The throughput benchmark test of evpp against libevent
evpp is based on libevent. So we do a benchmark test against libevent is meaningful.
- evpp-v0.2.4 based on libevent-2.0.21
- libevent/server.c and libevent/client.c are taken from libevent based on libevent-2.0.21
- Linux CentOS 6.2, 2.6.32-220.7.1.el6.x86_64
- Intel(R) Xeon(R) CPU E5-2630 v2 @ 2.60GHz
- gcc version 4.8.2 20140120 (Red Hat 4.8.2-15) (GCC)
We use the test method described at http://think-async.com/Asio/LinuxPerformanceImprovements using ping-pong protocol to do the throughput benchmark.
Simply to explains that the ping pong protocol is the client and the server both implements the echo protocol. When the TCP connection is established, the client sends some data to the server, the server echoes the data, and then the client echoes to the server again and again. The data will be the same as the table tennis in the client and the server back and forth between the transfer until one side disconnects. This is a common way to test throughput.
The test code of evpp is at the source code benchmark/throughput/evpp, and at here https://github.com/Qihoo360/evpp/tree/master/benchmark/throughput/evpp. We use tools/benchmark-build.sh to compile it. The test script is single_thread.sh.
The test code of libevent is at the source code benchmark/throughput/libevent, and at here libevent/server.c and libevent/client.c. The test script is single_thread.sh
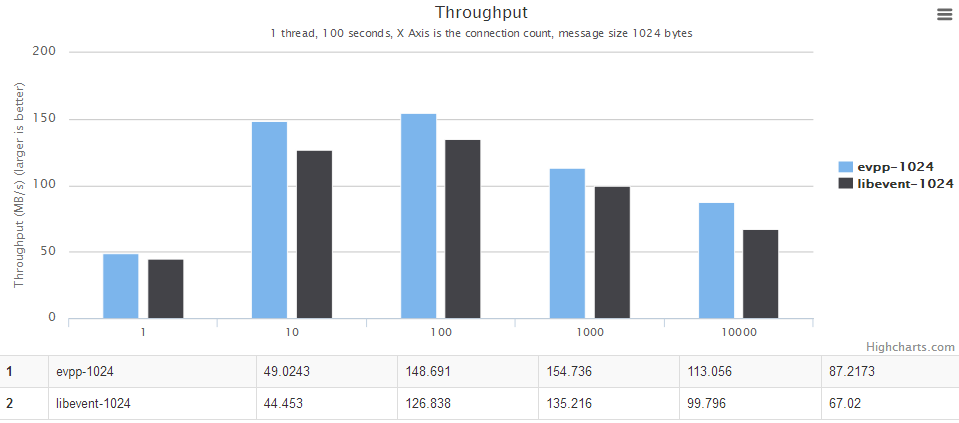
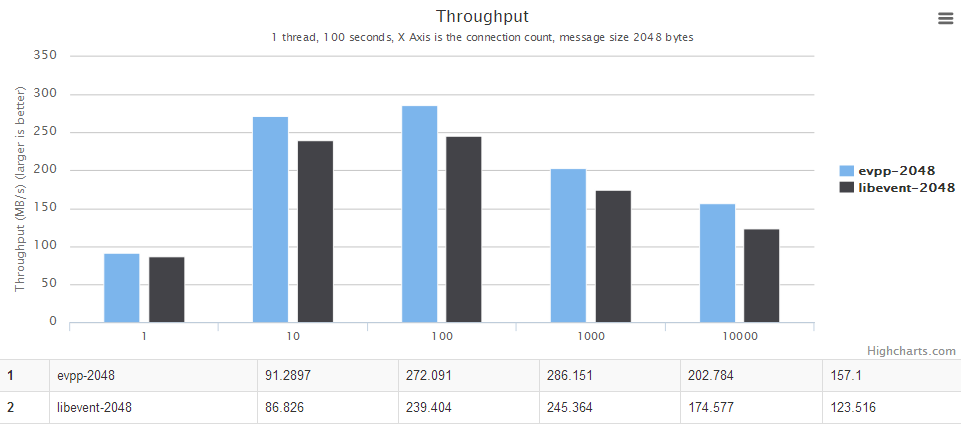
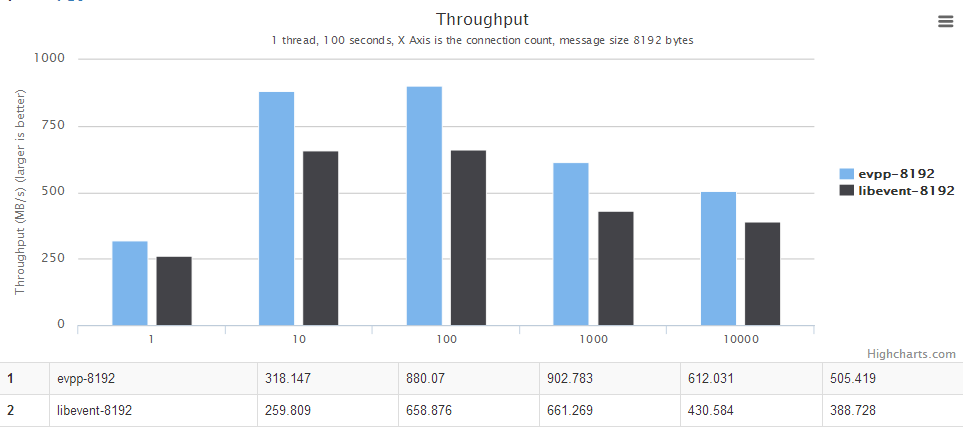
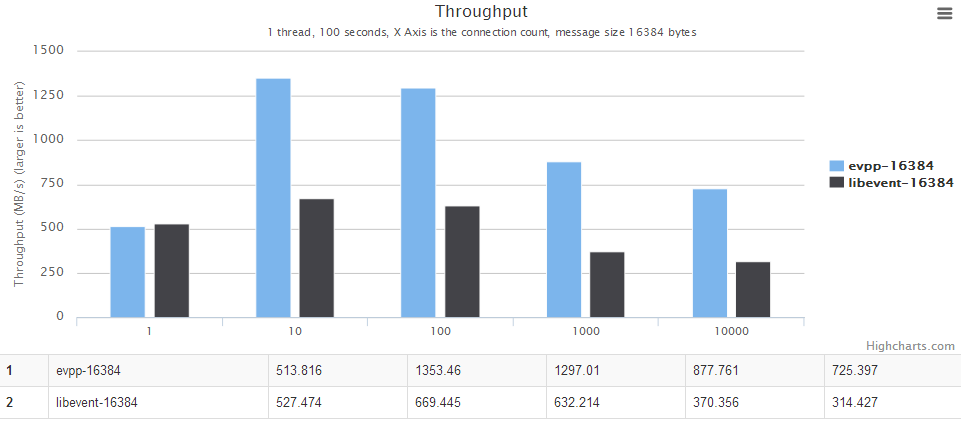
