For the specification document, please go here.
This repository combines tools and data to quickly setup an environment for testing new solutions in the crisis domain, either standalone or in collaborative trials and experiments. To read more about its specification, see here. If you want to have a better understanding technically, see here.
Our work is funded by the DRIVER+ EU project as part of the Seventh Framework program, and runs till 2020. However, we are commited to find sustainable solutions well beyond this date.
Assuming you have installed docker, you can either go to docker/local and run docker-compose up -d, or from the root folder, you can start the test-bed with yarn local or npm run local (in this case, you also need to have yarn and npm installed).
To get your simulation or solution integrated with the Test-bed, this is the recommended process:
As a quick recap of what I normally do to get a local Test-bed up-and-running:
- Install Docker for Windows / Mac / Linux
- Checkout (download the zip or fork) this project: git clone https://github.com/DRIVER-EU/test-bed.git. In the near future, use the GUI, and we are working on a Cloud-based solution where we provide a hosted version for you.
- Follow the README: https://github.com/DRIVER-EU/test-bed/tree/master/docker
Optionally, refresh all Docker images before you start using:
docker images | grep -v REPOSITORY | awk '{print $1}' | uniq -u | xargs -L1 docker pullNext, depending on your application’s programming language, checkout an adapter and get the example (producer and consumer) working: Java, C#, JavaScript/TypeScript/Node.js, REST.
When sending messages, or receiving messages, you need to use Apache AVRO to specify them (and they need to be published to the Test-bed’s schema registry). But first, check if there isn’t a schema already available at https://github.com/DRIVER-EU/avro-schemas. If you need to create a new schema, you can register it manually at the Test-bed’s schema registry service (normally at http://localhost:3601) or use the adapter to do it for you (note that each schema’s name is [TOPIC-NAME]-value.avsc. If you do this manually, their should also be a corresponding [TOPIC-NAME]-key.avsc schema in order to use the AVRO format, but this is the same for each topic (information based on the EDSL DE enveloppe).
Note that you can inspect your messages in the Kafka topic viewer at http://localhost:3600.
You basically repeat the process as described above for the other solution. Note that you can record messages send by a solution using the (Node.js-based) Kafka-logger tool, which can be replayed using the Kafka replay service. This helps you in developing stand-alone, since you can replay the messages of the other solutions. In the near future, you should also have a message injector web app, comparable to Swagger, in which you will be able to create your own messages.
When your solution or simulator needs time, you need to query the adapter to get the local trial time. We are currently working on integrating the time service into each adapter. So there is no need to query the Test-bed yourself to get these messages. In case no time messages are available, I.e. we are not running a trial, it should return the system time.
The Observer Support Tool has already been trialed in Poland, and is actively worked upon to further improve it. Progress can be followed here.
The After-Action-Review tool, Message-Injector and Validation service, and Scenario Manager are expected in 2018 with a first version too, so please stay in tune.
Crisis management affects us all, and therefore we want to achieve a broad adoptation and no hindrances with respect to license management. In addition, being open source, we welcome everyone to create pull requests to improve the solutions that we are offering.
Commercial organisations can help you to integrate the test-bed in your organisation, offer software solutions that exceed the capabilities of the offered tools, of provide support in maintaining the test-bed.
Similar to websites like Ninite, where you can "Install and Update All Your Programs at Once", we will create a similar experience for the test-bed. Users of the test-bed can select the components that they need, and they receive a test-bed fitted to their needs. They can pick from:
- Support tools, which allow system administrators to quickly setup the test-bed, add or remove components, inspect its status, inject test messages, verify received messages, record and replay a session, trial or experiment. Support tools also covers authentication and authorization management, geo servers to share a map or other information layers, or observer tools. Additionally, it also includes tools to manage a trial, or a mailserver that allows participants to exchange messages with each other that can be easily recorded and re-examined later.
- Simulation tools, which allow the solution developers or trial managers to start a previously recorded flow of messages, e.g. a police car driving around, a flooding or earthquake simulation, or a sequence of tweets or email messages. It may also include simulation software, e.g. a traffic simulator that provides background traffic. In this way, they can create different virtual incidents for testing their solution standalone, or during a trial or experiment.
- Data sets representing virtual (or real) incident areas, e.g. a flooding simulation in The Netherlands or an earthquake in Italy, combined with relevant information static and dynamic layers. For example, static layers like background maps, census information, and critical infrastructure. Or dynamic layers, e.g. crowd simulations or sensor networks.
- Scenario's, e.g. a flooding or earthquake scenario, so end-users can quickly test solutions before setting up a trial themselves.
We also invite other parties to create (open or commercial) tools and data that are compatible, so they can swap out functionality or extend it.
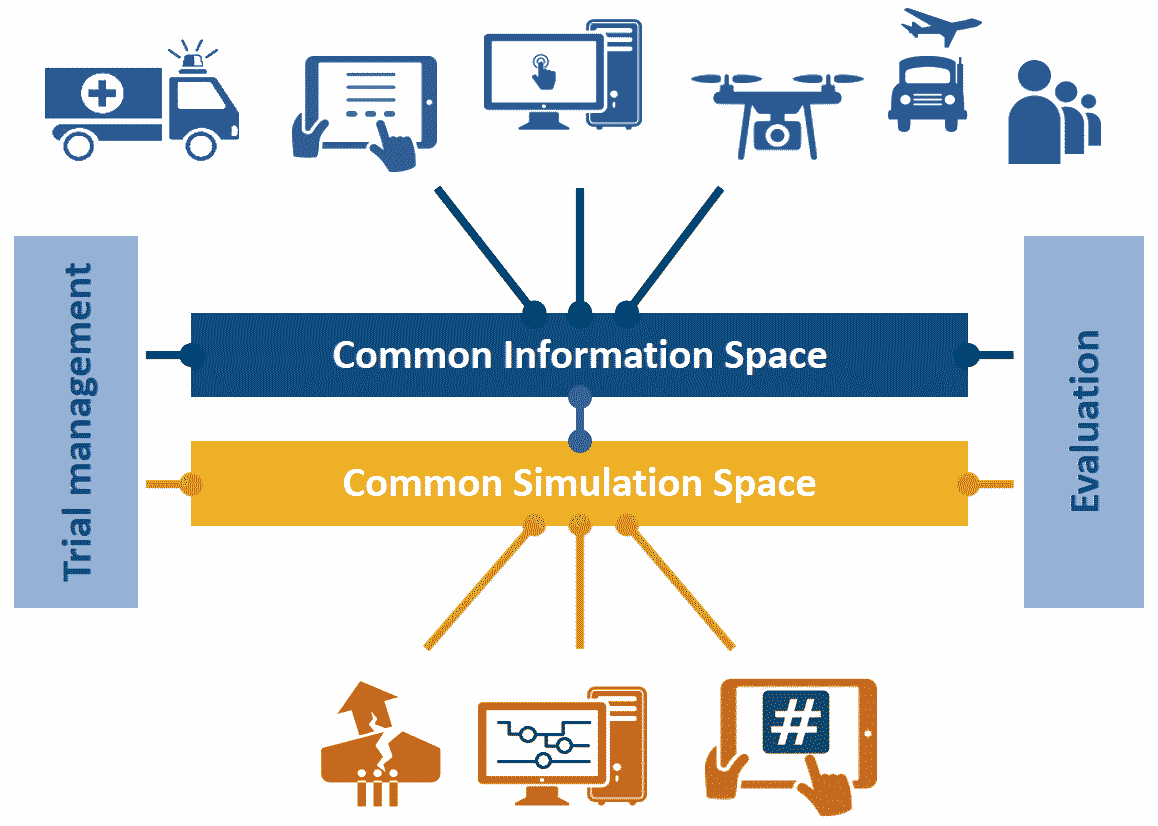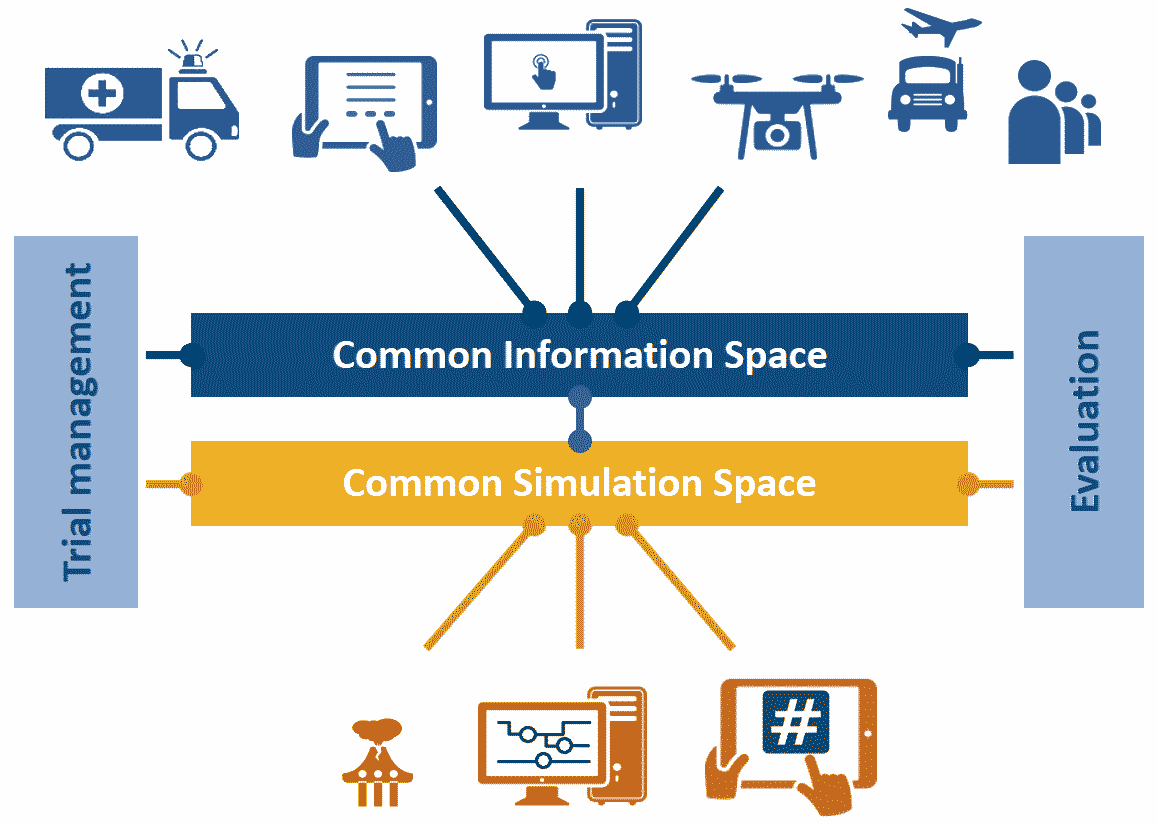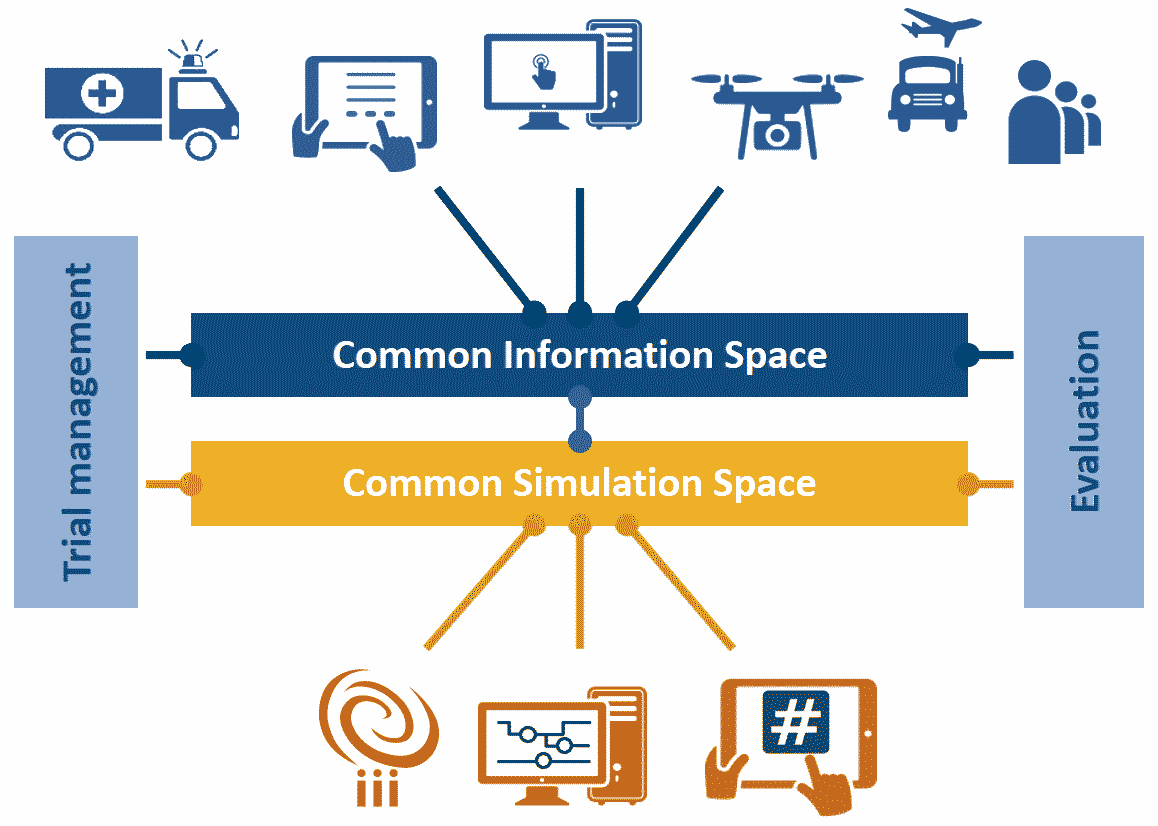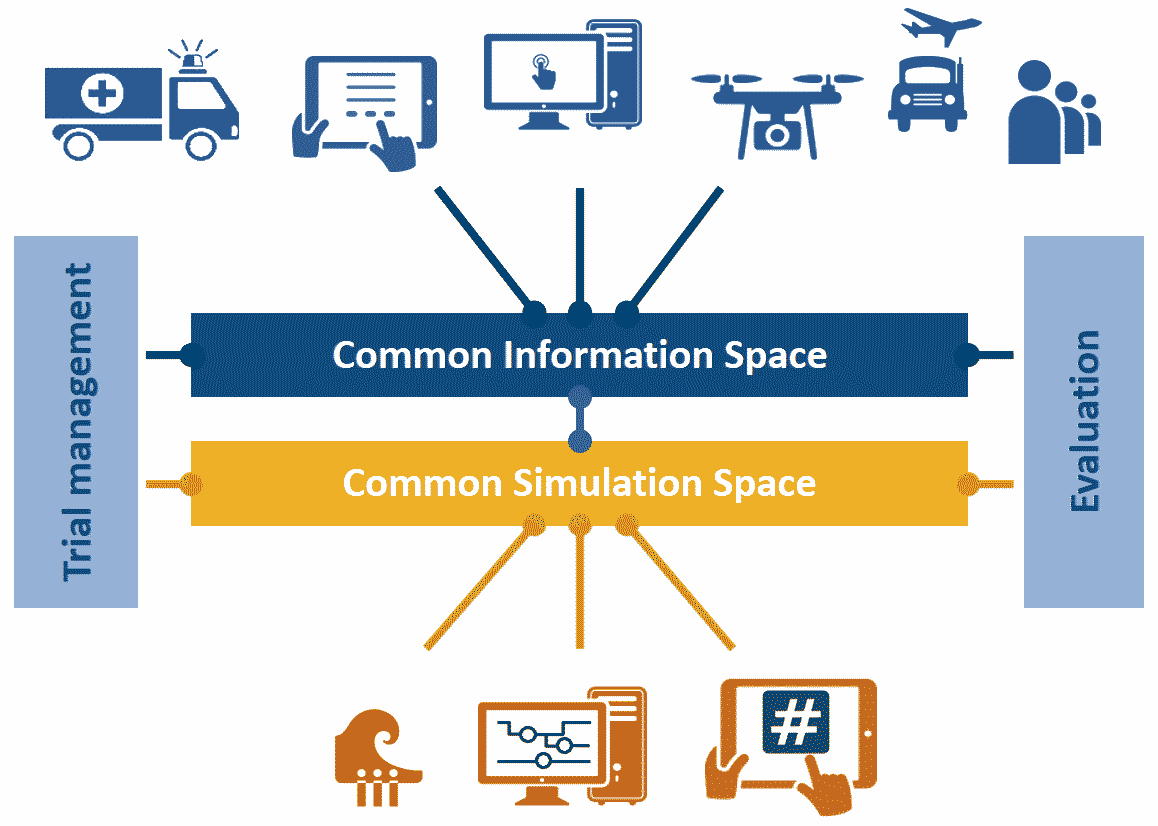
4. The test-bed consists of a Common Information Space, and a Common Simulation Space, connected via a Gateway
Interoperability in the test-bed is based on exchanging information (in the form of messages) between tools and users. Conceptually, there are two kinds of messages:
-
Informative messages that are exchanged between the end users (crisis management practicioners). These are part of the Common Information Space (or CIS). Messages exchanged in this space should be based on open standards to allow a wide adoption, and we support:
