![]()


Accelerated NLP pipelines for fast inference 🚀 on CPU and GPU. Built with 🤗Transformers, Optimum and ONNX runtime.
With PyPI:
pip install optimum-transformersOr directly from GitHub:
pip install git+https://github.com/AlekseyKorshuk/optimum-transformersThe pipeline API is similar to transformers pipeline with just a few differences which are explained below.
Just provide the path/url to the model, and it'll download the model if needed from the hub and automatically create onnx graph and run inference.
from optimum_transformers import pipeline
# Initialize a pipeline by passing the task name and
# set onnx to True (default value is also True)
nlp = pipeline("sentiment-analysis", use_onnx=True)
nlp("Transformers and onnx runtime is an awesome combo!")
# [{'label': 'POSITIVE', 'score': 0.999721109867096}] Or provide a different model using the model argument.
from optimum_transformers import pipeline
nlp = pipeline("question-answering", model="deepset/roberta-base-squad2", use_onnx=True)
nlp(question="What is ONNX Runtime ?",
context="ONNX Runtime is a highly performant single inference engine for multiple platforms and hardware")
# {'answer': 'highly performant single inference engine for multiple platforms and hardware', 'end': 94,
# 'score': 0.751201868057251, 'start': 18}from optimum_transformers import pipeline
nlp = pipeline("ner", model="mys/electra-base-turkish-cased-ner", use_onnx=True, optimize=True,
grouped_entities=True)
nlp("adana kebap ülkemizin önemli lezzetlerinden biridir.")
