently? I think basically yes, but would love to get your input. |
|
Yes, I agree, these areas are largely orthogonal. I'd really like to see a "session" represent a "client" to which there can be multiple kernels (notebooks, terminals, etc.) associated and their respective lifecycles independent of each other. In the standard scenario, there would be one session instance in the "server", but when used in multi-tenant situations, there would be multiple. I'd also like to see this notion (of session) introduced into content services as well. Of course, this would likely require changes in the REST API and I'm not sure we'd be at liberty to perform such changes. For example, if each request had a session "id", oh the places we could go! |
FYI, for JupyterLab, there can be many clients up on the page at once, even for a single user. For example, a notebook and console in the same jlab session connected to the same kernel use different client ids. This is so it is easy to distinguish between messages meant for the notebook vs messages meant for the console. Message headers have both a session (i.e., client session for messages to the kernel) field and a username field. I see the session field as being finer-grained than the user field. |
|
Ok - based on your last comment I guess I should have said "jlab session" instead of "client". I wanted to include other applications that are purely REST based and its not necessarily a human making those calls. So I guess what I'm after is the ability for the server to distinguish between different client-application instances. This would essentially equate to a "server session", that applications create before anything else and include a handle to in each request. |
I would love to go one step further and have a websocket-based server api that mirrors what the current rest api does, but allows the server to also push information to the browser. Right now we have to regularly poll the api for file, kernelspec, session, and kernel changes. |
|
Thanks for handling this @jasongrout . I made a few points below from reading the README paragraph you linked. On re-reading them, I realize they are not very constructive, but I'm struggling myself to understand some of these points, so I find it hard to come with suggestions for resolution. Not all of them need to be answered, they are meant as clues as to what points I got confused about while reading it :) Looking at the readme, I have the following thoughts:
Other points:
|
@vidartf, thank you very much for this feedback and these questions. This is exactly the sort of deeper conversation that is needed to both help me clarify my own understanding of the issues and to help write clear documentation about what is still a confusing and complicated part of jlab. I'll dive more into the details later, but just wanted to tell you first that I really appreciate you engaging on a deep level. |
I think of it sort of like a model/view analog. The user usually is working with the connection object. They may want to change something in the model, for which there are convenience methods in the view, or may want some information from the model. The connection object is also listening to a model disposed signal, so that it knows when to dispose itself.
"Typically" here means that it really should be only one kernel connection, but perhaps it is not completely enforced so people can violate that if they know what they are doing. Should we enforce it?
As it stands now, the notebook server automatically deletes a session when the kernel dies. The upstream PR makes it possible for a session to exist without a kernel. This would allow a user to shut down a kernel, then start a new one, but keep the same session open, for example.
It is an object that matches the client's lifecycle which can connect to various sessions over the client's life. For example, imagine a variable explorer client. A user may want to point that variable explorer to various sessions over the lifetime of its existence. The client session allows the variable explorer to have a single object that represents whatever the current session it is pointed to, with proxied signals from the corresponding kernel for convenience. Imagine a plugin that talks to the variable explorer and shows the variable explorer's kernel status. Rather than having this plugin disconnect and connect every time the variable explorer's session changes, it can just hook up to the kernel status signal proxied in the client session, which just forwards emissions from whatever the current kernel is.
