![]()
By Dominik Krupke, TU Braunschweig
Many combinatorially difficult optimization problems can, despite their proven theoretical hardness, be solved reasonably well in practice. The most successful approach is to use Mixed Integer Linear Programming (MIP) to model the problem and then use a solver to find a solution. The most successful solvers for MIPs are Gurobi and CPLEX, which are both commercial and expensive (though, free for academics). There are also some open source solvers, but they are often not as powerful as the commercial ones. However, even when investing in such a solver, the underlying techniques (Branch and Bound & Cut on Linear Relaxations) struggle with some optimization problems, especially if the problem contains a lot of logical constraints that a solution has to satisfy. In this case, the Constraint Programming (CP) approach may be more successful. For Constraint Programming, there are many open source solvers, but they usually do not scale as well as MIP-solvers and are worse in optimizing objective functions. While MIP-solvers are frequently able to optimize problems with hundreds of thousands of variables and constraints, the classical CP-solvers often struggle with problems with more than a few thousand variables and constraints. However, the relatively new CP-SAT of Google's OR-Tools suite shows to overcome many of the weaknesses and provides a viable alternative to MIP-solvers, being competitive for many problems and sometimes even superior.
This unofficial primer shall help you use and understand this powerful tool, especially if you are coming from the Mixed Integer Linear Programming -community, as it may prove useful in cases where Branch and Bound performs poorly.
If you are relatively new to combinatorial optimization, I suggest you to read the relatively short book In Pursuit of the Traveling Salesman by Bill Cook first. It tells you a lot about the history and techniques to deal with combinatorial optimization problems, on the example of the famous Traveling Salesman Problem. The Traveling Salesman Problem seems to be intractable already for small instances, but it is actually possible to solve instances with thousands of cities in practice. It is a very light read and you can skip the more technical parts if you want to. As an alternative, you can also read this free chapter, coauthored by the same author and watch this very amusing YouTube Video (1hour). If you are short on time, at least watch the video, it is really worth it. While CP-SAT follows a slightly different approach than the one described in the book/chapter/video, it is still important to see why it is possible to do the seemingly impossible and solve such problems in practice, despite their theoretical hardness. Additionally, you will have learned the concept of Mathematical Programming, and know that the term "Programming" has nothing to do with programming in the sense of writing code (otherwise, additionally read the just given reference). The course Discrete Optimization on Coursera with Pascal Van Hentenryck and Carleton Coffrin is also highly recommendable and gives you an intense crash course on nearly all important topics in applied combinatorial optimization. After that (or if you are already familiar with combinatorial optimization), the following content awaits you in this primer:
Content:
- Installation: Quick installation guide.
- Example: A short example, showing the usage of CP-SAT.
- Modelling: An overview of variables, objectives, and constraints. The constraints make the most important part.
- Parameters: How to specify CP-SATs behavior, if needed. Timelimits, hints, assumptions, parallelization, ...
- Coding Patterns: Basic design patterns for creating maintainable algorithms.
- How does it work?: After we know what we can do with CP-SAT, we look into how CP-SAT will do all these things.
- Alternatives: An overview of the different optimization techniques and tools available. Putting CP-SAT into context.
- Benchmarking your Model: How to benchmark your model and how to interpret the results.
- Large Neighborhood Search: The use of CP-SAT to create more powerful heuristics.
Target audience: People (especially my students at TU Braunschweig) with some background in integer programming /linear optimization, who would like to know an actual viable alternative to Branch and Cut. However, I try to make it understandable for anyone interested in combinatorial optimization.
About the Main Author: Dr. Dominik Krupke is a postdoctoral researcher with the Algorithms Group at TU Braunschweig. He specializes in practical solutions to NP-hard problems. Initially focused on theoretical computer science, he now applies his expertise to solve what was once deemed impossible. This primer, first developed as course material for his students, has been extended in his spare time to cater to a wider audience.
Found a mistake? Please open an issue or a pull request. You can also just write me a quick mail to
krupked@gmail.com.
Want to Contribute? If you are interested in contributing, please open an issue or email me with a brief description of your proposal. We can then discuss the details. I welcome all assistance and am open to expanding the content. Contributors to any section or similar input will be recognized as coauthors.
Want to use/share this content? This tutorial can be freely used under CC-BY 4.0. Smaller parts can even be copied without any acknowledgement for non-commercial, educational purposes.
Why are there so many platypuses in the text? I enjoy incorporating elements in my texts that add a light-hearted touch. The choice of the platypus is intentional: much like CP-SAT integrates diverse elements from various domains, the platypus combines traits from different animals. It is a unique mammal that lays eggs, possesses a beak, and is venomous. The platypus also symbolizes Australia, home to the development of a key technique in CP-SAT - Lazy Clause Generation (LCG). Also, I like platypuses, and hope to see a real one someday.
We are using Python 3 in this primer and assume that you have a working Python 3 installation as well as the basic knowledge to use it. There are also interfaces for other languages, but Python 3 is, in my opinion, the most convenient one, as the mathematical expressions in Python are very close to the mathematical notation (allowing you to spot mathematical errors much faster). Only for huge models, you may need to use a compiled language such as C++ due to performance issues. For smaller models, you will not notice any performance difference.
The installation of CP-SAT, which is part of the OR-Tools package, is very easy and can be done via Python's package manager pip.
pip3 install -U ortoolsThis command will also update an existing installation of OR-Tools. As this tool is in active development, it is recommended to update it frequently. We actually encountered wrong behavior, i.e., bugs, in earlier versions that then have been fixed by updates (this was on some more advanced features, do not worry about correctness with basic usage).
I personally like to use Jupyter Notebooks for experimenting with CP-SAT.
It is important to note that for CP-SAT usage, you do not need the capabilities of a supercomputer. A standard laptop is often sufficient for solving many problems. The primary requirements are CPU power and memory bandwidth, with a GPU being unnecessary.
In terms of CPU power, the key is balancing the number of cores with the performance of each individual core. CP-SAT leverages all available cores, implementing different strategies on each. Depending on the number of cores, CP-SAT will behave differently. However, the effectiveness of these strategies can vary, and it is usually not apparent which one will be most effective. A higher single-core performance means that your primary strategy will operate more swiftly. I recommend a minimum of 4 cores and 16GB of RAM.
While CP-SAT is quite efficient in terms of memory usage, the amount of available memory can still be a limiting factor in the size of problems you can tackle. When it came to setting up our lab for extensive benchmarking at TU Braunschweig, we faced a choice between desktop machines and more expensive workstations or servers. We chose desktop machines equipped with AMD Ryzen 9 7900 CPUs (Intel would be equally suitable) and 96GB of DDR5 RAM, managed using Slurm. This decision was driven by the fact that the performance gains from higher-priced workstations or servers were relatively marginal compared to their significantly higher costs. When on the road, I am often still able to do stuff with my old Intel Macbook Pro from 2018 with an i7 and only 16GB of RAM, but large models will overwhelm it. My workstation at home with AMD Ryzen 7 5700X and 32GB of RAM on the other hand rarely has any problems with the models I am working on.
For further guidance, consider the hardware recommendations for the Gurobi solver, which are likely to be similar. Since we frequently use Gurobi in addition to CP-SAT, our hardware choices were also influenced by their recommendations.
Before we dive into any internals, let us take a quick look at a simple application of CP-SAT. This example is so simple that you could solve it by hand, but know that CP-SAT would (probably) be fine with you adding a thousand (maybe even ten- or hundred-thousand) variables and constraints more. The basic idea of using CP-SAT is, analogous to MIPs, to define an optimization problem in terms of variables, constraints, and objective function, and then let the solver find a solution for it. We call such a formulation that can be understood by the corresponding solver a model for the problem. For people not familiar with this declarative approach, you can compare it to SQL, where you also just state what data you want, not how to get it. However, it is not purely declarative, because it can still make a huge(!) difference how you model the problem and getting that right takes some experience and understanding of the internals. You can still get lucky for smaller problems (let us say a few hundred to thousands of variables) and obtain optimal solutions without having an idea of what is going on. The solvers can handle more and more 'bad' problem models effectively with every year.
Definition: A model in mathematical programming refers to a mathematical description of a problem, consisting of variables, constraints, and optionally an objective function that can be understood by the corresponding solver class. Modelling refers to transforming a problem (instance) into the corresponding framework, e.g., by making all constraints linear as required for Mixed Integer Linear Programming. Be aware that the SAT-community uses the term model to refer to a (feasible) variable assignment, i.e., solution of a SAT-formula. If you struggle with this terminology, maybe you want to read this short guide on Math Programming Modelling Basics.
