
- What is Csv2sql ?
- Why Csv2sql ?
- Using from Command Line
- Using the browser based interface
- Running from source
- Supported data types
- Handling custom date/datetime formats
- Known issues, caveats and troubleshooting
- Future plans
Please have a quick look over the Known issues, caveats and troubleshooting section before using the app.
Csv2Sql is a blazing fast fully automated tool to load huge CSV files into a RDBMS.
Csv2Sql can automatically...
- Read csv files and infer the database table structure
- Create the required tables in the database
- Insert all the csvs into the database
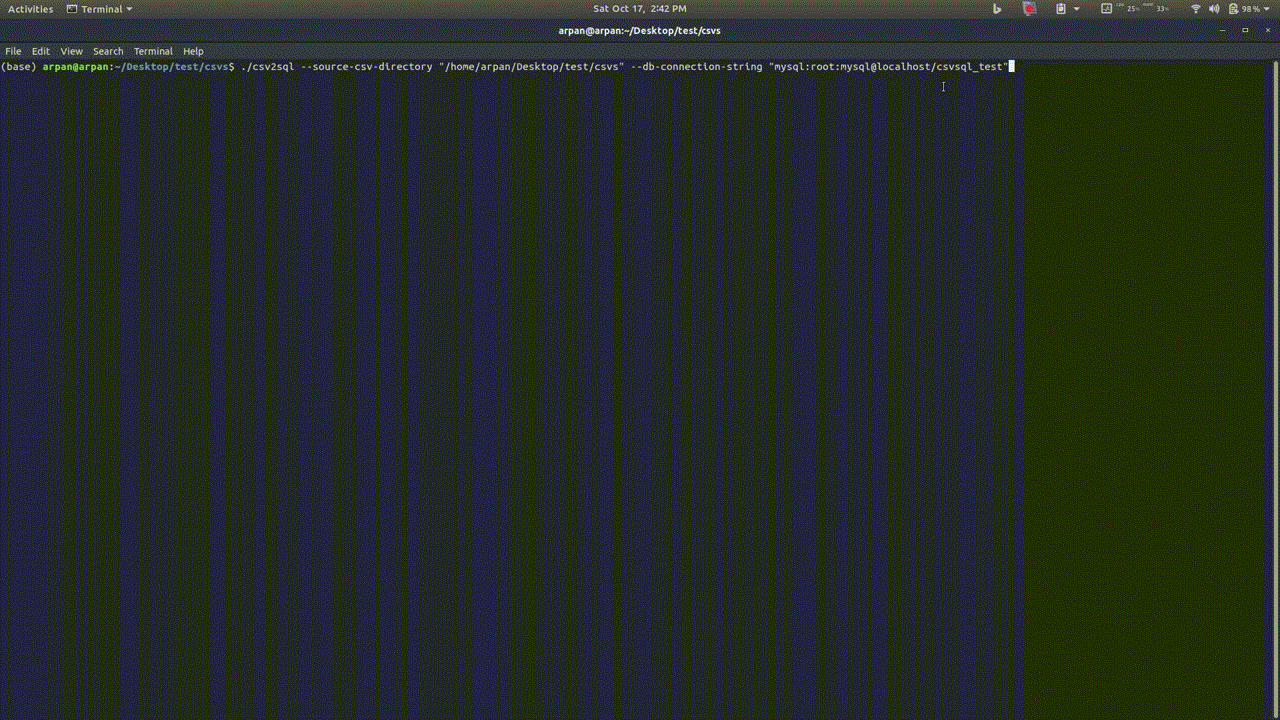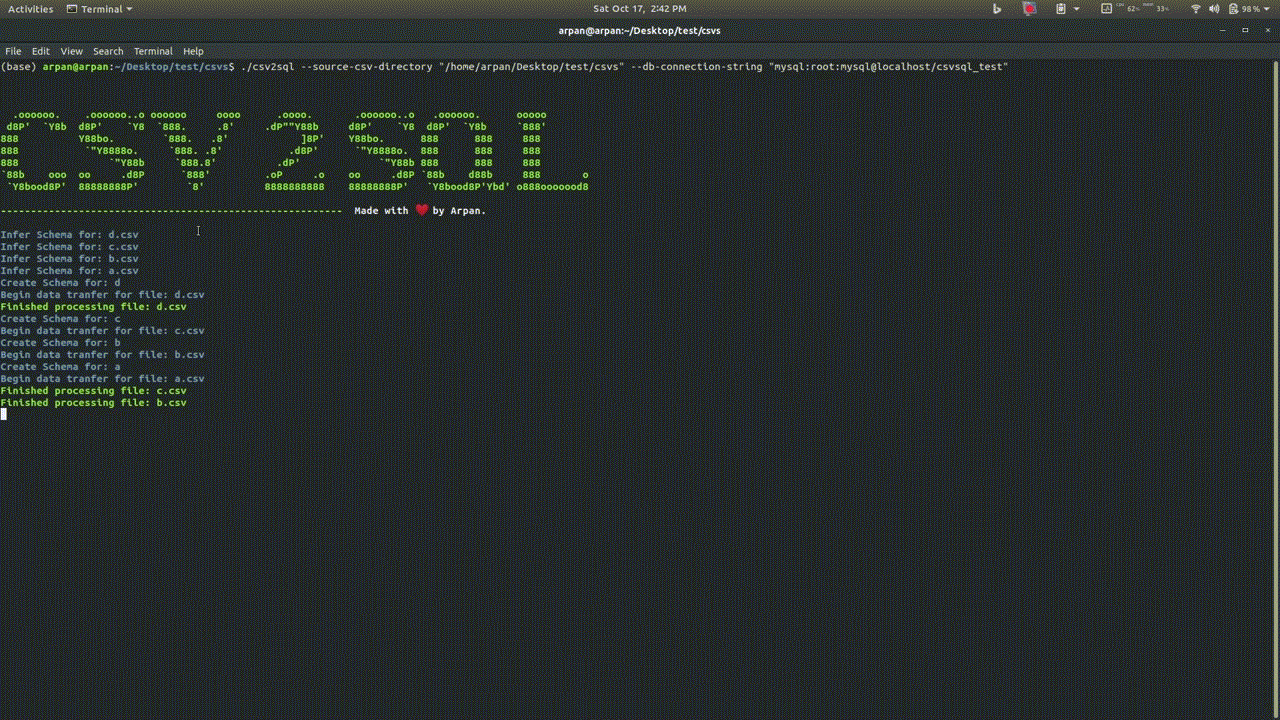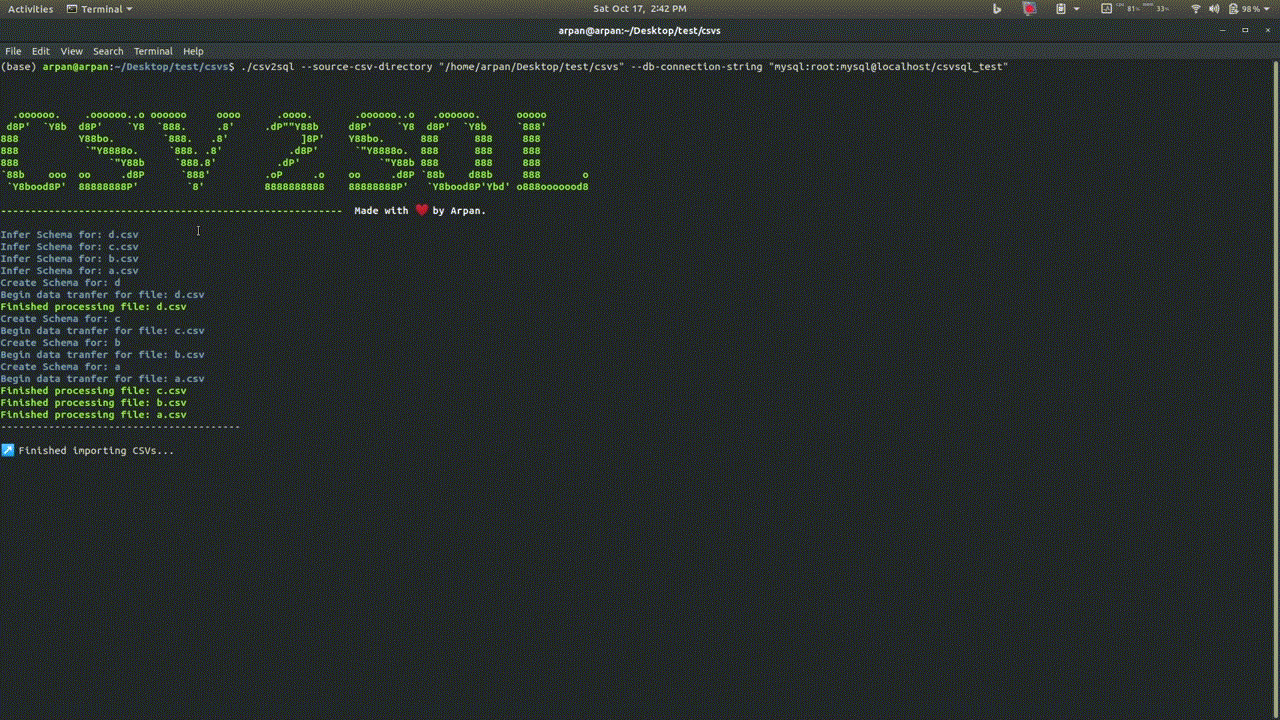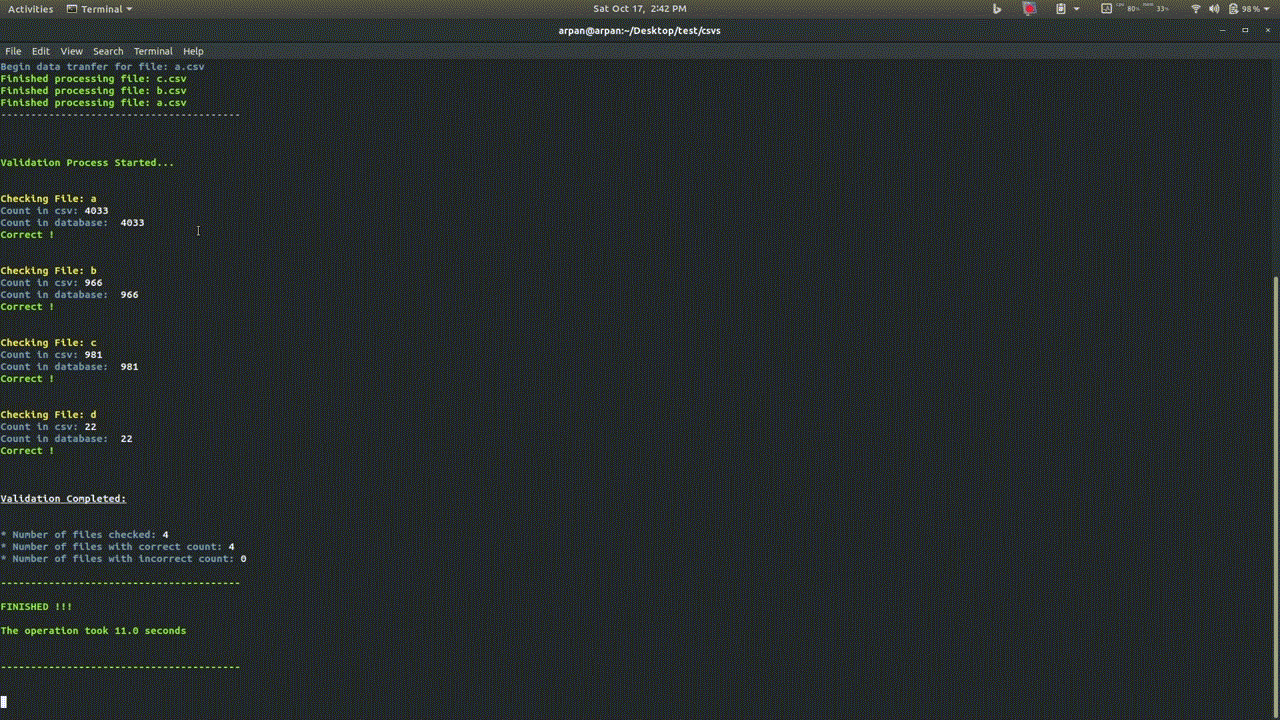
- Do a simple validation check to ensures that all the data as been imported correctly.
-
Utilizing the power of modern multi core processors, csv2sql does most of its tasks in parallel, this makes it super fast and more efficient than other tools.
-
It is completely automatic, provide a path with hundreds of csvs having size in gigabytes and start the application, it will handle the rest!
-
It comes in 2 flavours, as a command line tool or a browser user interface, and is super easy to configure and use.
-
While you can have maximum utilization of your cpu to get excellent performance, csv2sql is fully customizable, also comes with lots of options which can be changed to fine tune the application based on requirement and to lower down resource usage and database load.
-
Csv2Sql supports partial operations, so if you only want to generate a schema file from the csvs without touching the database or you want to only insert data from the csvs into already created tables without creating the tables again or just validate already imported data, Csv2Sql has got you covered !
Csv2sql can be easily used as a command line tool, with lots of customizable options passing by different command line arguments.
You must have erlang installed to use the command line tool on any linux distribution.
wget https://packages.erlang-solutions.com/erlang-solutions_1.0_all.deb
sudo dpkg -i erlang-solutions_1.0_all.deb
sudo apt-get update
sudo apt-get install esl-erlang
Download the executable binary from the latest release in this repository
and run the executable using: ./csv2sql --<argument>
The next section describes all the available command line arguments.
You can pass various command line arguments to Csv2Sql to configure how to process csvs and specify other important information.
A description of all the available command line arguments that can be used are given below:
| Flag | Description | Default value |
|---|---|---|
| --schema-file-path | The location were the generated schema file will be stored | If no value is supplied it saves the generated schema file in the same directory as the source csv files specified by "--source-csv-directory" flag |
| --source-csv-directory | The source directory where the csvs are located | Defaults to the current directory from which the program is run |
| --db-connection-string | A connection string to connect ot the database, in the format: "<database_type>:<database_username>:<database_password>@<database_host>/<database_name>" | This is a compulsory argument if database access is required |
| --imported-csv-directory | The directory were the csvs will be moved after importing to database, make sure it is present and is empty | (source-csv-directory)/imported |
| --validated-csv-directory | The directory were the csvs will be moved after they are validated, make sure it is present and is empty | (source-csv-directory)/validated |
| --skip-make-schema | Skip inferring schema and making a schema file | false |
| --skip-insert-schema | Skip inserting the inferred schema in the database. Useful if the table structures are already present and you only wish to insert data from the csv files.(This will be true automatically if skip-make-schema is used) | false |
| --skip-insert-data | Skip inserting data from the csvs | false |
| --skip-validate-import | Skip validating the imported data | false |
| --connection-socket | The mysql socket file path | /var/run/mysqld/mysqld.sock |
| --varchar-limit | The value of varchar type, and the limit after which a string is considered a text and not a varchar | 100 |
| --schema-infer-chunk-size | The chunk size to use when the schema fora CSV will be inferred parallelly. For example, a chunk size 100 means the CSV will be read 100 rows at a time and separate processes will be used to infer the schema for each 100-row chunk | 100 |
| --worker-count | The number of workers, directly related to how many CSVs will be processed parallelly | 10 |
| --db-worker-count | The number of database workers, lowering the value will lead to slow performance but lesser load on database, a higher value can lead to too many database connection errors. | 15 |
| --insertion-chunk-size | Number of records to insert into the database at once, increasing this may result in mysql error for too many placeholders | 100 |
| --job-count-limit | Number of chunks to keep in memory (Memory required=insertion_chunk_size * job_count_limit) | 10 |
| --log | Enable ecto logs, to log the queries being executed, possible values are :debug, :info, :warn | false |
| --timeout | The time in milliseconds to wait for the query call to finish | 60000 |
| --connect-timeout | The number of seconds that the mysqld server waits for a connect packet before responding with Bad handshake | 60000 |
| --pool-size | The pool_size controls how many connections you want to the database. | 20 |
| --queue-target | The time to wait for a database connection | 5000 |
| --queue-interval | If all connections checked out during a :queue_interval takes more than :queue_target, then we double the :queue_target. | 1000 |
Load csvs to database, this will infer the schema, insert the inferred schemas to the database, insert the data and then validate data for all the csvs
./csv2sql --source-csv-directory "/home/user/Desktop/csvs" --db-connection-string "mysql:root:pass@localhost/test_csv"
Here "mysql" is the database type, "root" is the mysql username, "pass" is the mysql password, "localhost" is the database host and "test_csv" is the database name where the data will be imported.
./csv2sql --source-csv-directory "/home/user/Desktop/csvs" --skip-insert-schema --skip-insert-data --skip-validate-import
./csv2sql --source-csv-directory "/home/user/Desktop/csvs" --db-connection-string "postgres:root:pass@localhost/test_csv" --skip-validate-import
Here "postgres" is the database type.
./csv2sql --skip-make-schema --skip-insert-data --imported-csv-directory "/home/user/Desktop/imported-csvs" --db-connection-string "mysql:root:pass@localhost/test_csv"
Here we are running simple validation check over a previously imported csvs, this check will NOT compare the actual data but will only compare the row count in the csv and in the database.
./csv2sql --source-csv-directory "/home/user/Desktop/csvs" --imported-csv-directory "/home/user/Desktop/imported_csvs" --validated-csv-directory "/home/user/Desktop/validated_csvs" --db-connection-string "postgres:root:pass@localhost/test_csv"
./csv2sql --source-csv-directory "/home/user/Desktop/csvs" --skip-insert-data --db-connection-string "postgres:root:pass@localhost/test_csv"
This will create empty table in the database after analyzing the csvs.
