JUPYTER_COLUMNS and JUPYTER_LINES have no effect on databricks notebook
#1729
Assignees

Labels
Issue: Bug Report 🐞
Bug that needs to be fixed
Comments
|
This should provide more hints, Rich does not recognise the console as a "Jupyter" environment. Created an issue in |
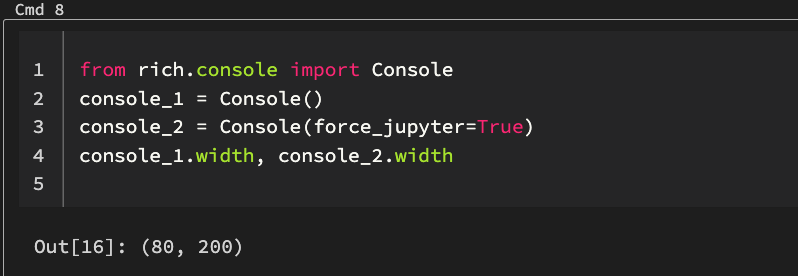
|
Not sure if super helpful, but I rand the following in a blank Databricks notebook: import os
[{"env_var":k, "char_count":len(v), "example":v[:30] } for k,v in os.environ.items()]
Reveal to see JSON dump, 'example' key is only first 30 chars[
{
"env_var": "PATH",
"char_count": 116,
"example": "/usr/local/nvidia/bin:/databri"
},
{
"env_var": "container",
"char_count": 3,
"example": "lxc"
},
{
"env_var": "DATABRICKS_CLUSTER_LIBS_R_ROOT_DIR",
"char_count": 1,
"example": "r"
},
{
"env_var": "DEFAULT_DATABRICKS_ROOT_VIRTUALENV_ENV",
"char_count": 19,
"example": "/databricks/python3"
},
{
"env_var": "SPARK_ENV_LOADED",
"char_count": 1,
"example": "1"
},
{
"env_var": "JAVA_OPTS",
"char_count": 119747,
"example": " -Djava.io.tmpdir=/local_disk0"
},
{
"env_var": "R_LIBS",
"char_count": 71,
"example": "/databricks/spark/R/lib:/local"
},
{
"env_var": "SUDO_USER",
"char_count": 4,
"example": "root"
},
{
"env_var": "MAIL",
"char_count": 14,
"example": "/var/mail/root"
},
{
"env_var": "DATABRICKS_ROOT_VIRTUALENV_ENV",
"char_count": 19,
"example": "/databricks/python3"
},
{
"env_var": "SCALA_VERSION",
"char_count": 4,
"example": "2.10"
},
{
"env_var": "ENABLE_IPTABLES",
"char_count": 5,
"example": "false"
},
{
"env_var": "USERNAME",
"char_count": 4,
"example": "root"
},
{
"env_var": "MLFLOW_TRACKING_URI",
"char_count": 10,
"example": "databricks"
},
{
"env_var": "LOGNAME",
"char_count": 4,
"example": "root"
},
{
"env_var": "DATABRICKS_RUNTIME_VERSION",
"char_count": 4,
"example": "10.4"
},
{
"env_var": "PWD",
"char_count": 18,
"example": "/databricks/driver"
},
{
"env_var": "PTY_LIB_FOLDER",
"char_count": 15,
"example": "/usr/lib/libpty"
},
{
"env_var": "PYTHONPATH",
"char_count": 190,
"example": "/databricks/spark/python:/data"
},
{
"env_var": "SHELL",
"char_count": 9,
"example": "/bin/bash"
},
{
"env_var": "DB_HOME",
"char_count": 11,
"example": "/databricks"
},
{
"env_var": "KOALAS_USAGE_LOGGER",
"char_count": 38,
"example": "pyspark.databricks.koalas.usag"
},
{
"env_var": "MPLBACKEND",
"char_count": 3,
"example": "AGG"
},
{
"env_var": "HIVE_HOME",
"char_count": 27,
"example": "/home/ubuntu/hive-0.9.0-bin"
},
{
"env_var": "OLDPWD",
"char_count": 21,
"example": "/databricks/chauffeur"
},
{
"env_var": "DATABRICKS_CLUSTER_LIBS_PYTHON_ROOT_DIR",
"char_count": 6,
"example": "python"
},
{
"env_var": "SPARK_CONF_DIR",
"char_count": 22,
"example": "/databricks/spark/conf"
},
{
"env_var": "VIRTUAL_ENV",
"char_count": 19,
"example": "/databricks/python3"
},
{
"env_var": "MLFLOW_CONDA_HOME",
"char_count": 17,
"example": "/databricks/conda"
},
{
"env_var": "SHLVL",
"char_count": 1,