Our first problem has no deeper meaning, except of showing the basic workflow of
creating the variables (x and y), adding the constraint
from ortools.sat.python import cp_model
model = cp_model.CpModel()
# Variables
x = model.NewIntVar(0, 100, "x") # you always need to specify an upper bound.
y = model.NewIntVar(0, 100, "y")
# there are also no continuous variables: You have to decide for a resolution and then work on integers.
# Constraints
model.Add(x + y <= 30)
# Objective
model.Maximize(30 * x + 50 * y)
# Solve
solver = cp_model.CpSolver() # Contrary to Gurobi, model and solver are separated.
status = solver.Solve(model)
assert (
status == cp_model.OPTIMAL
) # The status tells us if we were able to compute a solution.
print(f"x={solver.Value(x)}, y={solver.Value(y)}")
print("=====Stats:======")
print(solver.SolutionInfo())
print(solver.ResponseStats())x=0, y=30
=====Stats:======
default_lp
CpSolverResponse summary:
status: OPTIMAL
objective: 1500
best_bound: 1500
booleans: 1
conflicts: 0
branches: 1
propagations: 0
integer_propagations: 2
restarts: 1
lp_iterations: 0
walltime: 0.00289923
usertime: 0.00289951
deterministic_time: 8e-08
gap_integral: 5.11888e-07
Pretty easy, right? For solving a generic problem, not just one specific
instance, you would of course create a dictionary or list of variables and use
something like model.Add(sum(vars)<=n), because you do not want to create the
model by hand for larger instances.
The output you get may differ from the one above, because CP-SAT actually uses a set of different strategies in parallel, and just returns the best one (which can differ slightly between multiple runs due to additional randomness). This is called a portfolio strategy and is a common technique in combinatorial optimization, if you cannot predict which strategy will perform best.
In a later section, we will explore how to review and interpret the CP-SAT solver's log. Analyzing the log is vital, especially when the solver's performance is suboptimal. An expert can often pinpoint the cause of any issues within seconds by examining the log, which is key to optimizing solver efficiency.
The mathematical model of the code above would usually be written by experts something like this:
The s.t. stands for subject to, sometimes also read as such that.
One aspect of using CP-SAT solver that often poses challenges for learners is
understanding operator overloading in Python and the distinction between the two
types of variables involved. In this context, x and y serve as mathematical
variables. That is, they are placeholders that will only be assigned specific
values during the solving phase. To illustrate this more clearly, let us explore
an example within the Python shell:
>>> model = cp_model.CpModel()
>>> x = model.NewIntVar(0, 100, "x")
>>> x
x(0..100)
>>> type(x)
<class 'ortools.sat.python.cp_model.IntVar'>
>>> x + 1
sum(x(0..100), 1)
>>> x + 1 <= 1
<ortools.sat.python.cp_model.BoundedLinearExpression object at 0x7d8d5a765df0>In this example, x is not a conventional number but a placeholder defined to
potentially assume any value between 0 and 100. When 1 is added to x, the
result is a new placeholder representing the sum of x and 1. Similarly,
comparing this sum to 1 produces another placeholder, which encapsulates the
comparison of the sum with 1. These placeholders do not hold concrete values at
this stage but are essential for defining constraints within the model.
Attempting operations like if x + 1 <= 1: print("True") will trigger a
NotImplementedError, as the condition x+1<=1 cannot be evaluated directly.
Although this approach to defining models might initially seem perplexing, it facilitates a closer alignment with mathematical notation, which in turn can make it easier to identify and correct errors in the modeling process.
If you are not yet satisfied, this folder contains many Jupyter Notebooks with examples from the developers.
Ok. Now that you have seen a minimal model, let us next look on what options we have to model a problem. Note that an experienced optimizer may be able to model most problems with just the elements shown above, but showing your intentions may help CP-SAT optimize your problem better. Contrary to Mixed Integer Programming, you also do not need to fine-tune any Big-Ms (a reason to model higher-level constraints, such as conditional constraints that are only enforced if some variable is set to true, in MIPs yourself, because the computer is not very good at that).
![]()
CP-SAT provides us with much more modelling options than the classical
MIP-solver. Instead of just the classical linear constraints (<=, ==, >=), we
have various advanced constraints such as AllDifferent or
AddMultiplicationEquality. This spares you the burden of modelling the logic
only with linear constraints, but also makes the interface more extensive.
Additionally, you have to be aware that not all constraints are equally
efficient. The most efficient constraints are linear or boolean constraints.
Constraints such as AddMultiplicationEquality can be significantly(!!!) more
expensive.
Tip
If you are coming from the MIP-world, you should not overgeneralize your experience to CP-SAT as the underlying techniques are different. It does not rely on the linear relaxation as much as MIP-solvers do. Thus, you can often use modelling techniques that are not efficient in MIP-solvers, but perform reasonably well in CP-SAT. For example, I had a model that required multiple absolute values and performed significantly better in CP-SAT than in Gurobi (despite a manual implementation with relatively tight big-M values).