- OASIS Emergency Data Exchange Language, a.k.a. EDXL-DE, version 2
- OASIS Common Alerting Protocol (CAP) messages, version 1.2.
-
Simulation messages that are exchanged between different simulators, and which together create a virtual incident area. These are part of the Common Simulation Space (CSS). Messages exchanged in this space are more dynamic in nature, depending on the virtual incident that you wish to simulate, and even (commercial) simulation standards like the High Level Architecture, a.k.a. HLA or IEEE 1516, are often not flexible enough to support them. We therefore (most-likely - currently under investigation) will employ the Apache AVRO standard, also supported by the Apache organisation. It is a compact binary message exchange standard with a strong schema, which can be easily created (serialized) and read (deserialized). The schema is used to validate the structure of the messages.
The Gateway is the middleware glue that connects the two spaces: it will take information from the simulation space, convert it to the proper format, and publish it to the information space. For example, the measured water level during a flooding, or the location of ambulances, which subsequently can be displayed on a Common Operational Picture tool. Vice versa, it will convert informative messages from the information space to AVRO messages in the simulation space, e.g. to order a fire fighter to extinguish a fire.
In the figure, there are two other components:
- Trial or Scenario Management: they are used for controlling the virtual incident, e.g. to trigger a plane crash or start a forest fire, of flood the communication team with social media messages.
- After Action Review: allowing you to log the flow of messages, and replay and examine the trial at a later time.
NOTE: A simulator, e.g. a flooding simulator, that is used to support practitioners in making better decisions, is part of the CIS.
5. The test-bed shall run in a Docker environment.
Installing software can be tedious, and due to its nature, the test-bed consists of an integration of many tools. And although you could install each tool separately, in order to facilitate an easy deployment, we will use Docker images and Docker compose to rollout the test-bed. As Docker is supported on Unix as well as Windows operating systems, everyone should be able to run it smoothly.
As a consequence, for the moment most of the supplied tools will run in a Unix environment, since Windows-based Docker containers are still experimental. However, this will not limit you to create Windows-only solutions, as it can still connect to the test-bed.
In order to integrate different tools within the test-bed, and to make it easy to connect them with other solutions, we have selected an integration platform based on Apache Kafka. Although there are many good open-source messaging systems available, Kafka has a number of distinct advantages:
- It is supported by the Apache organisation, and used actively by a number of major commercial organisations. This means that it will not go away quickly, and it has many client connectors to ease integration.
- It is simple to setup and run, and performs very well. Where similar software systems cannot deal with more than 10.000 messages per second, Kafka can process a tenfold.
Although there are other environments that could satisfy our needs, this current reference implementation relies on Kafka, as we want to create a good reference implementation leveraging the efforts of the Kafka community, and by being more generic, i.e. supporting multiple backends, would require a lot more work, as well as not being able to leverage the particular strengths of the backend.