"example": "0"
},
{
"env_var": "MASTER",
"char_count": 8,
"example": "local[8]"
},
{
"env_var": "JAVA_HOME",
"char_count": 32,
"example": "/usr/lib/jvm/zulu8-ca-amd64/jr"
},
{
"env_var": "TERM",
"char_count": 11,
"example": "xterm-color"
},
{
"env_var": "LANG",
"char_count": 7,
"example": "C.UTF-8"
},
{
"env_var": "SPARK_LOCAL_IP",
"char_count": 14,
"example": "10.172.178.130"
},
{
"env_var": "CLUSTER_DB_HOME",
"char_count": 11,
"example": "/databricks"
},
{
"env_var": "PYARROW_IGNORE_TIMEZONE",
"char_count": 1,
"example": "1"
},
{
"env_var": "SPARK_SCALA_VERSION",
"char_count": 4,
"example": "2.12"
},
{
"env_var": "PYSPARK_PYTHON",
"char_count": 29,
"example": "/databricks/python/bin/python"
},
{
"env_var": "PINNED_THREAD_MODE",
"char_count": 5,
"example": "false"
},
{
"env_var": "DRIVER_PID_FILE",
"char_count": 22,
"example": "/tmp/driver-daemon.pid"
},
{
"env_var": "SUDO_GID",
"char_count": 1,
"example": "0"
},
{
"env_var": "SPARK_HOME",
"char_count": 17,
"example": "/databricks/spark"
},
{
"env_var": "SPARK_LOCAL_DIRS",
"char_count": 12,
"example": "/local_disk0"
},
{
"env_var": "MLFLOW_PYTHON_EXECUTABLE",
"char_count": 42,
"example": "/databricks/spark/scripts/mlfl"
},
{
"env_var": "SPARK_WORKER_MEMORY",
"char_count": 6,
"example": "10348m"
},
{
"env_var": "SUDO_UID",
"char_count": 1,
"example": "0"
},
{
"env_var": "PYTHONHASHSEED",
"char_count": 1,
"example": "0"
},
{
"env_var": "_",
"char_count": 41,
"example": "/usr/lib/jvm/zulu8-ca-amd64/jr"
},
{
"env_var": "PYSPARK_GATEWAY_SECRET",
"char_count": 64,
"example": "..."
},
{
"env_var": "DATABRICKS_CLUSTER_LIBS_ROOT_DIR",
"char_count": 17,
"example": "cluster_libraries"
},
{
"env_var": "USER",
"char_count": 4,
"example": "root"
},
{
"env_var": "CLASSPATH",
"char_count": 116953,
"example": "/databricks/spark/dbconf/jets3"
},
{
"env_var": "SUDO_COMMAND",
"char_count": 220,
"example": "/usr/bin/lxc-attach -n 0727-12"
},
{
"env_var": "PYSPARK_GATEWAY_PORT",
"char_count": 5,
"example": "42135"
},
{
"env_var": "DATABRICKS_LIBS_NFS_ROOT_DIR",
"char_count": 14,
"example": ".ephemeral_nfs"
},
{
"env_var": "PIP_NO_INPUT",
"char_count": 1,
"example": "1"
},
{
"env_var": "SPARK_PUBLIC_DNS",
"char_count": 14,
"example": "10.172.178.130"
},
{
"env_var": "DATABRICKS_LIBS_NFS_ROOT_PATH",
"char_count": 27,
"example": "/local_disk0/.ephemeral_nfs"
},
{
"env_var": "HOME",
"char_count": 5,
"example": "/root"
},
{
"env_var": "SPARK_AUTH_SOCKET_TIMEOUT",
"char_count": 2,
"example": "15"
},
{
"env_var": "SPARK_BUFFER_SIZE",
"char_count": 5,
"example": "65536"
},
{
"env_var": "CLICOLOR",
"char_count": 1,
"example": "1"
},
{
"env_var": "PAGER",
"char_count": 3,
"example": "cat"
},
{
"env_var": "GIT_PAGER",
"char_count": 3,
"example": "cat"
}
]
|
|
Current workaround is to set |
|
Closing this since it's fixed in Textualize/rich#2424. |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Description
Short description of the problem here.