This primer does not have the space to teach about building good models. In the following, we will primarily look onto a selection of useful constraints. If you want to learn how to build models, you could take a look into the book Model Building in Mathematical Programming by H. Paul Williams which covers much more than you probably need, including some actual applications. This book is of course not for CP-SAT, but the general techniques and ideas carry over. However, it can also suffice to simply look on some other models and try some things out. If you are completely new to this area, you may want to check out modelling for the MIP-solver Gurobi in this video course. Remember that many things are similar to CP-SAT, but not everything (as already mentioned, CP-SAT is especially interesting for the cases where a MIP-solver fails).
The following part does not cover all constraints. You can get a complete
overview by looking into the
official documentation.
Simply go to CpModel and check out the AddXXX and NewXXX methods.
Resources on mathematical modelling (not CP-SAT specific):
- Math Programming Modeling Basics by Gurobi: Get the absolute basics.
- Modeling with Gurobi Python: A video course on modelling with Gurobi. The concepts carry over to CP-SAT.
- Model Building in Mathematical Programming by H. Paul Williams: A complete book on mathematical modelling.
Warning
CP-SAT 9.9 recently changed its API to be more consistent with the commonly
used Python style. Instead of NewIntVar, you can now also use new_int_var.
This primer still uses the old style, but will be updated in the future. I
observed cases where certain methods were not available in one or the other
style, so you may need to switch between them for some versions.
Elements:
- Variables
- Objectives
- Linear Constraints
- Logical Constraints (Propositional Logic)
- Conditional Constraints (Channeling, Reification)
- AllDifferent
- Absolute Values and Max/Min
- Multiplication, Division, and Modulo
- Circuit/Tour-Constraints
- Interval/Packing/Scheduling Constraints
- Piecewise Linear Constraints
There are two important types of variables in CP-SAT: Booleans and Integers (which are actually converted to Booleans, but more on this later). There are also, e.g., interval variables, but they are not as important and can be modelled easily with integer variables. For the integer variables, you have to specify a lower and an upper bound.
# integer variable z with bounds -100 <= z <= 100
z = model.NewIntVar(-100, 100, "z")
# boolean variable b
b = model.NewBoolVar("b")
# implicitly available negation of b:
not_b = b.Not() # will be 1 if b is 0 and 0 if b is 1Tip
Having tight bounds on the integer variables can make a huge impact on the performance. It may be useful to run some optimization heuristics beforehand to get some bounds. Reducing it by a few percent can already pay off for some problems.
There are no continuous/floating point variables (or even constants) in CP-SAT: If you need floating point numbers, you have to approximate them with integers by some resolution. For example, you could simply multiply all values by 100 for a step size of 0.01. A value of 2.35 would then be represented by 235. This could probably be implemented in CP-SAT directly, but doing it explicitly is not difficult, and it has numerical implications that you should be aware of.
The lack of continuous variables may sound like a serious limitation, especially if you have a background in linear optimization (where continuous variables are the "easy part"), but as long as they are not a huge part of your problem, you can often work around it. I had problems with many continuous variables on which I had to apply absolute values and conditional linear constraints, and CP-SAT performed much better than Gurobi, which is known to be very good at continuous variables. In this case, CP-SAT struggled less with the continuous variables (Gurobi's strength), than Gurobi with the logical constraints (CP-SAT's strength). In a further analysis, I noted an only logarithmic increase of the runtime with the resolution. However, there are also problems for which a higher resolution can drastically increase the runtime. The packing problem, which is discussed further below, has the following runtime for different resolutions: 1x: 0.02s, 10x: 0.7s, 100x: 7.6s, 1000x: 75s, 10_000x: >15min. The solution was always the same, just scaled, and there was no objective, i.e., only a feasible solution had to be found. Note that this is just an example, not a representative benchmark. See ./examples/add_no_overlap_2d_scaling.ipynb for the code. If you have a problem with a lot of continuous variables, such as network flow problems, you are probably better served with a MIP-solver.
In my experience, boolean variables are by far the most important variables in many combinatorial optimization problems. Many problems, such as the famous Traveling Salesman Problem, only consist of boolean variables. Implementing a solver specialized on boolean variables by using a SAT-solver as a base, such as CP-SAT, thus, is quite sensible. The resolution of coefficients (in combination with boolean variables) is less critical than for variables.
You might question the need for naming variables in your model. While it is true that CP-SAT would not need named variables to work (as it could just give them automatically generated names), assigning names is incredibly useful for debugging purposes. Solver APIs often create an internal representation of your model, which is subsequently used by the solver. There are instances where you might need to examine this internal model, such as when debugging issues like infeasibility. In such scenarios, having named variables can significantly enhance the clarity of the internal representation, making your debugging process much more manageable.
When dealing with integer variables that you know will only need to take certain values, or when you wish to limit their possible values, domain variables can become interesting. Unlike regular integer variables, domain variables are tailored to represent a specific set of values. This approach can enhance efficiency when the domain - the range of sensible values - is small. However, it may not be the best choice for larger domains.
CP-SAT works by converting all integer variables into boolean variables (warning: simplification). For each potential value, it creates two boolean variables: one indicating whether the integer variable is equal to this value, and another indicating whether it is less than or equal to it. This is called an order encoding. At first glance, this might suggest that using domain variables is always preferable, as it appears to reduce the number of boolean variables needed.
However, CP-SAT employs a lazy creation strategy for these boolean variables. This means it only generates them as needed, based on the solver's decision-making process. Therefore, an integer variable with a wide range - say, from 0 to 100 - will not immediately result in 200 boolean variables. It might lead to the creation of only a few, depending on the solver's requirements.
Limiting the domain of a variable can have drawbacks. Firstly, defining a domain explicitly can be computationally costly and increase the model size drastically as it now need to contain not just a lower and upper bound for a variable but an explicit list of numbers (model size is often a limiting factor). Secondly, by narrowing down the solution space, you might inadvertently make it more challenging for the solver to find a viable solution. First, try to let CP-SAT handle the domain of your variables itself and only intervene if you have a good reason to do so.
If you choose to utilize domain variables for their benefits in specific scenarios, here is how to define them:
from ortools.sat.python import cp_model
# Define a domain with selected values
domain = cp_model.Domain.FromValues([2, 5, 8, 10, 20, 50, 90])
# cam also be done via intervals
domain_2 = cp_model.Domain.FromIntervals([(8, 12), (14, 20)])
# Create a domain variable within this defined domain
x = model.NewIntVarFromDomain(domain, "x")This example illustrates the process of creating a domain variable x that can
only take on the values specified in domain. This method is particularly
useful when you are working with variables that only have a meaningful range of
possible values within your problem's context.
Not every problem actually has an objective, sometimes you only need to find a feasible solution. CP-SAT is pretty good at doing that (MIP-solvers are often not). However, CP-SAT can also optimize pretty well (older constraint programming solver cannot, at least in my experience). You can minimize or maximize a linear expression (use auxiliary variables and constraints to model more complicated expressions).
You can specify the objective function by calling model.Minimize or
model.Maximize with a linear expression.
model.Maximize(30 * x + 50 * y)Let us look on how to model more complicated expressions, using boolean variables and generators.
x_vars = [model.NewBoolVar(f"x{i}") for i in range(10)]
model.Minimize(
sum(i * x_vars[i] if i % 2 == 0 else i * x_vars[i].Not() for i in range(10))
)This objective evaluates to
To implement a lexicographic optimization, you can do multiple rounds and always fix the previous objective as constraint.
model.Maximize(30 * x + 50 * y)
# Lexicographic
solver.Solve(model)
model.Add(30 * x + 50 * y == int(solver.ObjectiveValue())) # fix previous objective
model.Minimize(z) # optimize for second objective
solver.Solve(model)To implement non-linear objectives, you can use auxiliary variables and constraints. For example, you can create a variable that is the absolute value of another variable and then use this variable in the objective.
abs_x = model.NewIntVar(0, 100, "|x|")
model.AddAbsEquality(target=abs_x, expr=x)
model.Minimize(abs_x)The available constraints are discussed next.
These are the classical constraints also used in linear optimization. Remember that you are still not allowed to use floating point numbers within it. Same as for linear optimization: You are not allowed to multiply a variable with anything else than a constant and also not to apply any further mathematical operations.
model.Add(10 * x + 15 * y <= 10)
model.Add(x + z == 2 * y)
# This one actually is not linear but still works.
model.Add(x + y != z)
# For <, > you can simply use <= and -1 because we are working on integers.
model.Add(x <= z - 1) # x < zNote that != can be expected slower than the other (<=, >=, ==)
constraints, because it is not a linear constraint. If you have a set of
mutually != variables, it is better to use AllDifferent (see below) than to
use the explicit != constraints.
Warning
If you use intersecting linear constraints, you may get problems because the intersection point needs to be integral. There is no such thing as a feasibility tolerance as in Mixed Integer Programming-solvers, where small deviations are allowed. The feasibility tolerance in MIP-solvers allows, e.g., 0.763445 == 0.763439 to still be considered equal to counter numerical issues of floating point arithmetic. In CP-SAT, you have to make sure that values can match exactly.
You can actually model logical constraints also as linear constraints, but it may be advantageous to show your intent:
b1 = model.NewBoolVar("b1")
b2 = model.NewBoolVar("b2")
b3 = model.NewBoolVar("b3")
model.AddBoolOr(b1, b2, b3) # b1 or b2 or b3 (at least one)
model.AddBoolAnd(b1, b2.Not(), b3.Not()) # b1 and not b2 and not b3 (all)
model.AddBoolAnd(b1, ~b2, ~b3) # Alternative notation for `Not()`
model.AddBoolXOr(b1, b2, b3) # b1 xor b2 xor b3
model.AddImplication(b1, b2) # b1 -> b2In this context you could also mention AddAtLeastOne, AddAtMostOne, and
AddExactlyOne, but these can also be modelled as linear constraints.
Linear constraints (Add), BoolOr, and BoolAnd support being activated by a condition. This is not only a very helpful constraint for many applications, but it is also a constraint that is highly inefficient to model with linear optimization (Big M Method). My current experience shows that CP-SAT can work much more efficiently with this kind of constraint. Note that you only can use a boolean variable and not directly add an expression, i.e., maybe you need to create an auxiliary variable.
model.Add(x + z == 2 * y).OnlyEnforceIf(b1)
model.Add(x + z == 10).OnlyEnforceIf([b2, b3.Not()]) # only enforce if b2 AND NOT b3
# Restrict domain of linear expression on condition
x_b = model.NewBoolVar("x_b")
x_i = model.NEwIntVar(0, 100, "x_i")
domain = model.Domain.FromValues([0, 10, 20, 30, 40, 50])
model.AddLinearExpressionInDomain(x_i, domain).OnlyEnforceIf(x_b)A constraint that is often seen in Constraint Programming, but I myself was always able to deal without it. Still, you may find it important. It forces all (integer) variables to have a different value.
AllDifferent is actually the only constraint that may use a domain based
propagator (if it is not a permutation)
[source]
model.AddAllDifferent(x, y, z)
# You can also add a constant to the variables.
vars = [model.NewIntVar(0, 10) for i in range(10)]
model.AddAllDifferent(x + i for i, x in enumerate(vars))The N-queens example of the official tutorial makes use of this constraint.
There is a big caveat with this constraint: CP-SAT now has a preprocessing step
that automatically tries to infer large AllDifferent constraints from sets of
mutual != constraints. This inference equals the NP-hard Edge Clique Cover
problem, thus, is not a trivial task. If you add an AllDifferent constraint
yourself, CP-SAT will assume that you already took care of this inference and
will skip this step. Thus, adding a single AllDifferent constraint can make
your model significantly slower, if you also use != constraints. If you do not
use != constraints, you can safely use AllDifferent without any performance
penalty. You may also want to use != instead of AllDifferent if you apply it
to overlapping sets of variables without proper optimization, because then
CP-SAT will do the inference for you.
In
./examples/add_all_different.ipynb
you can find a quick experiment based on the graph coloring problem. In the
graph coloring problem, the colors of two adjacent vertices have to be
different. This can be easily modelled by != or AllDifferent constraints on
every edge. Using !=, we can solve the example graph in around 5 seconds. If
we use AllDifferent, it takes more than 5 minutes. If we manually disable the
AllDifferent inference, it also takes more than 5 minutes. Same if we add just
a single AllDifferent constraint. Thus, if you use AllDifferent do it
properly on large sets, or use != constraints and let CP-SAT infer the
AllDifferent constraints for you.
Maybe CP-SAT will allow you to use AllDifferent without any performance
penalty in the future, but for now, you have to be aware of this. See also
the optimization parameter documentation.
Two often occurring and important operators are absolute values as well as minimum and maximum values. You cannot use operators directly in the constraints, but you can use them via an auxiliary variable and a dedicated constraint. These constraints are more efficient than comparable constraints in classical MIP-solvers, but you should still not overuse them.
# abs_xz == |x+z|
abs_xz = model.NewIntVar(0, 200, "|x+z|") # ub = ub(x)+ub(z)
model.AddAbsEquality(target=abs_xz, expr=x + z)
# max_xyz = max(x,y,z)
max_xyz = model.NewIntVar(0, 100, "max(x,y, z)")
model.AddMaxEquality(max_xyz, [x, y, z])
# min_xyz = min(x,y,z)
min_xyz = model.NewIntVar(-100, 100, " min(x,y, z)")
model.AddMinEquality(min_xyz, [x, y, z])Also note that surprisingly often, you can replace these constraints with more efficient linear constraints. Here is one example for the max equality:
x = model.NewIntVar(0, 100, "x")
y = model.NewIntVar(0, 100, "y")
z = model.NewIntVar(0, 100, "z")
# enforce that max_xyz has to be at least the maximum of x, y, z
max_xyz = model.NewIntVar(0, 100, "max_xyz")
model.Add(max_xyz >= x)
model.Add(max_xyz >= y)
model.Add(max_xyz >= z)
# as we minimized max_xyz, it has to be the maximum of x, y, z
model.Minimize(max_xyz)This example illustrates that enforcing the exact maximum value is not always
necessary; a lower bound suffices. By minimizing the variable, the model itself
enforces tightness. Although this approach requires more constraints, it
utilizes constraints that are significantly more efficient than the
AddMaxEquality constraint, typically resulting in faster solving times.