- When message is less than 4096, the throughput benchmark of evpp is about 17% higher than libevent2.
- When the message is larger than 4096, evpp is much faster than libevent, about 40%~130% higher than libevent2
Although evpp is based on libevent, evpp has a better throughput benchmark than libevent. There are two reasons:
- evpp implements its own IO buffer instead of libevent's evbuffer.
- libevent will read 4096 bytes at most every time, that is the key point why libevent is much slower than evpp.
For details, see the chart below, the horizontal axis is the number of concurrent connections. The vertical axis is the throughput, the bigger the better.

The IO Event performance benchmark against Boost.Asio : evpp is higher than asio about 20%~50% in this case
The ping-pong benchmark against Boost.Asio : evpp is higher than asio about 5%~20% in this case
The throughput benchmark against libevent2 : evpp is higher than libevent about 17%~130% in this case
The performance benchmark of queue with std::mutex against boost::lockfree::queue and moodycamel::ConcurrentQueue : moodycamel::ConcurrentQueue is the best, the average is higher than boost::lockfree::queue about 25%~100% and higher than queue with std::mutex about 100%~500%
The throughput benchmark against Boost.Asio : evpp and asio have the similar performance in this case
The throughput benchmark against Boost.Asio(中文) : evpp and asio have the similar performance in this case
The throughput benchmark against muduo(中文) : evpp and muduo have the similar performance in this case
The beautiful chart is rendered by gochart. Thanks for your reading this report. Please feel free to discuss with us for the benchmark test.