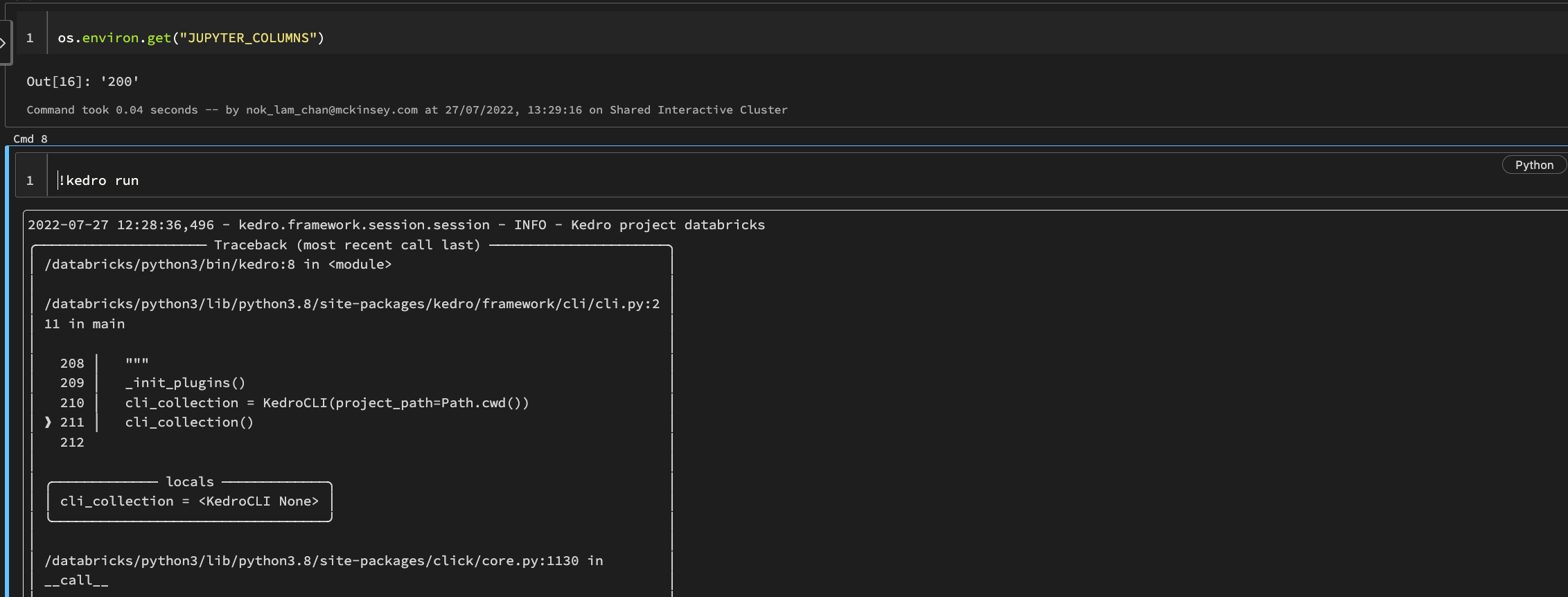
The
JUPYTER_LINESandJUPYTER_COLUMNSconfigurations does not change databricks notebook output. It causes problem especially with Spark since the log are verbose and users need to scroll a lot to get to the bottom error message.Context
How has this bug affected you? What were you trying to accomplish?
Steps to Reproduce
%env JUPYTER_COLUMNS=200and bothAdvance Optionto set environment variable in Cluster settingskedro runJUPYTER_COLUMNSconfiguration.Expected Result
Log should become wide
Actual Result
Log width unchanged
Your Environment
Include as many relevant details about the environment in which you experienced the bug:
pip show kedroorkedro -V): 0.18.2python -V): 3.8.5The text was updated successfully, but these errors were encountered: