
These files provide a basic structure for almost all applications and a powerful debugging system.
However, your coding style is not restricted in any way! Similar to LaTeX, focus on your content and spend less time on structural topics and debugging.
- Reduced boilerplate code > Just add lines of code, which are beneficial for the tasks
- Relieved memory allocations > Lifetime of requested memory very often matches the lifetime of the task itself, which is monitored. Therefore reducing the risk of memory leaks!
- Application level debugging > Spend less time on searching for strange bugs due to the improved overview of the system. Just focus on your tasks
- Increased productivity > A long-term relaxed and still speedy coding experience for everyone
- Quality control > Your code can be characterized and rated instead of calling it "clean" or "dirty"
- Simple and useful documentation > The structure allows for the creation of a visual description of your project which can be understood by tech and non-tech people.
- Increased maintainability > You get an easy-to-read code at any time. This remains true regardless of the size or complexity of the system. Use a set of simple instructions to reach the target architecture starting from the current state
- Big support range > Starting from small to very complex systems
- C++ standard as low as C++11 can be used
- On Microcontrollers: Minimum of 32k flash memory
- Mature code created in 2018
- Finished
The code of this repository is already very mature and has been successfully used on the following systems
- Linux / Raspberry Pi
- GCC
- Windows
- MinGW
- MSVC
- ESP32
- FreeBSD
- STM32G030 - Only Processing()
- Bare Metal
The Tutorials provide more information on how to delve into this wonderful (recursive) world ..
git submodule add https://github.com/NoOrientationProgramming/ProcessingCore.git
To implement a new process you can use the provided shell scripts on linux: cppprocessing.sh / cppprocessing_simple.sh
Or just create your own..
The key element consists of a single file named Processing.cpp. This file contains an abstract C++ class, which handles the processing of tasks within larger systems. The class serves as the foundation for implementing concrete user processes.

When using the Processing() class the entire system structure is recursive. This has a big and very beneficial impact during development, runtime, documentation and communication with other team members independent of their background.
There is no low- or high-level code. Just one essential looped function: process() .. everywhere
Success Supervising::process()
{
++mCounter; // do something wild
return Pending;
}Only a few lines of code are necessary to get a powerful debugging service integrated directly into your application. In this case we use the optional function initialize()
Success Supervising::initialize()
{
SystemDebugging *pDbg;
pDbg = SystemDebugging::create(this);
if (!pDbg)
return procErrLog(-1, "could not create process");
start(pDbg);
return Positive;
}After that, you can connect to three different TCP channels.
Optionally: Each process can show some useful stuff by creating a processInfo() function. The rest of your code is unaffected.
void Supervising::processInfo(char *pBuf, char *pBufEnd)
{
dInfo("Counter\t\t%d", mCounter);
}Just one quick look is needed to see how your entire system is doing.
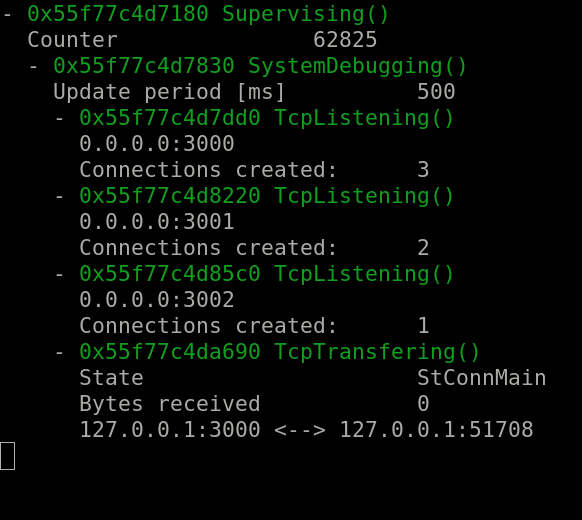
What is happening. But much more important: Who is doing what and when
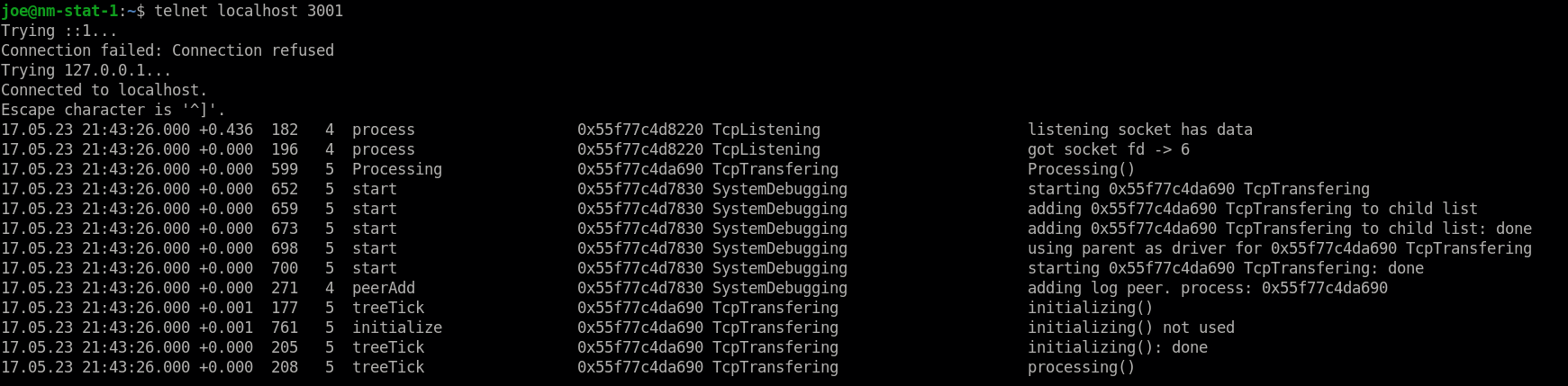
Do you want to trigger something? Just register a command anywhere in your application.
