With the explosion of social networks, video content has risen exponentially over the last few years. Currently, Youtube reports 500h of video content being uploaded every minute. A Cisco forecast estimates that videos will constitute 80% of internet traffic by 2019. According to a recent study, 31.7% of videos on Youtube are duplicates with duplicates occupying 24% of storage space. It has become essential that we build robust systems to detect and purge these duplicates.
Near duplicate videos are a bigger class of problems which cover duplicate videos. Near duplicates videos are videos which have same visual content but differ in format ( scale, transformation, encoding etc ) or have small content modifications ( color / lightning / small text superimposition etc).
Given a corpus of videos, identify if a query video is a near duplicate of an existing video in corpus.
The standard for NDVD tasks is the CC_WEB_VIDEO dataset. The dataset contains a total of 13,129 videos and 24 query videos. The dataset already provides 398,008 keyframes extracted from the videos by shot boundary detection method.
The problem is tackled by using a bag-of visual words model for each video. This is done in following phases
-
Feature Extraction:

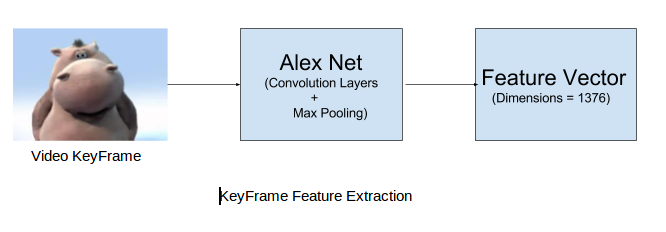
Convolution Neural Networks are used to extract features from the video keyframes. Pretrained CNN networks have been proven to work well on many vision tasks such as Classification, Segmentation etc. Here, pretrained weights of AlexNet is used to extract feature vectors. Each video keyframe is forward passed through the intermediate layers of AlexNet to get frame feature vector. Max-pooling is applied on the intermediate feature maps to extract one single value. Each frame is then represented by a feature vector of 1376 dimensions. The video-level feature vector is calculated by concatenating over the individual keyframe feature vectors.
-
Visual Codebook Generation:

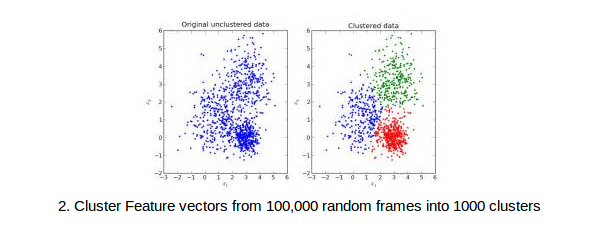
A visual codebook is generated using the above feature vectors. Online Mini-batch K means is used to generate the codebook clusters. A sample of random 100K frames are used for visual codebook generation. K = 1000 gives best results from experiments.
-
Video level histogram:

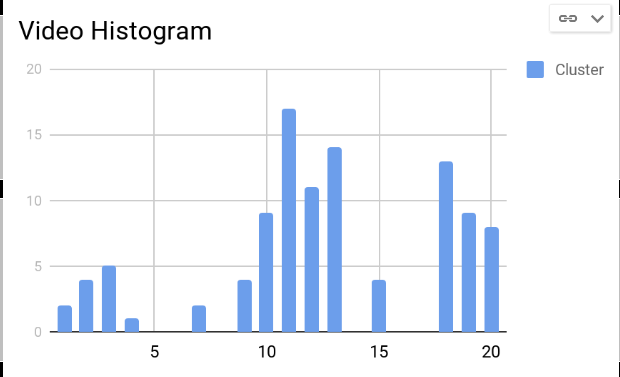
For each keyframe in a video, the Nearest cluster is identified to generate a keyframe level histogram. Correspondingly, a video level histogram is generated by summing oveer the individual keyframe histograms.
-
Similarity:

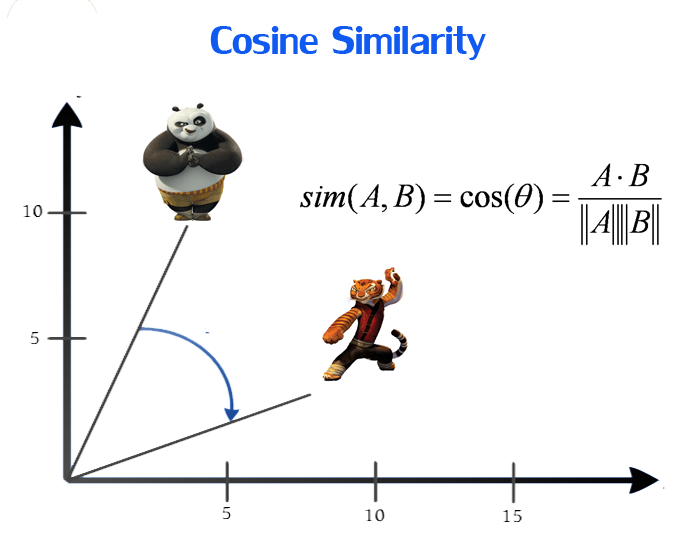
video similarity is inferred by calculating cosine similarity using tf-idf (term frequency / inverse-document frequency) between the two video histograms. To reduce the number of comparisons, we construct an inverted index to identify the videos which have a common visual word.
Using the above approach for the 24 query videos, the mAP (mean average precision) score was 0.951. The state of art techniques achieve a mAP of 0.98. However, note that the above metric is not very well deined compared to Classification / Segmentation tasks. Defining visually similar videos & ranking them is subject to human decision making and not well defined.
- Scalability: How can we extend this to handle videos / keyframes of 1M+ videos? K-means clustering suffers from curse of dimensionality.
- Robustness: Run detailed analysis of type of near-duplicate videos (scale changes, small frame changes etc) to report its robustness against diffetent types.
- Metric learning: Use metric learning to calculate the similarity metric between the near-duplicate videos.
- Near Duplicate Video Retrieval: Retreive a ranked list of near-duplicate videos in order of similarity. This can be extende to retrieve visually similar videos.