Change the worker count, setting this to one will lead to processing a single csv at a time, this will be slower but will lead to lower cpu usage and Database load:
./csv2sql --source-csv-directory "/home/user/Desktop/csvs" --worker-count 1 --db-connection-string "mysql:root:pass@localhost/test_csv"
./csv2sql --source-csv-directory "/home/user/Desktop/csvs" --log debug --db-connection-string "mysql:root:pass@localhost/test_csv"
Set the number of workers inserting data into the database, lowering the value will lead to slow performance but lesser load on database, a higher value can lead to too many database connection errors:
./csv2sql --source-csv-directory "/home/user/Desktop/csvs" --db-worker-count 2 --db-connection-string "mysql:root:pass@localhost/test_csv"
For ease of use csv2sql also has a browser interface which can be used to easily configure the tool and also provides an interface that shows what is the progress of the various running tasks, which files are currently being processed, the current cpu and memory usage, etc.
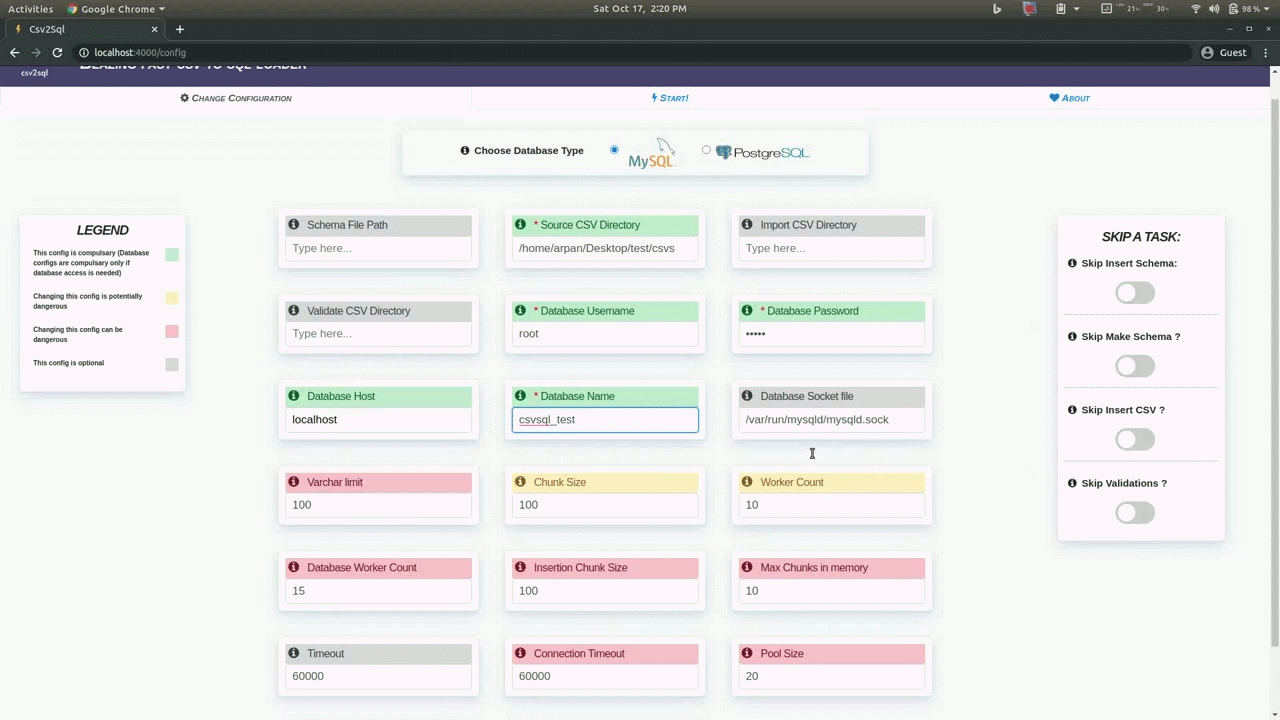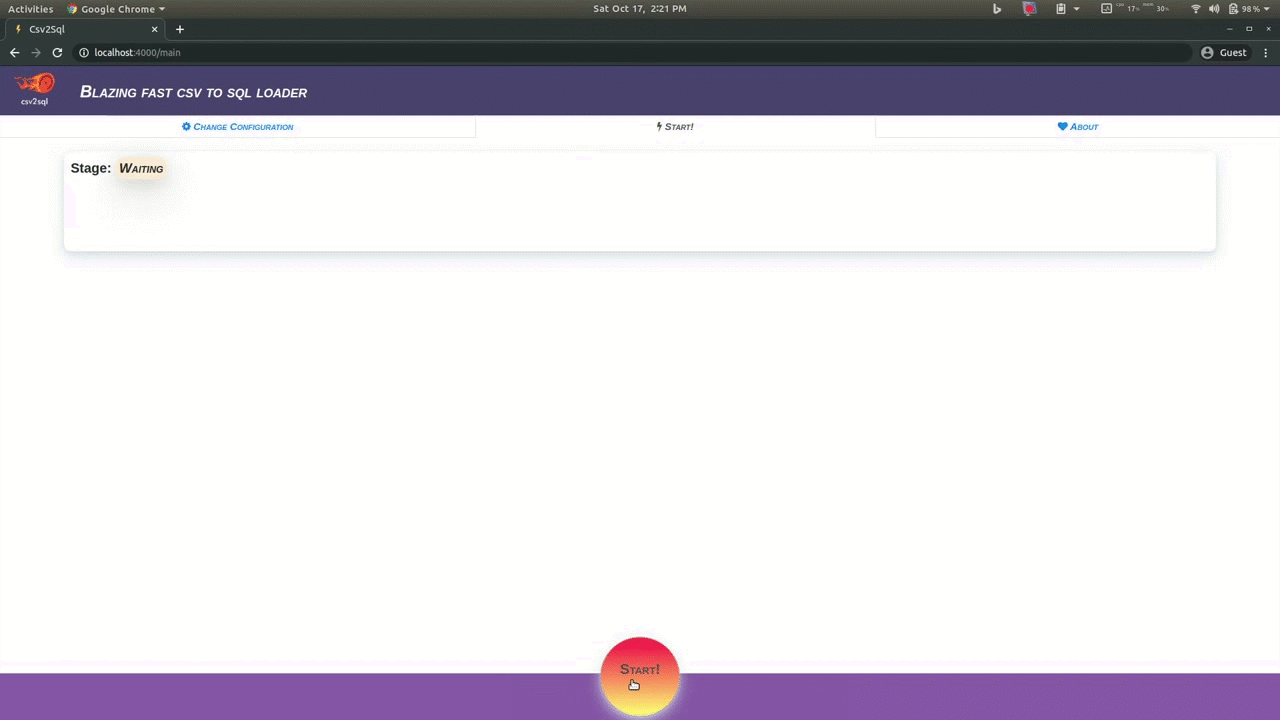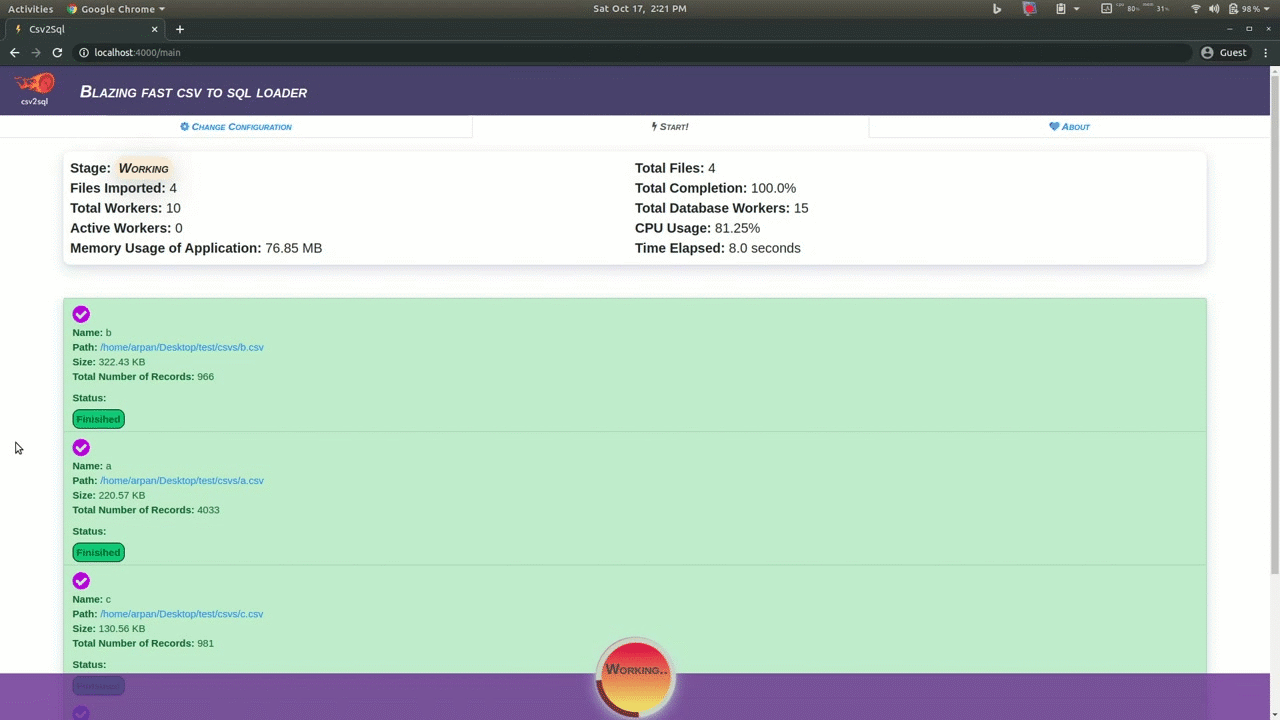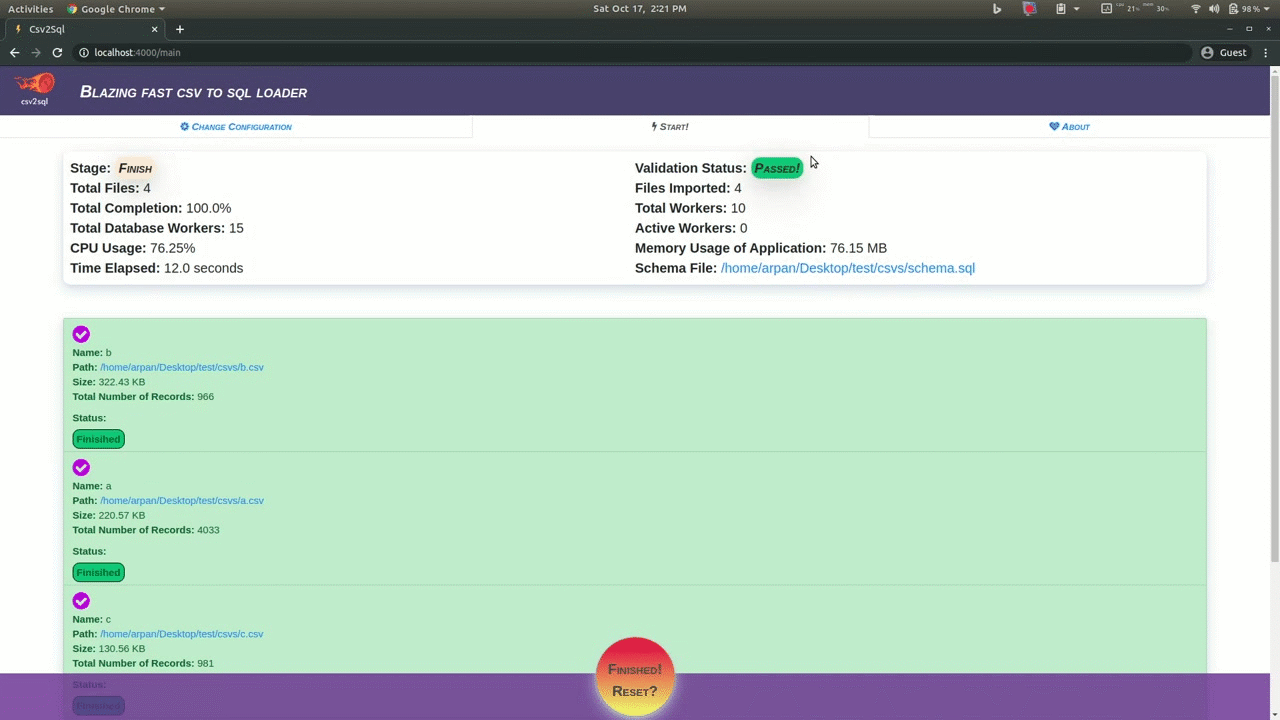
There are no dependencies needed to use the app via your browser, however you must have mysql or postgres installed.
Download the latest release of the app from the releases section in this repository.
You can now easily run the executable on your linux system, by:
- Extract the zip file named
csv2sql_xx - cd into the extracted directory from your terminal:
cd csv2sql_xx - Execute the following command:
./bin/csv2sql_and_dashboard start
This will run a local server which your access at localhost:4000 in your browser.
Thats all!
Please create an issue with details of your OS distribution, architecture(for example, x86_64 or ARM) and ABI (for example, musl or gnu) if the app does not run on your system
Using the app via the browser is super easy, once the app is running, go to localhost:4000 in your browser.
