Fast way to pass complex structs Rust -> JS #1502
Comments
Yes, creating the Object in WASM needs to be done with JavaScript, but the call overhead is smaller. |
|
So are you suggesting Rust code which is currently running as native via NAPI should instead run as WASM? And the advantage is that JS and WASM can call each other repeatedly without a huge overhead? What I've been working on is largely premised on (a) the code which generates the structs in Rust needs to run at native speed and (b) therefore you need to minimize calls between the two "worlds". |
No, I'm wondering if we can have a WASM layer to be the bridge of Rust <=> JavaScript. We can pass the serialized buffer to WASM directly(not sure if possible), and the WASM invokes JavaScript to serialize it into JavaScript Objects. |
In this way, you need to copy the rust struct serialized buffer to wasm memory first since wasm can not access host memory directly. As the title says it is "complex struct", I'm afraid the memory allocation and copying overhead (maybe malloc/free or some address calculation in wasm) can not be ignored. |
|
I assume Rust to WASM would have to go via JS. But I think overhead could be largely avoided if it went like this:
i.e. WASM owns the memory, but JS and Rust can both read and write to it. No memory copies. If buffer runs out of space, Rust would have to call back into JS to call
However... all that said, I'm not sure a WASM layer would bring that much benefit. If the deserializer on JS side is fairly simple, avoids polymorphism, and only requires 32-bit SMIs (which are stored on stack in V8) for memory offset calculations, I imagine V8 would optimize the JS to something which runs as fast as WASM anyway. I've not tested that assumption, but in the SWC JS deserializer, I did try rewriting all arithmetic operations as ASM.js functions (poor man's WASM), and found it produced no performance benefit. What I did find is a significant performance-killer is strings. Node's |
|
Take a look at nodejs/node#45905 where we are discussing some new napi APIs in node/v8 to improve performance of object creation. |
|
@devongovett Interesting. Looks like there's potential for huge improvement there. However, even with the most optimized method, if I've read it right, there's still a 20% performance gap vs creating objects in JS. Do you believe that gap can ever be closed? If you have any thoughts on the rest of what I've outlined above, would be very interested to hear them. In particular, I feel the arenas approach has potential. |
|
The problem with approaches like that is that you still eventually need JS values on the other side. Maybe in some simple cases reading directly from some native heap is ok (you can do this with Buffers today), but in the general case you'd want real JS objects, strings, etc. So then you'd have to have a layer written in JS to read out of the memory and essentially "deserialize" to JS by using TextDecoder, creating objects etc which is basically what napi is doing already. In my experience with napi-wasm, this is already slower than what we have today. I think the best opportunity for speeding this up is speeding up the v8 API itself. As shown in that issue, there are some good possibilities already and once we present to the v8 team they may have additional ideas. Aside from object creation, the overhead of native function calls can be reduced with the v8 fast call api, but napi doesn't expose that either. Also an API for string interning could be exposed by napi. I do think there is more room for improvement in napi itself overall. |
|
@devongovett Sorry for very slow response. It's been a busy month at work. I agree that improvements in NAPI itself is the ideal. If NAPI had access to the most efficient V8 calls, I can't see a logical reason it couldn't match speed of object creation in JS. And of course that'd be far more ergonomic than serialization-deserialization. However, a couple of things: NAPI's current speedYou say that serialization+deser would be "already slower than what we have today". My first step when trying to improve SWC's parse speed (swc-project/swc#2175) was to do a rough benchmark of different approaches, and creation of objects via
So, unless I was completely misusing the API (very possible, that was the first Rust I'd ever written), it suggested a different conclusion to yours. NB the benchmarks later in that issue reflect the total cost end-to-end - serialization to ArrayBuffer on Rust side (with RKYV) and deserialization into JS objects on JS side. Are you seeing a very different picture? Avoidable deserializationIn some use cases, you don't necessarily need to deserialize everything to JS objects. Or at least not all at once. A visitor pattern is one example. e.g. Lighting CSS: visitor: {
Length(length) {
return {
unit: length.unit,
value: length * 2
}
}
}If there was a constraint that the object passed to the visitor function must not leave that function, then Of course, that constraint may not be workable for Lightning CSS, but it might be in some applications. |
|
Any movement on this? It would be great to see a nice way to not need to serialise to strings to move back and forward. Is there potentially a list of requests for the Node team to get added to the NAPI? |
@Brooooooklyn Really glad that reducing the overhead of passing structures between Rust and JS is a focus for 3.0. I thought I'd open a separate issue for this specific subject.
As you know, I've been battling with exactly this in swc-project/swc#2175 for a couple of years now!
That issue has been silent for a long time, but I've not abandoned it. In fact, have been quietly working on it again over past month.
I've concluded that RKYV is not the best tool for the job. While deserialization is zero cost (well, kind of), serialization is anything but. It does a lot of work constructing its "archived" versions of structures, so is relatively slow.
It's also been a problem that SWC's AST types change quite regularly, and manually updating the schema that creates the JS-side serializer/deserializer every time there's a change is a pain.
New approach
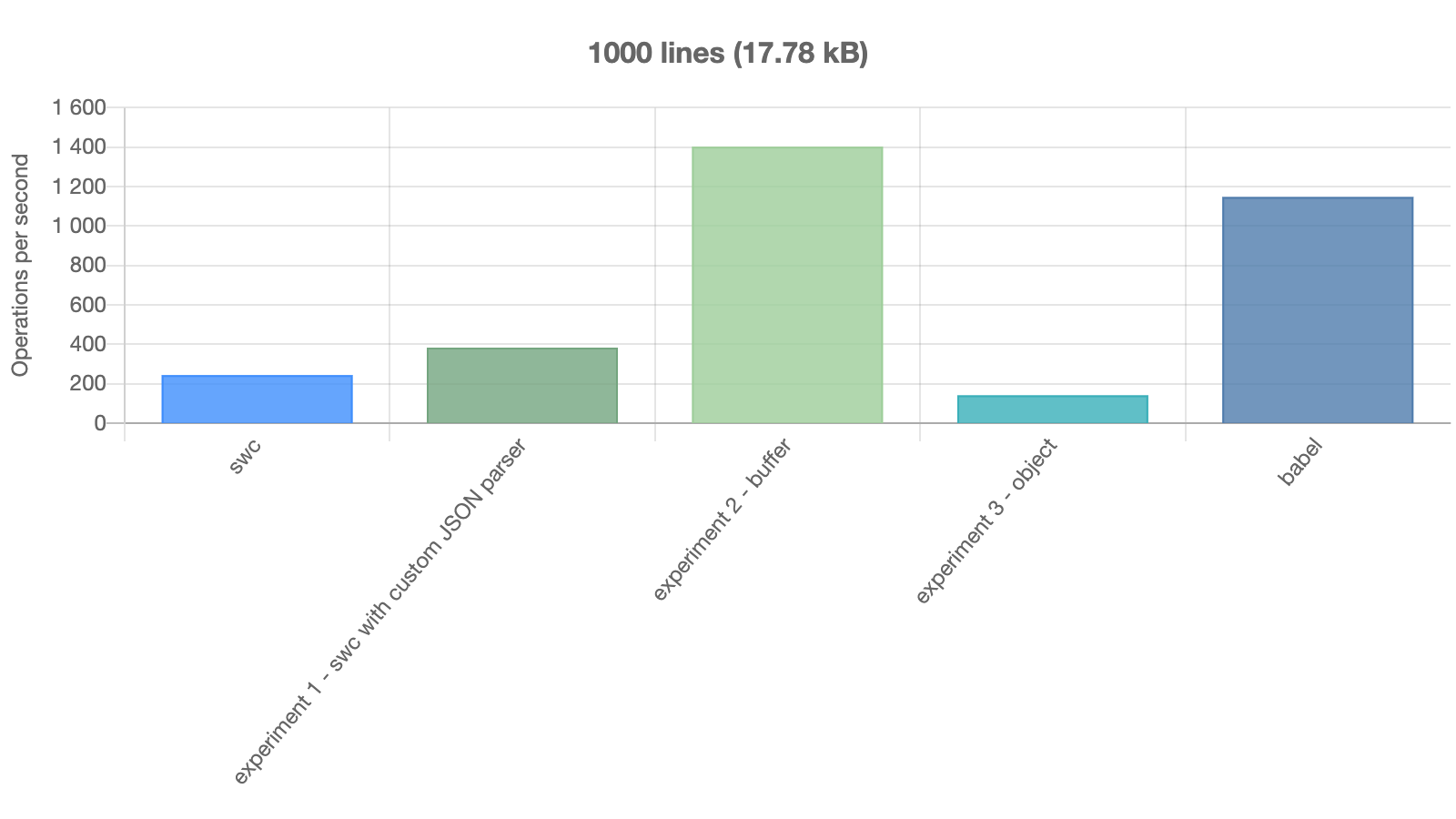
I recently benchmarked another approach. These numbers are for serializing the SWC AST of the minified build of React:
Abomonation has its problems - it's gratuitously unsafe, doesn't respect alignment, and is unmaintained. But I think its basic approach is good for this use case. It just copies the bytes of the Rust structs verbatim, without any transformation, into a single buffer. It's simple, and consequently it's fast.