I'll presume we are working totally inside JupyterLab. And I'm making up the API below. Say client A is connected to session DATASESSION, which points to kernel DATAKERNEL. I imagine this technically looks like:
To connect client B to the same kernel as client A, do something like Now in your first situation, client A is closed, and its client session, session connection, and kernel connection are all disposed. Client B stays connected to the kernel and the session. In your second situation, either client A or B tells its session connection to change the kernel: |
f6c25a6
to
eb63603
Compare
|
@jasongrout thanks for the detailed reply. A lot of this became a lot clearer. Some comments:
It would be nice if you could share a little on what are intended branching points, and what are not? What pros / cons exist for branching at various points. |
|
Note: For the last point, it would both be good to get a "this is how it currently is" and a "this is why it is like this". E.g.:
|
|
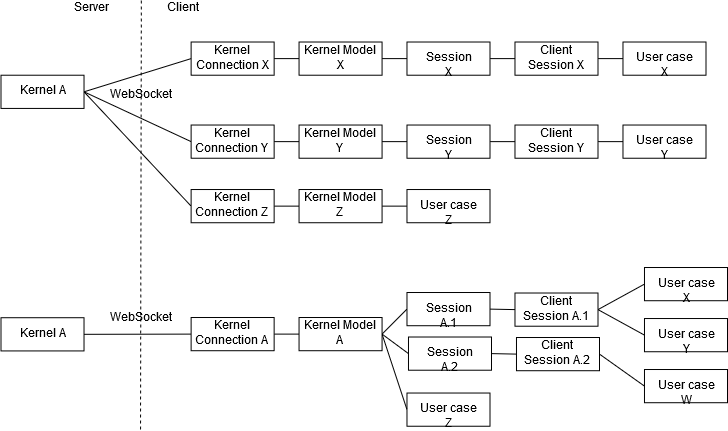
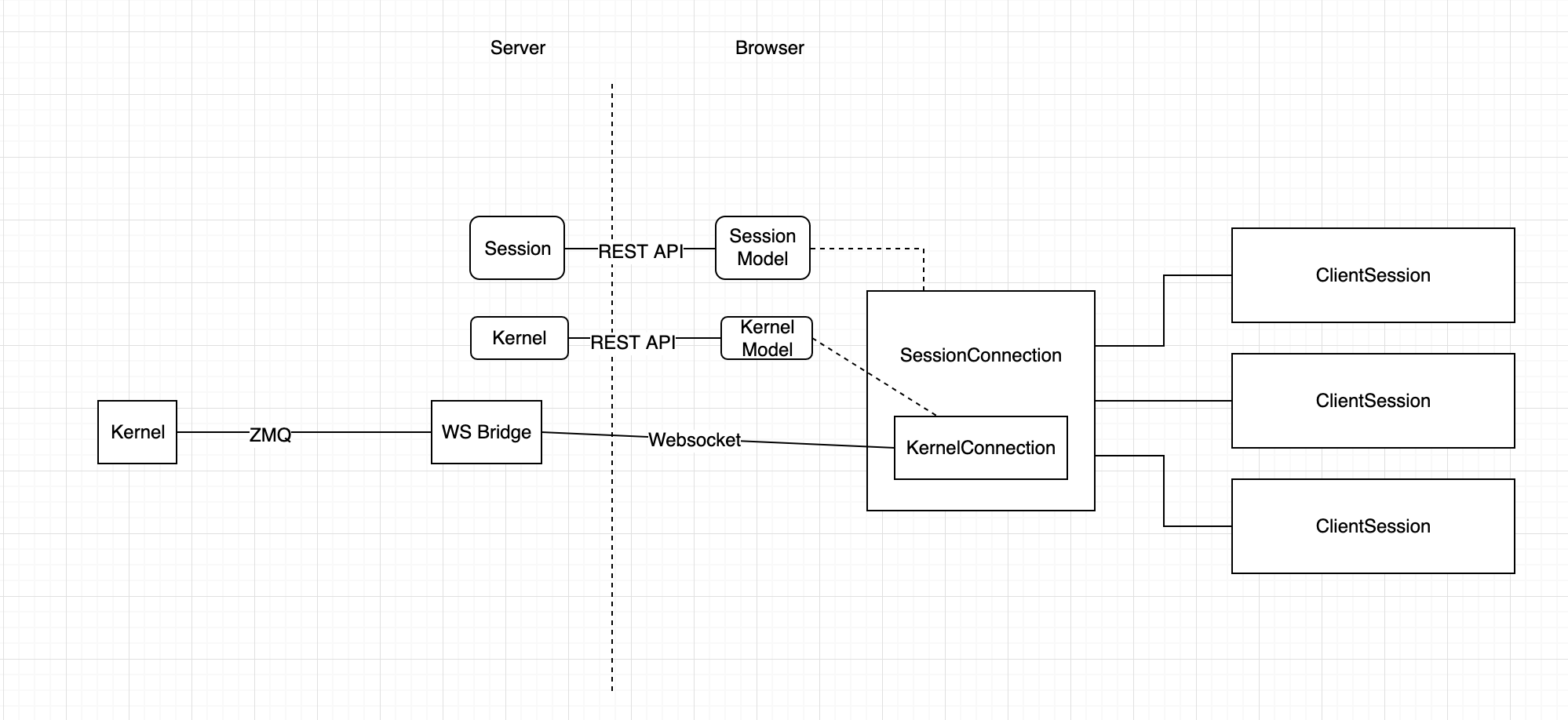
This is still a work-in-progress, and my ideas in my head are clarifying also as I explore implementations. Here is a rough sketch of my mental model at this point:
|
|
@jasongrout You have no idea how much that figure helped in understanding things 😅 Once the dust settles, we should put a cleaned up version of that in the dev docs! From that figure, I will update my mental model of possible branching points to this:
Creating a KernelConnection / SessionConnection directly seem to be the way to go if your use is coupled directly to the life of a single kernel. After a bit of digging, I figured out that a session model is basically a kernel model + a path and type. It ensures that a single path is linked to a single kernel at a time (the mapping can be changed by anyone at any time though). Given this, I'm wondering if a "ClientKernel" should exist? I.e. a way for multiple consumers to connect to a replaceable kernel at the same time, but without the need or access to an associated path. If there is a good reason for there not to be one? How to have multiple agents share a Comm seems like a rather though nut to crack, and I'm not entirely sure it can be done without breaking some fundamental assumptions. It would be interesting to dig a little here, but I wouldn't want to do it alone. |
|
@jasongrout A picture is worth a thousands words. I confess I have not read all the comments here... what are the usescase(s) we support with this? I feel flavors of realtime communication, but I may be wrong. |