Now go to the Change configuration tab, and enter the relevant configuration details, hover over any configuration option to see what it does.
Whenever your are done, click on the Start tab and click on Start button below to start the import process.
You must have elixir and mysql/postgresql installed in your system to run Csv2Sql.
To use the app just clone this repository and then install dependencies
by mix deps.get
Finally, start the application by mix phx.server
This runs the phoenix server at localhost:4000 which provides a browser based interface to use the app.
Thats all !
Csv2sql currently supports MySql and PostgreSQL database.
Csv2Sql will map data in CSVs into one of the following data types:
| Type | mysql | postgres |
|---|---|---|
| date | For values matching pattern like YYYY-MM-DD or custom patterns | NOT SUPPORTED, will map to VARCHAR |
| datetime | For values matching pattern like YYYY-MM-DD hh:mm:ss or custom patterns , (WARNING: fractional seconds or timezone information will be lost if present) | NOT SUPPORTED, will map to VARCHAR |
| boolean | Maps values 0/1 or true/false to BIT type | Maps values 0/1 or true/false to BOOLEAN type |
| integer | INT | INT |
| float | DOUBLE | NUMERIC(1000, 100) |
| varchar | VARCHAR | VARCHAR |
| text | TEXT | TEXT |
All other types of data, will map to either VARCHAR or TEXT.
By default csv2sql will identify date or datetime of the following patterns YYYY-MM-DD and YYYY-MM-DD hh:mm:ss respectively.
If a csv file contains date or datetime in some other format then they will be imported as varchar by default however by specifying custom
patterns we can import such data of arbitrary formats as date or datetime.
csv2sql uses the Timex library to parse date/datetime.
You can specify multiple custom patterns for date or datetime as a string having one or more patterns separated by ;
When using the Web UI for csv2sql enter these pattern strings in the config page under "Custom date patterns" or "Custom datetime patterns".
The patterns should be compatible with Timex directives specified here.
(Custom patterns are only supported when using the web ui and are not available in the cli version of the application)
- Fractional seconds or timezone information is not handled when importing datetime data.
- When multiple custom patterns are specified for large csvs the import process might be slower due to the additional overhead of matching patterns.
- Always double check the patterns specified and verify imported date or datetime data
To parse datetime like 11/14/2021 3:43:28 PM a pattern like {0M}/{0D}/{YYYY} {h12}:{m}:{s} {AM} can be specified
The custom pattern needed is like...
{0M}/{0D}/{YYYY} {h12}:{m}:{s} {AM}
Consider a CSV with date or datetime having multiple formats like...
| Example Date | Date Pattern | Example Datetime | Datetime Pattern |
|---|---|---|---|
| 2021-11-14 | {YYYY}-{0M}-{0D} | 2021-11-14T15:43:28 | {YYYY}-{0M}-{0D}T{0h24}:{m}:{s} |
| 11-14-2021 | {0M}-{0D}-{YYYY} | 11-14-2021 15:43:28 | {0M}-{0D}-{YYYY} {0h24}:{m}:{s} |
| 11/14/2021 | {0M}/{0D}/{YYYY} | 11/14/2021 3:43:28 PM | {0M}/{0D}/{YYYY} {h12}:{m}:{s} {AM} |
The pattern strings to parse the above csv would look like...
For date
{YYYY}-{0M}-{0D};{0M}-{0D}-{YYYY}
For datetime
{YYYY}-{0M}-{0D}T{0h24}:{m}:{s};{0M}-{0D}-{YYYY} {0h24}:{m}:{s};{0M}/{0D}/{YYYY} {h12}:{m}:{s} {AM}
- Sometimes the app might fail when run for the first time with some error like..
%MyXQL.Error{connection_id: 9, message: "(1067) (ER_INVALID_DEFAULT) Invalid default value...
In this case, please try running the app again.
-
Timestamp columns will lose there fractional seconds data or time zone information when importing to mysql.
-
When importing into a postgres database you must create the database manually before running the application, otherwise it will fail.
-
Csvsql uses the csv file names as table names, make sure that the csv file names are valid table names.
-
Make sure your csvs have correct encoding and valid column names to avoid errors.(like a csv having duplicated column names will lead to errors when inserting in to the database).
-
If you face database connection timeout errors try reducing the worker and db_worker count in the configurations or change the database timeout, pool size and other related database configurations.
-
In case of errors, check your terminal for a clue, or create an issue.
- Support for windows os
- Work on known issues and better support for various data types