# [{'entity_group': 'B-food', 'score': 0.869149774312973, 'word': 'adana kebap'}]Set use_onnx to False for standard torch inference. Set optimize to True for quantize with ONNX. ( set use_onnx to
True)
You can create Pipeline objects for the following down-stream tasks:
feature-extraction: Generates a tensor representation for the input sequencenerandtoken-classification: Generates named entity mapping for each word in the input sequence.sentiment-analysis: Gives the polarity (positive / negative) of the whole input sequence. Can be used for any text classification model.question-answering: Provided some context and a question referring to the context, it will extract the answer to the question in the context.text-classification: Classifies sequences according to a given number of classes from training.zero-shot-classification: Classifies sequences according to a given number of classes directly in runtime.fill-mask: The task of masking tokens in a sequence with a masking token, and prompting the model to fill that mask with an appropriate token.text-generation: The task of generating text according to the previous text provided.
Calling the pipeline for the first time loads the model, creates the onnx graph, and caches it for future use. Due to this, the first load will take some time. Subsequent calls to the same model will load the onnx graph automatically from the cache.
Note: For some reason, onnx is slow on colab notebook, so you won't notice any speed-up there. Benchmark it on your own hardware.
Check our example of benchmarking: example.
For detailed benchmarks and other information refer to this blog post and notebook.
- Accelerate your NLP pipelines using Hugging Face Transformers and ONNX Runtime
