English | 中文页面
Data is the key to the unprecedented development of large multi-modal models such as SORA. How to obtain and process data efficiently and scientifically faces new challenges! DJ-SORA aims to create a series of large-scale, high-quality open-source multi-modal data sets to assist the open-source community in data understanding and model training.
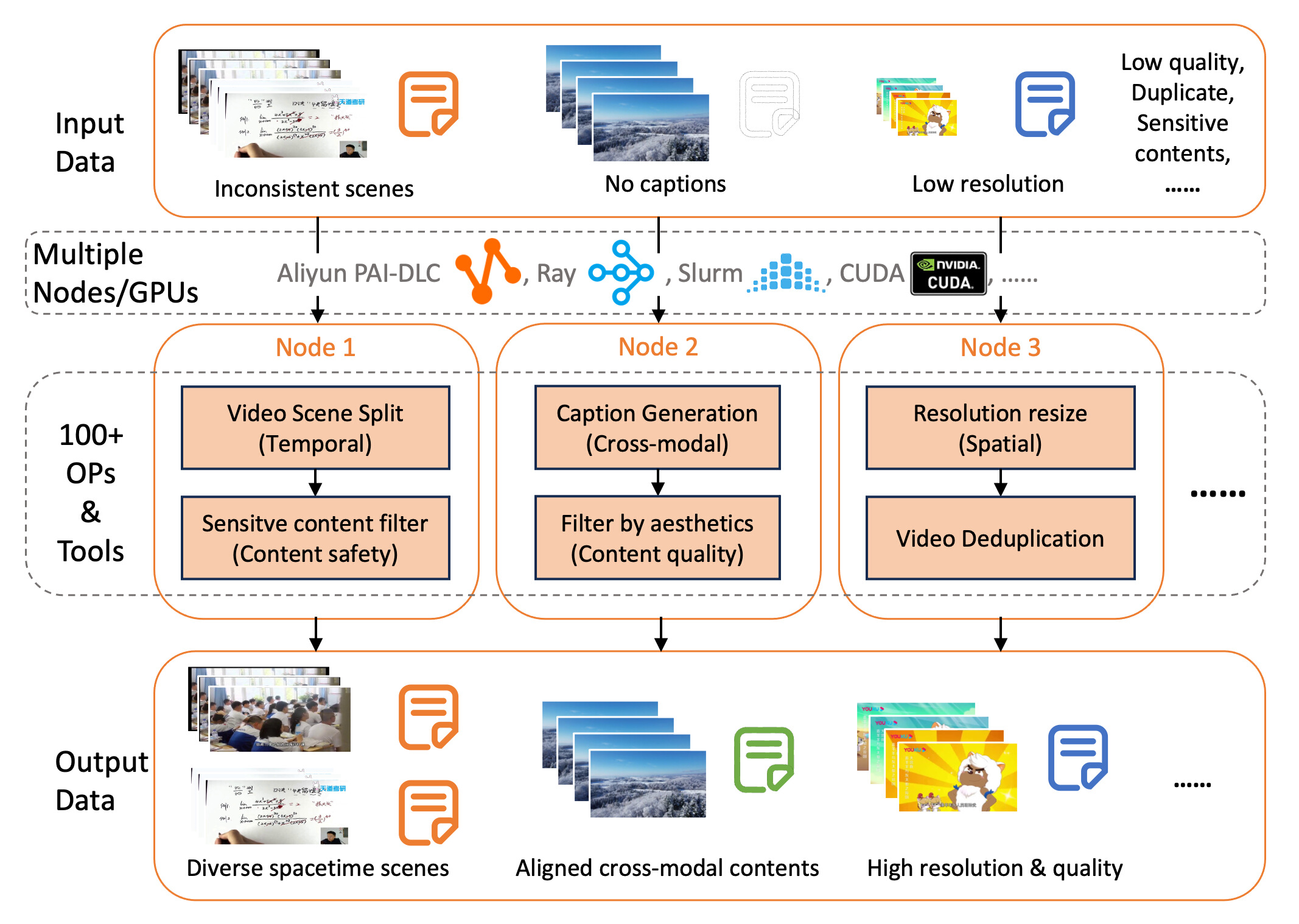
DJ-SORA is based on Data-Juicer (including hundreds of dedicated video, image, audio, text and other multi-modal data processing operators and tools) to form a series of systematic and reusable Multimodal "data recipes" for analyzing, cleaning, and generating large-scale, high-quality multimodal data.
This project is being actively updated and maintained. We eagerly invite you to participate and jointly create a more open and higher-quality multi-modal data ecosystem to unleash the unlimited potential of large models!
- SORA only briefly mentions using DALLE-3 to generate captions and can handle varying durations, resolutions and aspect ratios.
- High-quality large-scale fine-grained data helps to densify data points, aiding models to better learn the conditional mapping of "text -> spacetime token", and solve a series of existing challenges in text-to-video models:
- Smoothness of visual flow, with some generated videos exhibiting dropped frames and static states.
- Text comprehension and fine-grained detail, where the produced results have a low match with the given prompts.
- Generated content showing distortions and violations of physical laws, especially when entities are in motion.
- Short video content, mostly around ~10 seconds, with little to no significant changes in scenes or backdrops.
- Support high-performance loading and processing of video data
- Basic Operators (video spatio-temporal dimension)
- Advanced Operators (fine-grained modal matching and data generation)
- Advanced Operators (Video Content)
- DJ-SORA Data Recipes and Datasets
- DJ-SORA Data Validation and Model Training
- [✅] Parallelize data loading and storing:
- [✅] lazy load with pyAV and ffmpeg
- [✅] Multi-modal data path signature
- [✅] Parallelization operator processing:
- [✅] Support single machine multicore running
- [✅] GPU utilization
- [✅] Ray based multi-machine distributed running
- [✅] Aliyun PAI-DLC & Slurm based multi-machine distributed running
- [✅] Distributed scheduling optimization (OP-aware, automated load balancing) --> Aliyun PAI-DLC
- [WIP] Distributed storage optimization
- Towards Data Quality
- [✅] video_resolution_filter (targeted resolution)
- [✅] video_aspect_ratio_filter (targeted aspect ratio)
- [✅] video_duration_filter (targeted) duration)
- [✅] video_motion_score_filter (video continuity dimension, calculating optical flow and removing statics and extreme dynamics)
- [✅] video_ocr_area_ratio_filter (remove samples with text areas that are too large)
- Towards Data Diversity & Quantity
- [✅] video_resize_resolution_mapper (enhancement in resolution dimension)
- [✅] video_resize_aspect_ratio_mapper (enhancement in aspect ratio dimension)
- [✅] video_split_by_duration_mapper (enhancement in time dimension)
- [✅] video_split_by_key_frame_mapper (enhancement in time dimension with key information focus)
- [✅] video_split_by_scene_mapper (enhancement in time dimension with scene continuity focus)
- Towards Data Quality
- [✅] video_frames_text_similarity_filter (enhancement in the spatiotemporal consistency dimension, calculating the matching score of key/specified frames and text)
- Towards Diversity & Quantity
- [✅] video_tagging_from_frames_mapper (with lightweight image-to-text models, spatial summary information from dense frames)
- [✅] video_captioning_from_frames_mapper (heavier image-to-text models, generating more detailed spatial information from fewer frames)
- [✅] video_tagging_from_audio_mapper (introducing audio classification/category and other meta information)
- [✅] video_captioning_from_audio_mapper (incorporating voice/dialogue information; AudioCaption for environmental and global context)
- [✅] video_captioning_from_video_mapper (video-to-text model, generating spacetime information from continuous frames)
- [✅] video_captioning_from_summarizer_mapper (combining the above sub-abilities, using pure text large models for denoising and summarizing different types of caption information)
- [WIP] video_interleaved_mapper (enhancement in ICL, temporal, and cross-modal dimensions),
interleaved_modesinclude:- text_image_interleaved (placing captions and frames of the same video in temporal order)
- text_audio_interleaved (placing ASR text and frames of the same video in temporal order)
- text_image_audio_interleaved (alternating stitching of the above two types)
- [✅] video_deduplicator (comparing hash values to deduplicate at the file sample level)
- [✅] video_aesthetic_filter (performing aesthetic scoring filters after frame decomposition)
- [✅] Compatibility with existing ffmpeg video commands
- audio_ffmpeg_wrapped_mapper
- video_ffmpeg_wrapped_mapper
- [✅] Video content compliance and privacy protection operators (image, text, audio):
- [✅] Mosaic
- [✅] Copyright watermark
- [✅] Face blurring
- [✅] Violence and Adult Content
- [TODO] (Beyond Interpolation) Enhancing data authenticity and density
- Collisions, lighting, gravity, 3D, scene and phase transitions, depth of field, etc.
- Filter-type operators: whether captions describe authenticity, relevance scoring/correctness of that description
- Mapper-type operators: enhance textual descriptions of physical phenomena in video data
- ...
- Support for unified loading and conversion of representative datasets (other-data <-> dj-data), facilitating DJ operator processing and dataset expansion.
- [✅] Video-ChatGPT: 100K video-instruction data:
{<question, answer, youtube_id>} - [✅] Youku-mPLUG-CN: 36TB video-caption data:
{<caption, video_id>} - [✅] InternVid: 234M data sample:
{<caption, youtube_id, start/end_time>} - [✅] MSR-VTT: 10K video-caption data:
{<caption, video_id>} - [WIP] ModelScope's datasets integration
- VideoInstruct-100K, Panda70M, ......
- [✅] Video-ChatGPT: 100K video-instruction data:
- Large-scale high-quality DJ-SORA dataset
- [✅] (Data sandbox) Building and optimizing multimodal data recipes with DJ-video operators (which are also being continuously extended and improved).
- [WIP] Continuous expansion of data sources: open-datasets, Youku, web, ...
- [WIP] Large-scale analysis, cleaning, and generation of high-quality multimodal datasets based on DJ recipes (OpenVideos, ...)
- [WIP] Large-scale generation of 3DPatch datasets based on DJ recipes.
- ...
- [WIP] (DJ-Bench101) Exploring and refining the collaborative development of multimodal data and model, establishing benchmarks and insights.
- [WIP] Integration of SORA-like model training pipelines
- EasyAnimate
- ...
- [✅] (Model-Data sandbox) With relatively small models and the DJ-SORA dataset, exploring low-cost, transferable, and instructive data-model co-design, configurations and checkpoints.
- [WIP] Training SORA-like models with DJ-SORA data on larger scales and in more scenarios to improve model performance.
- ...