|
I also realized that mental model wasn't quite accurate. Every client needs a separate session/kernel connection, since the client id is set in that connection object. So it's more like:
|

Yes, technically, but I think we will encourage people to open sessions rather than raw kernels, as sessions allow someone to persist connections more easily.
You need to create a kernel model in that case (i.e., create a kernel via the rest api), then open a websocket to it by creating a kernel connection.
Yes. Create a session (or get an existing session) and then create a session connection.
Yes.
Yes - you can just use the rest api to do so.
Yes, again you can just use the rest api to do so. One more thing in the mix. There is a KernelManager and a SessionManager. Since we don't have the server pushing updates to us about kernels and sessions, the managers poll the server and maintain state, like what kernels/sessions are currently running on the server and a list of the connection objects. So really, I imagine most people will interact with the SessionManager to query sessions, launch/shutdown sessions, switch session kernels, and create session connections.
Those consumers would lose that connection with each other once the kernel died and had to be manually started again. |
Multiple clients connected to the same kernel, in a way that preserves that connection with a common kernel across kernel restarts and kernel changes and page refreshes. |
So, if I read this correctly, comm handlers can (should?) register themselves once per KernelConnection? But it won't work properly until the Comm echo messages are integrated into the spec? |
|
Another issue that has come up is that the UI for kernel selection was part
of some of these classes. I think the UI components related to the kernel
should be independent of the core classes.
…On Tue, Oct 8, 2019 at 6:11 AM Vidar Tonaas Fauske ***@***.***> wrote:
Every client needs a separate session/kernel connection, since the client
id is set in that connection object. So it's more like:
So, if I read this correctly, comm handlers *can* (should?) register
themselves once per KernelConnection? But it won't work properly until the
Comm echo messages are integrated into the spec?
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
<#7252?email_source=notifications&email_token=AAAGXUFLGV6FHM7KGLOLT3LQNSBJTA5CNFSM4IY5ZQ72YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEAUDLGI#issuecomment-539506073>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AAAGXUEOTOSQH2GJTBIRBW3QNSBJTANCNFSM4IY5ZQ7Q>
.