Essentially, its serialization format is Rust's native type layouts.
The output contains pointers (for
Box,Vecetc) which are not meaningful on the JS side. But it turns out this doesn't matter. As the structures are pushed into the buffer in a deterministic order, as long as you have a matching schema on JS side, and deserialize in the same order, you always know how to interpret what's next in the buffer, and the pointers are irrelevant.Implementation steps
So here's how I planned to implement this:
Create a new version of Abomonation which avoids its safety issues. Haven't published this yet, but well on the way.
Create a tool to generate schemas for Rust type layouts which JS-side deserializer can use. Prototype: https://github.com/overlookmotel/layout_inspect
Use a codegen to create the JS-side serializer + deserializer from the schema. This will be adapted from the one I created for deserializing RKYV structs for SWC.
There are some tricky issues with creating an accurate schema, notably Rust's use of niches for
Option(see here), but I think they're largely solvable.Main advantages
&T.NB To get a usable
&mut T, would need to first clone the&T, because all the objects have been created in a single allocation, soDropbecomes a problem.Future developments
I can see further ways to build on this in future:
Lazy deserialization
I said above that the pointers in the buffer are irrelevant. That's true, but only if you deserialize the whole structure in one go.
A slightly more complex Rust-side serializer could rewrite pointers in the buffer data with pointers to positions in the buffer. This would enable random access reads on JS side (without having to deserialize the entire tree before any access is possible).
Combine that with Proxies, and you could walk the tree in any order, deserializing on demand, and any parts which aren't visited aren't deserialized at all.
Partial serialization
For some uses (e.g. SWC ASTs), you likely only need small parts of the structure for what you're doing. With some kind of "selector" mechanism, Rust could only serialize and send to JS the parts of the data that are actually needed.
Serialize and deserialize in parallel
If Rust-side serializer is running in an async thread, it can stream buffer chunks to JS as it produces them. JS deserializer can consume chunk 1 while Rust is loading up chunk 2.
Change sets
For example with SWC: The entire AST is sent Rust -> JS, JS code makes (usually minimal) changes to AST, then serializes the whole AST again, and sends it back to Rust.
If the objects on JS side were Proxies, they could instead record just a list of the changes made, and those changes could be replayed on Rust side. This would reduce serialization, deserialization, and allocation overhead.
Arenas
The serialization format is native Rust type layouts. Essentially, we teach JS to "speak Rust". This opens the door for a huge optimisation for use cases where performance is paramount: Arenas.
If the Rust-side code allocates all its objects with an arena allocator:
Obviously, there's a lot of danger to this. JS code would need to maintain Rust's aliasing rules etc. If the JS code is buggy, it'd produce invalid data which Rust would then read as if it's trusted, and would likely lead to exactly the kind of safety issues that Rust is meant to avoid. So it'd be difficult, and it'd have to be bulletproof. But if it did work, it'd pretty much entirely destroy the barrier between Rust and JS.
Questions
Sorry this is long. I've been thinking about this a lot! Would be very interested in your thoughts.
One thing: You've mentioned a few times that WASM could play a role, because it can create JS Objects faster than NAPI. I am struggling to understand this - I thought WASM operated in primitives only (ints etc), and creation of even strings had to be done in JS "glue code". What am I missing?
The text was updated successfully, but these errors were encountered: