Let anyone search and label text with active learning and no servers
Watch The Intro Video
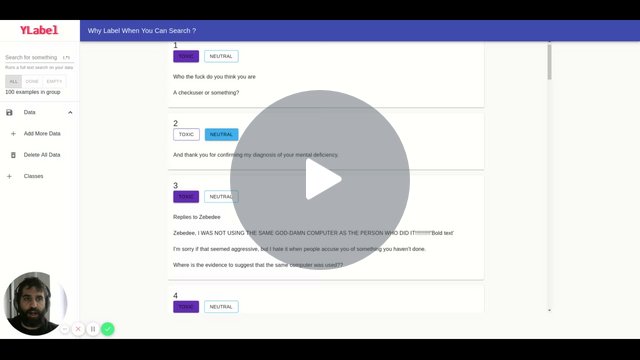
Typical usage scenario is company X has some domain experts (Doctor, trader, lawyer) and lots of text data and they want the expert to label the data. Often their is a lot of data and lots of it isn't relevant so it's an inefficient process that doesn't pan out. You can solve this with either guided learning or active learning, but both of these typically need some engineering work (e.g. client server +ML/search) and that's a lot of overhead for an adhoc project.
Y-Label tried to solve the above by
- Being completely in browser, so there is no engineering work
- Providing full text search / trigram indexing
- Implementing a deep active learning module that helps select the most relevant data
- Use IndexDB to give the user persistence without relying on a server
- Support any language without any assumptions about vocabulary or tokenization
- Work in the Browser with no communication to any server
- Be Dead easy for non-technical people to use
- Make exploring and labeling text datasets fast and easy.
- Upload data as a JSON array of objects and choose one field to label
- Stores data in IndexDB
- Creates a Trigram index on the data + Uses the index for regular search
- Regex search (but with no indexing)
- Add classes and classify each document
- Export the labels as JSON
- Allow CSV upload
- Active Learning for document classification on index DB
We are now at V0.0.0 Until say V0.0.X (X<5), we're doing 3 things
- Adding all the cool features we can think about
- Add support for span annotations
- Getting a feel for usability and settle on a look and feel
Between V0.0.X and V1 we'll be
- Figuring out stable API
- Rewriting this with clean code, tests and conformity to the APIs above.
The crucial thing for the second phase of V0 is figuring out APIs that will support swappable backends, so that users can for instance
- Add there own storage and data sources
- Implement their own search logic
- Bring in their own active learning models
The idea being that what the user can express should be confined, but what happens to those expressions should be configurable. However The goal for NOW is to figure out what this is, so we are writing dirty non-extensible code so that we can move fast.
YLabel has a few inspiring papers and ideas that are worth looking at
- [Why Label when you can Search? Alternatives to Active Learning for Applying Human Resources to Build Classification Models Under Extreme Class Imbalance] (http://pages.stern.nyu.edu/~fprovost/Papers/guidedlearning-kdd2010.pdf). This paper talks about the value of searching when we label data.
- Closing the Loop: Fast, Interactive Semi-Supervised Annotation With Queries on Features and Instances talks about searching and "feature" labeling along side active learning, with an old implementation in Java
- Active Learning Literature Survey The defintive guide on Active Learning
- Deep Active Learning for Named Entity Recognition A paper that shows that Deep Active Learning on text (For NER) is feasible and effective
- Neural Machine Translation in Linear Time A deep learning model for text that works at the charachter level and is (maybe) fast enough to work in the browser.
This is Tal Perry's "side-project". By day, I'm the founder and CEO of LightTag - The Text Annotation Tool for Teams, and this is where I get to try out new ideas, because they won't let me touch the code anymore.