Additional techniques exist for managing minimum and absolute values, as well as for complex scenarios where the objective function does not directly enforce equality. Experienced optimizers can often swiftly identify opportunities to replace standard constraints with more efficient alternatives. However, employing these advanced techniques should follow the acquisition of sufficient experience or the use of a verified base model for comparison. From my consulting experience with optimization models, I have found that resolving issues from improperly applied optimizations frequently requires more time than applying these techniques initially to a model that uses the less efficient constraints.
A big nono in linear optimization (the most successful optimization area) are multiplication of variables (because this would no longer be linear, right...). Often we can linearize the model by some tricks and tools like Gurobi are also able to do some non-linear optimization ( in the end, it is most often translated to a less efficient linear model again). CP-SAT can also work with multiplication and modulo of variables, again as constraint not as operation. So far, I have not made good experience with these constraints, i.e., the models end up being slow to solve, and would recommend to only use them if you really need them and cannot find a way around them.
xyz = model.NewIntVar(-100 * 100 * 100, 100**3, "x*y*z")
model.AddMultiplicationEquality(xyz, [x, y, z]) # xyz = x*y*z
model.AddModuloEquality(x, y, 3) # x = y % 3
model.AddDivisionEquality(x, y, z) # x = y // zYou can very often approximate these constraints with significantly more efficient linear constraints, even if it may require some additional variables or reification. Doing a piecewise linear approximation can be an option even for more complex functions, though they too are not necessarily efficient.
Certain quadratic constraints, e.g., second-order cones, can be efficiently handled by interior point methods, as utilized by the Gurobi solver. However, CP-SAT currently lacks this capability and needs to do significantly more work to handle these constraints. Long story short, if you can avoid these constraints, you should do so, even if you have to give up on modelling the exact function you had in mind.
Warning
The documentation indicates that multiplication of more than two variables is supported, but I got an error when trying it out. I have not investigated this further, as I would expect it to be painfully slow anyway.
The Traveling Salesman Problem (TSP) or Hamiltonicity Problem are important and difficult problems that occur as subproblem in many contexts. For solving the classical TSP, you should use the extremely powerful solver Concorde. There is also a separate part in OR-Tools dedicated to routing. If it is just a subproblem, you can add a simple constraint by encoding the allowed edges as triples of start vertex index, target vertex index, and literal/variable. Note that this is using directed edges/arcs. By adding a triple (v,v,var), you can allow CP-SAT to skip the vertex v.
Tip
If the tour-problem is the fundamental part of your problem, you may be better served with using a Mixed Integer Programming solver. Do not expect to solve tours much larger than 250 vertices with CP-SAT.
from ortools.sat.python import cp_model
# Weighted, directed graph as instance
# (source, destination) -> cost
dgraph = {
(0, 1): 13,
(1, 0): 17,
(1, 2): 16,
(2, 1): 19,
(0, 2): 22,
(2, 0): 14,
(3, 0): 15,
(3, 1): 28,
(3, 2): 25,
(0, 3): 24,
(1, 3): 11,
(2, 3): 27,
}
model = cp_model.CpModel()
# Variables: Binary decision variables for the edges
edge_vars = {(u, v): model.NewBoolVar(f"e_{u}_{v}") for (u, v) in dgraph.keys()}
# Constraints: Add Circuit constraint
# We need to tell CP-SAT which variable corresponds to which edge.
# This is done by passing a list of tuples (u,v,var) to AddCircuit.
circuit = [
(u, v, var) for (u, v), var in edge_vars.items() # (source, destination, variable)
]
model.AddCircuit(circuit)
# Objective: minimize the total cost of edges
obj = sum(dgraph[(u, v)] * x for (u, v), x in edge_vars.items())
model.Minimize(obj)
# Solve
solver = cp_model.CpSolver()
status = solver.Solve(model)
assert status in (cp_model.OPTIMAL, cp_model.FEASIBLE)
tour = [(u, v) for (u, v), x in edge_vars.items() if solver.Value(x)]
print("Tour:", tour)Tour: [(0, 1), (2, 0), (3, 2), (1, 3)]
You can use this constraint very flexibly for many tour problems. We added three examples:
- ./examples/add_circuit.py: The example above, slightly extended. Find out how large you can make the graph.