void yourCommand(char *pArgs, char *pBuf, char *pBufEnd)
{
dInfo("Executed with '%s'", pArgs);
}
Success Supervising::initialize()
{
...
cmdReg("test", yourCommand);
return Positive;
}
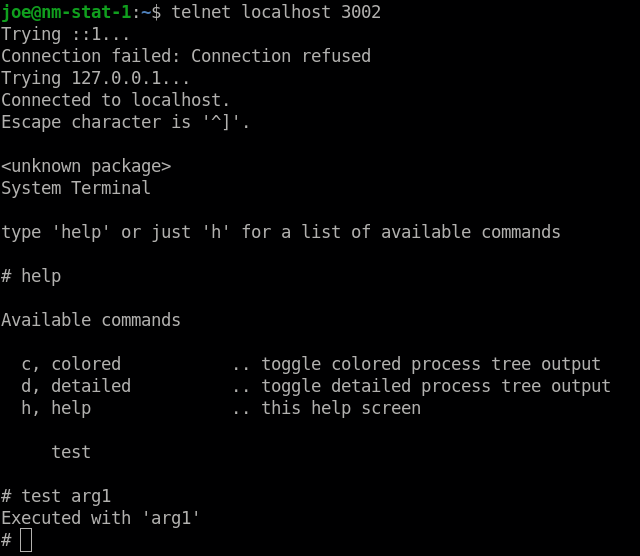
After a process has been started, it simply continues running in the background and completes its work. The parent process itself decides when to check for the completion of the activity. Although a callback can also be implemented as an alternative, we would advise against it. When callbacks are used, the parent process must deal with the 'interruption' at all times and must not be negatively affected by it. It's easier to simply ask the child process occasionally. Even if the child process has already finished the activity, the parent process is not obligated to accept the data. Thus, the child process even acts as a buffer for the achieved results. This is very practical and simplifies development.
Here we already see an important distinction between functions and processes. A function is an immediate mapping between its inputs and outputs. Outputs could be divided into an error code (→ success) and a result. The success of a function can thus be either negative (<0) or positive (1). Negative events should preferably always be processed first to avoid nesting of program code. This way, developers read the code linearly from top to bottom, simplifying development further. Now, a process is very similar to a function. However, the mapping does not occur instantaneously but takes too much time to wait for the result. Therefore, the success of a process has an additional state: Pending (0). Only when a process has completed its activity is the success either positive or any negative value. Processes can be divided based on the type of delay into
- Communication-bound processes
- Work-bound processes
The abstract core class solely implements the handling of success. You are free to choose the result a specific process delivers.
Another difference between functions and processes is that the result of functions is passed directly and immediately by the compiler. The function can then be dismantled immediately. All of this is accomplished by the compiler and with the help of the computer system's stack. However, with processes, the user decides when the data is processed. For this fundamental reason, the user must also take care of initiating the destruction procedure at least by themselves. Here too, the abstract process class helps us to properly shut down the specific user process. One last important piece of information is that processes cannot be implemented through the usual stack processing, as the lifespan of a process can be arbitrarily long. Therefore, all processes reside on the heap.
If the lifespan of the required data matches that of a process, then we have the advantage that the data does not need to be separately requested using malloc(). This is usually the case and reduces the risk of memory leaks, thereby making software development safer in general.
Success Supervising::process()
{
Success success;
// Wait
success = mpChild->success();
if (success == Pending)
return Pending;
// Check error
if (success != Positive)
return procErrLog(-1, "my child process failed");
// Consume result
mData = mpChild->data();
// Repel
repel(mpChild);
mpChild = NULL;
return Positive;
}If two or more work-bound processes are concurrently operated and the CPU has multiple cores, it is useful to parallelize their execution. But isn't parallelization entirely difficult? Actually not.. Just a single bit is enough to start a process in a new thread. The waiting for the completion of a process remains the same. Only in some cases does the transfer of data from one thread to another need to be done with a synchronization mechanism of your choice (e.g., mutex). Thanks to the good overview in the system, however, this also becomes child's play.
Success Supervising::initialize()
{
mpChild = IntenseCalculating::create();
if (!mpChild)
return procErrLog(-1, "could not create process");
start(mpChild, DrivenByNewInternalDriver);
return Positive;
}If there are many of these work-bound processes, the use of a thread pool could also be practical. Here too, the waiting procedure remains the same. This method of starting a process can also be used on microcontrollers to drive a process in interrupts or in general to implement intelligent scheduling mechanisms.
Success Supervising::initialize()
{
mpChild = IntenseCalculating::create();
if (!mpChild)
return procErrLog(-1, "could not create process");
start(mpChild, DrivenByExternalDriver);
ThreadPooling::procAdd(mpChild);
return Positive;
}TODO
- Always the same => Realizes the KISS prinziple
- Code is self-similar => Refactoring is done by just moving code around => No structural changes needed

Q: Isn't this some kind of operating system?
A: No. There is no such thing as an operating system. Every piece of software should be structured this way.
Q: Aren't these micro services?
A: Not exactly. These processes reside in the application itself. They are more similar to Go-/co-routines, tasklets or async-wait structures.
Q: Isn't it ineffective to poll for the result of a child process instead of using callbacks and event driven design?
A: No. Because: TODO