DatatonBC 2018. Transaction Classification/Clasificación de Transacciones.
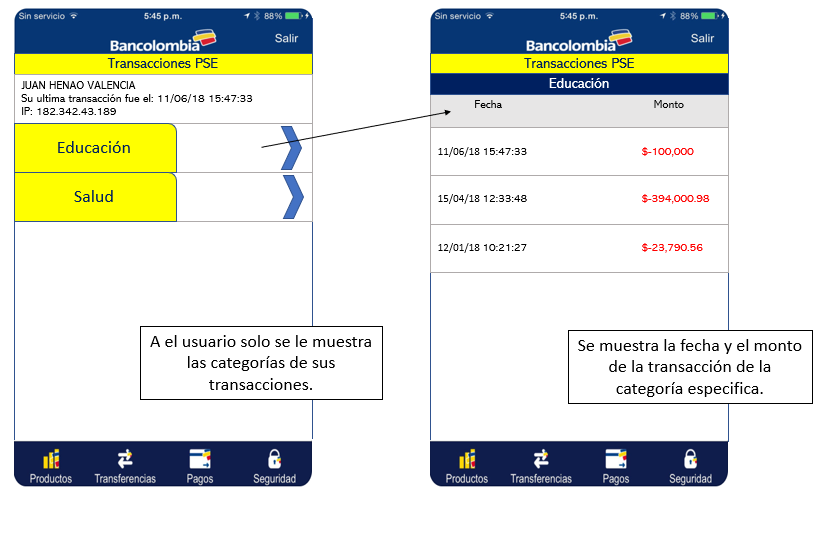
Clasificación de transacciones PSE. Se espera que el usuario entienda la naturaleza de sus movimientos bancarios a través de PSE. Adicionalmente, Bancolombia podrá detectar el destino del dinero.
- Alejandro Murillo G.
- Henry Velasco V.
- Juan Pablo Vidal C.
En el documento 'Clasificacion_de_TransaccionesPSE_con_kNN.pdf' se encuentra una descripcion breve y detallada de la metodología usada y de los resultados obtenidos. La siguiente tabla resume algunos resultados:
| Dataset | Score | Accuracy | Recall | Precision | F1 | R^2 | Size |
|---|---|---|---|---|---|---|---|
| Entrenamiento | 0.991257 | 0.991257 | 0.991257 | 0.991208 | 0.991076 | 0.984354 | 1'350.000 |
| Validación | 0.990373 | 0.990373 | 0.990373 | 0.990338 | 0.990435 | 0.978653 | 75.000 |
| Prueba | 0.98808 | 0.98808 | 0.98808 | 0.989438 | 0.988381 | 0.974052 | 75.000 |
Tomamos una muestra de alrededor del 10% de los datos no etiquetados. Haciendo uso del kNN entrenado clasificamos esos datos y obtuvimos los siguientes resultados:
Número Transacciones por Categoría

La mayoría de las transacciones ocurren en las categorías Valor agregado, Tecnología y Comunicaciones, Servicios Bancarios, Administración central y Electricidad.
Valor Transacciones por Categoría

Alrededor del 80% del dinero es usado en transacciones de las categorías Servicios Bancarios, Tecnología y Comunicaciones.
En Additional_Models puede encontrar unos notebook con los prometedores resultados al tratar de clasificar con otros modelos.
- Preprocesamiento dataset original: 'dt_trxpse_personas_2016_2018_muestra_adjt.csv'.
- Esto se lleva a cabo con el script trxpse_persona_data_scraper.py.
- Se reemplaza en la variable dataset_path con el path del CSV 'dt_trxpse_personas_2016_2018_muestra_adjt.csv'.
- Se corre el script.
- El script crea dos data sets (estos contienen las transacciones con y sin label, desordenadas):
- 'LABELED_DATA_TRXPSE_BC.csv'
- 'UNLABELED_DATA_TRXPSE_BC.csv'
- Carga de datos:
- Se hace uso de la clase LoadData.py.
- Se reemplaza el atributo __dataset_path con el path de 'LABELED_DATA_TRXPSE_BC.csv'; y en x_path y y_path los paths de 'X_DATA_TRXPSE_BC.csv' y 'Y_DATA_TRXPSE_BC.csv', respectivamente.
- Si es la primera vez que se usa, es necesario hacer el parámetro de inicialización load_unprocessed_data=True. Esto guarda los datos procesados en dos archivos ('X_DATA_TRXPSE_BC.csv', 'Y_DATA_TRXPSE_BC.csv'), que serán usados para crear los sets de Entrenamiento, Validación y Prueba. En caso contrario, una vez instanciado LoadData se llama el método load_processed_data(), que cargará 'X_DATA_TRXPSE_BC.csv' y 'Y_DATA_TRXPSE_BC.csv' y creará los data sets necesarios.
- Clasificación:
- Se hace uso de la clase TransactionClassifier.py.
- Una vez instanciado se llama el método train() y se le pasan los datos cargados en el paso anterior.
- Use de acuerdo a su necesidad los métodos test(), predict(), get_confusion_matrix(), save_model() y load_model().
Octubre 29, 2018.