--
Brian E. Granger
Principal Technical Program Manager, AWS AI Platform (brgrange@amazon.com)
On Leave - Professor of Physics and Data Science, Cal Poly
@ellisonbg on GitHub
|
I think only one kernel connection to any given kernel at any given time should be enabled for comms. Tracking this state to do this by default is now in the kernel manager class (https://github.com/jupyterlab/jupyterlab/pull/7252/files#diff-34bbd4d22568900ea9a774de0b7ea8ecR96-R104 right now). If you don't use the kernel manager class, it's up to you to manage that state and enable comms on at most one kernel connection. Two of the problems I've identified is that if there is a kernel connection that does handle comms and a comm handler is not registered, it ends up closing the comms for everyone. That could be solved by making sure that a comm handler is registered for every kernel connection (that handles comms), indeed. The other problem with multiple handlers, as you mention, is the comm echo message issue, which would be solved best by a spec change. |
Note that this will not solve the issue if one of the other clients is not in the same browser context (e..g a different tab, a different browser, a different server process, or on a different computer). This isn't really supported well anyways because of the lack of comm echo, but should ideally be supported. While it doesn't need to be solved in this refactor, it would be nice if that could be supported in the future without another full refactor. |
The core services/ package does not have any UI that I know of. The ClientSession class does have some UI (for choosing kernels, etc.), but it is part of jlab in the apputils package as well. |
Would it make sense to move the non-UI parts of |
|
Nice, thanks! Does this need a rebase now (sorry I thought you were done pushing)? |
No, I think it doesn't need a rebase (well, I'd dread doing a rebase, anyway). I've merged from master several times recently and took care to resolve conflicts.
I was, then saw we had that familiar windows timeout on the last run, so thought I'd take a look at it again. |
About gave me a heart attack there :) |
|
Ha, I couldn't get one of the tests to restart. The Windows JS test is just about done. I've been reviewing and testing this locally. I'll merge once the test passes. |
|
Shucks, |
|
Just looking at that. Looks like that test actually doesn't need to be async. It did pass on linux though. Change and rerun, or merge and I'll fix it to not be async in the followup terminal refactor I'm doing now? |
|
Hmm, that test failed on two of the attempts, and two different tests failed on the other: I'll kick it and see what we get. |
|
It failed in the |
|
Yet another windows async error: Of course, it did pass several times before, and it reliably passes on linux. |
|
Failures from the last run: |
|
Well, good news is there were no explicit failures, just timeouts. I'm going to run the tests manually on windows locally to see as well. |
|
Should we just up it to 100000ms across the board? |
|
For archiving, one more failure:
Sure? |
I doubled it to 120s. |
|
Ha, looks like it was just slower now, merging! |
| @@ -69,11 +69,13 @@ | |||
| "remove:package": "node buildutils/lib/remove-package.js", | |||
| "remove:sibling": "node buildutils/lib/remove-package.js", | |||
| "test": "lerna run test --scope \"@jupyterlab/test-*\" --concurrency 1 --stream", | |||
| "test:all": "lerna run test --scope \"@jupyterlab/test-*\" --concurrency 1 --stream --no-bail", | |||
| const parent = widget; | ||
| const editor = anchor.promptCell?.editor; | ||
| const session = anchor.sessionContext.session; | ||
| // TODO: CompletionConnector assumes editor and session are not null |
There was a problem hiding this comment.
Is this TODO for this PR, or for the Future?
There was a problem hiding this comment.
future - it's outside the scope of this PR. I can open an issue, or perhaps this is taken into account in your PR?
| handler.editor = editor; | ||
| // TODO: CompletionConnector assumes editor and session are not null |
| const parent = panel; | ||
| const editor = panel.content.activeCell?.editor ?? null; | ||
| const session = panel.sessionContext.session; | ||
| // TODO: CompletionConnector assumes editor and session are not null |
| handler.editor = editor; | ||
| // TODO: CompletionConnector assumes editor and session are not null |
References
This follows up on #4724, continuing to rework the kernel and session architecture in JupyterLab.
For the session persistence work, this builds on jupyter/notebook#4874
Code changes
Revamp the services package, refactoring how kernels, sessions, connections, and session contexts work.
User-facing changes
Backwards-incompatible changes
Many, primarily in the services package.