- Exporting 🤗 transformers model to ONNX
Note: These results were collected on my local machine. So if you have high performance machine to benchmark, please contact me.
Benchmark sentiment-analysis pipeline
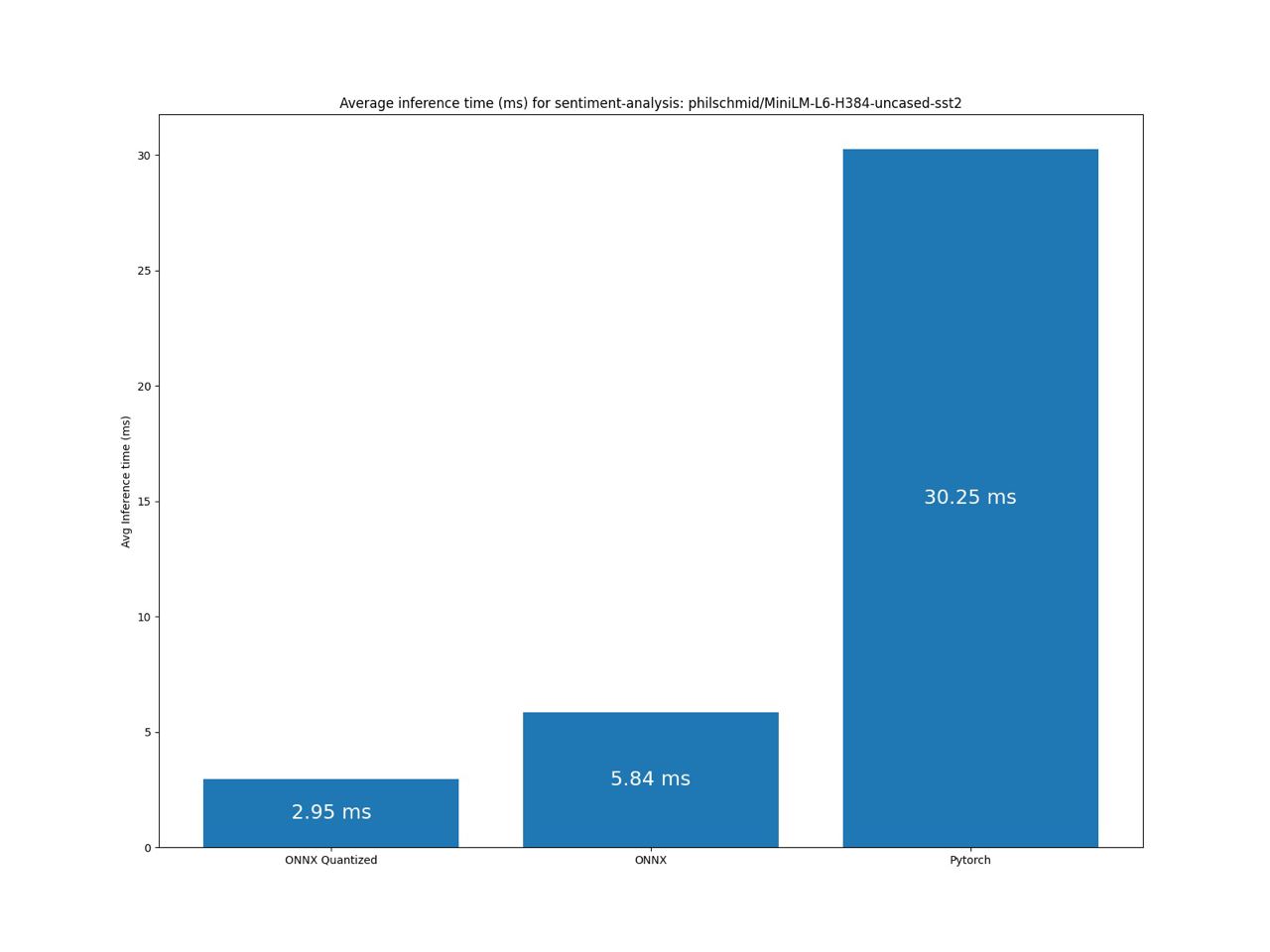
Benchmark zero-shot-classification pipeline
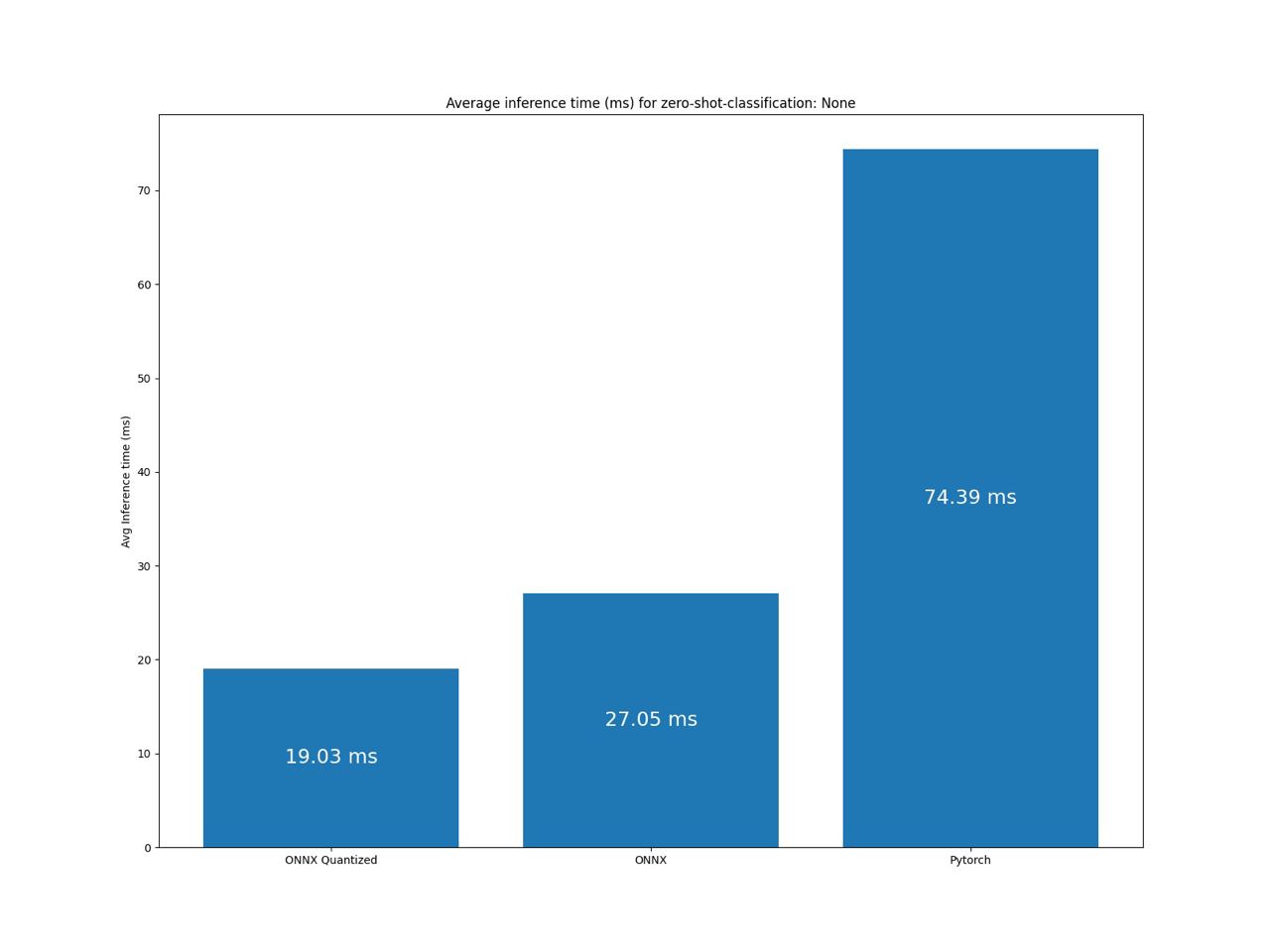
Benchmark token-classification pipeline
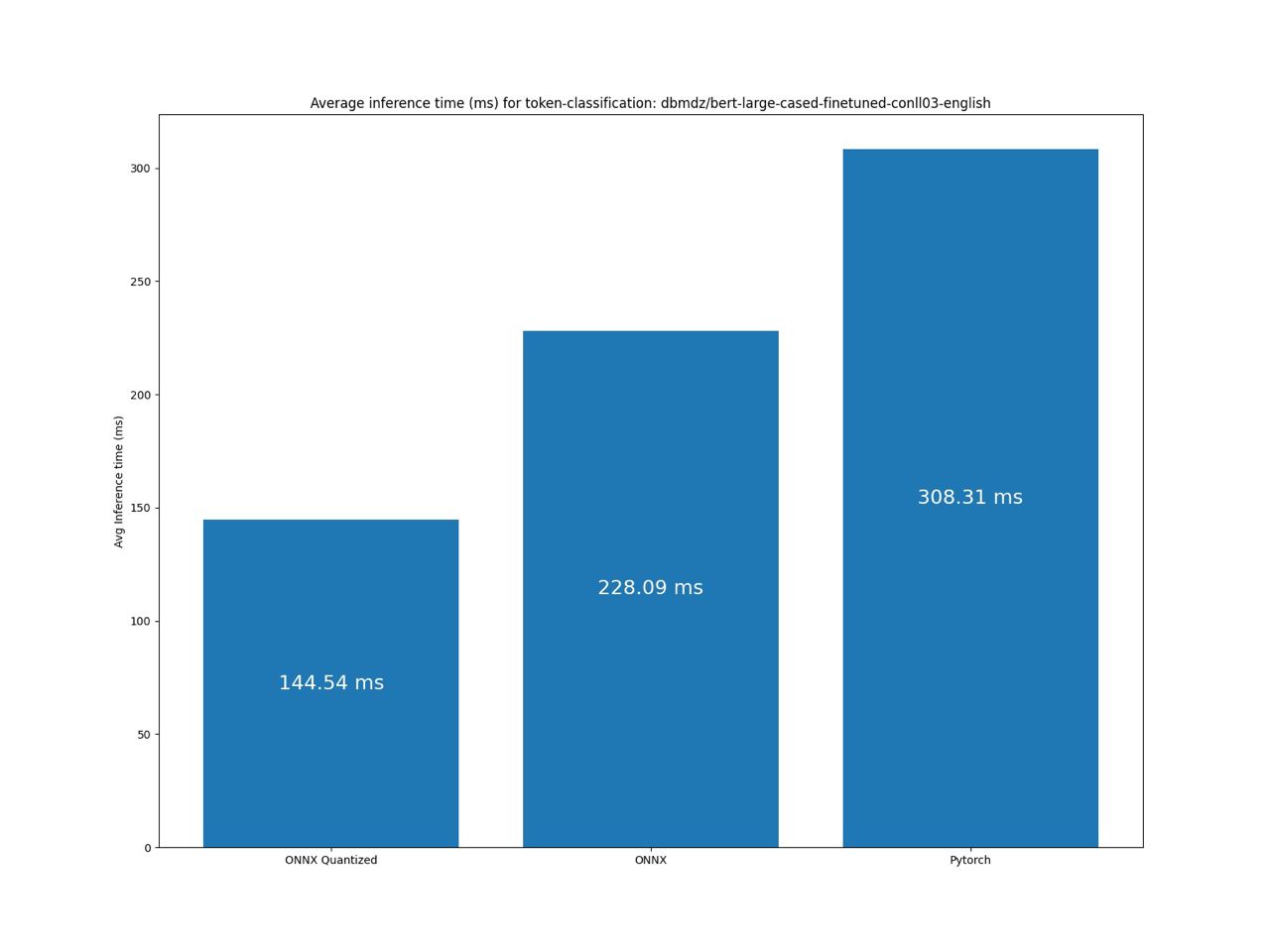
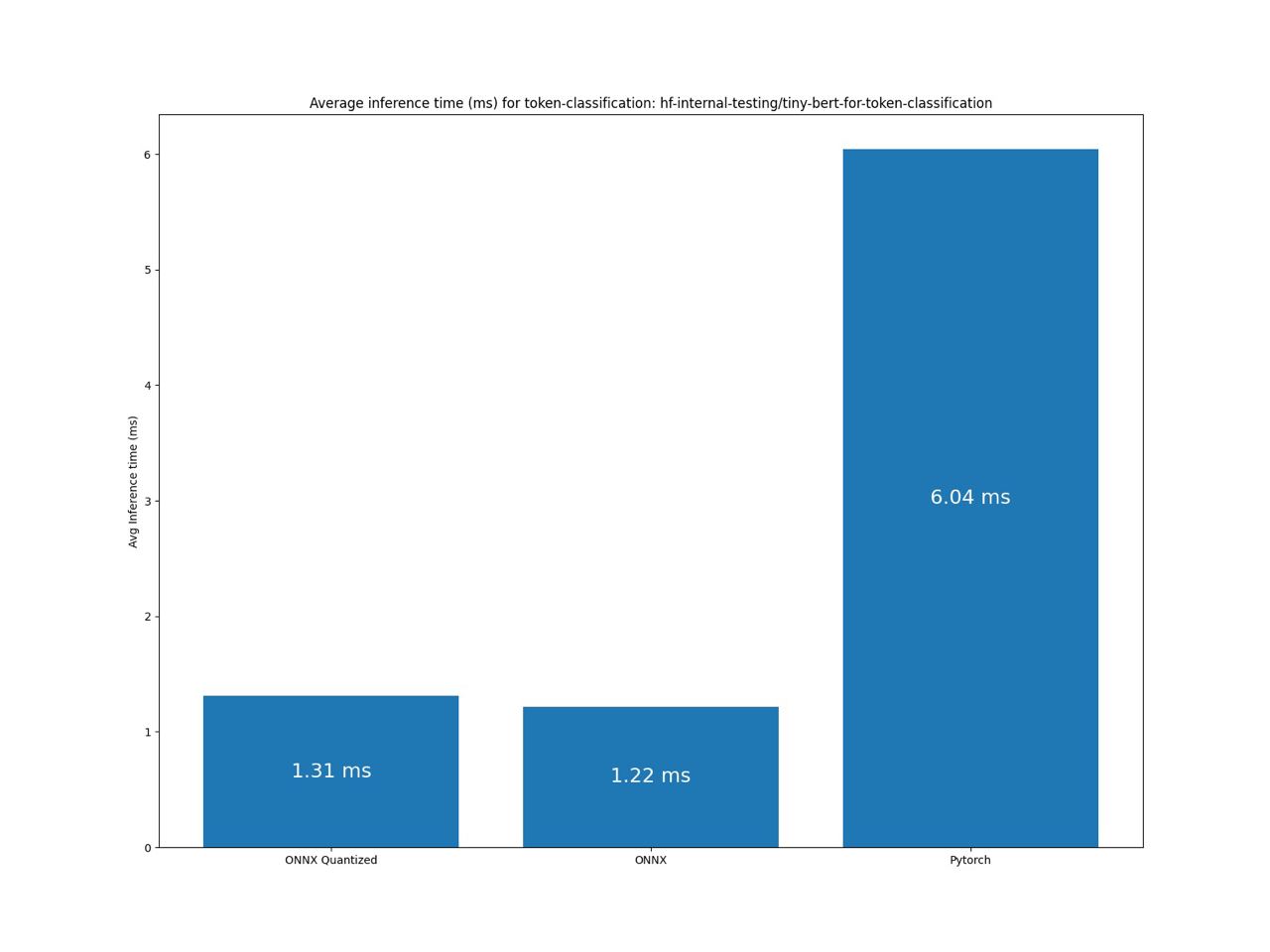
Benchmark question-answering pipeline

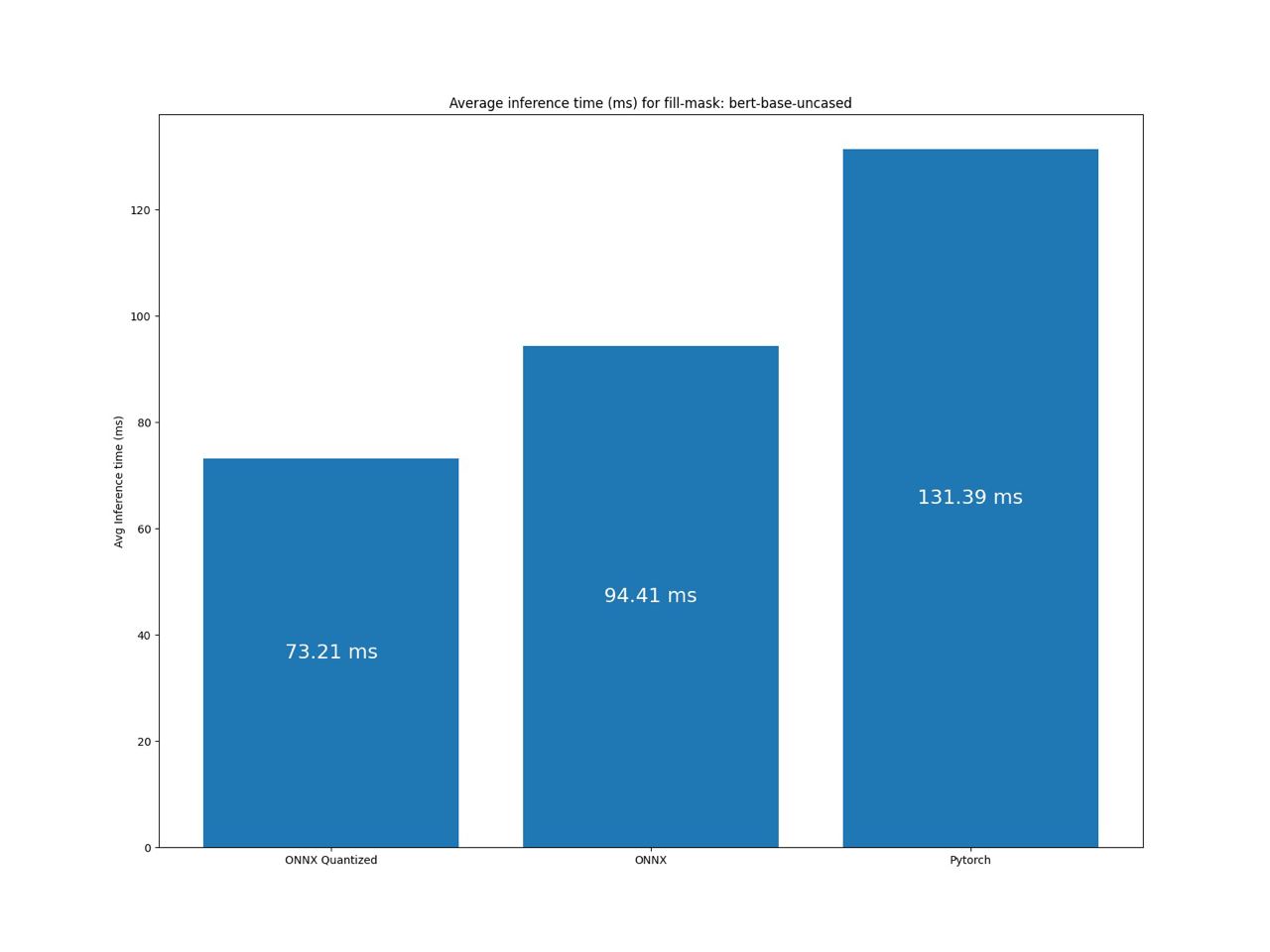
Benchmark fill-mask pipeline
Built by Aleksey Korshuk


🚀 If you want to contribute to this project OR create something cool together — contact me: link
Star this repository:

- Inspired by Huggingface Infinity
- First step done by Suraj Patil
- Optimum
- ONNX