- ./examples/add_circuit_budget.py: Find the largest tour with a given budget. This will be a bit more difficult to solve.
-
./examples/add_circuit_multi_tour.py:
Allow
$k$ tours, which in sum need to be minimal and cover all vertices.
The most powerful TSP-solver concorde uses a linear programming based
approach, but with a lot of additional techniques to improve the performance.
The book In Pursuit of the Traveling Salesman by William Cook may have already
given you some insights. For more details, you can also read the more advanced
book The Traveling Salesman Problem: A Computational Study by Applegate,
Bixby, Chvatál, and Cook. If you need to solve some variant, MIP-solvers (which
could be called a generalization of that approach) are known to perform well
using the
Dantzig-Fulkerson-Johnson Formulation.
This model is theoretically exponential, but using lazy constraints (which are
added when needed), it can be solved efficiently in practice. The
Miller-Tucker-Zemlin formulation
allows a small formulation size, but is bad in practice with MIP-solvers due to
its weak linear relaxations. Because CP-SAT does not allow lazy constraints, the
Danzig-Fulkerson-Johnson formulation would require many iterations and a lot of
wasted resources. As CP-SAT does not suffer as much from weak linear relaxations
(replacing Big-M by logic constraints, such as OnlyEnforceIf), the
Miller-Tucker-Zemlin formulation may be an option in some cases, though a simple
experiment (see below) shows a similar performance as the iterative approach.
When using AddCircuit, CP-SAT will actually use the LP-technique for the
linear relaxation (so using this constraint may really help, as otherwise CP-SAT
will not know that your manual constraints are actually a tour with a nice
linear relaxation), and probably has the lazy constraints implemented
internally. Using the AddCircuit constraint is thus highly recommendable for
any circle or path constraints.
In ./examples/add_circuit_comparison.ipynb, we compare the performance of some models for the TSP, to estimate the performance of CP-SAT for the TSP.
- AddCircuit can solve the Euclidean TSP up to a size of around 110 vertices in 10 seconds to optimality.
- MTZ (Miller-Tucker-Zemlin) can solve the eculidean TSP up to a size of around 50 vertices in 10 seconds to optimality.
- Dantzig-Fulkerson-Johnson via iterative solving can solve the eculidean TSP up to a size of around 50 vertices in 10 seconds to optimality.
- Dantzig-Fulkerson-Johnson via lazy constraints in Gurobi can solve the eculidean TSP up to a size of around 225 vertices in 10 seconds to optimality.
This tells you to use a MIP-solver for problems dominated by the tour
constraint, and if you have to use CP-SAT, you should definitely use the
AddCircuit constraint.
Warning
These are all naive implementations, and the benchmark is not very rigorous. These values are only meant to give you a rough idea of the performance. Additionally, this benchmark was regarding proving optimality. The performance in just optimizing a tour could be different. The numbers could also look different for differently generated instances. You can find a more detailed benchmark in the later section on proper evaluation.
Here is the performance of AddCircuit for the TSP on some instances (rounded
eucl. distance) from the TSPLIB with a time limit of 90 seconds.
| Instance | # nodes | runtime | lower bound | objective | opt. gap |
|---|---|---|---|---|---|
| att48 | 48 | 0.47 | 33522 | 33522 | 0 |
| eil51 | 51 | 0.69 | 426 | 426 | 0 |
| st70 | 70 | 0.8 | 675 | 675 | 0 |
| eil76 | 76 | 2.49 | 538 | 538 | 0 |
| pr76 | 76 | 54.36 | 108159 | 108159 | 0 |
| kroD100 | 100 | 9.72 | 21294 | 21294 | 0 |
| kroC100 | 100 | 5.57 | 20749 | 20749 | 0 |
| kroB100 | 100 | 6.2 | 22141 | 22141 | 0 |
| kroE100 | 100 | 9.06 | 22049 | 22068 | 0 |
| kroA100 | 100 | 8.41 | 21282 | 21282 | 0 |
| eil101 | 101 | 2.24 | 629 | 629 | 0 |
| lin105 | 105 | 1.37 | 14379 | 14379 | 0 |
| pr107 | 107 | 1.2 | 44303 | 44303 | 0 |
| pr124 | 124 | 33.8 | 59009 | 59030 | 0 |
| pr136 | 136 | 35.98 | 96767 | 96861 | 0 |
| pr144 | 144 | 21.27 | 58534 | 58571 | 0 |
| kroB150 | 150 | 58.44 | 26130 | 26130 | 0 |
| kroA150 | 150 | 90.94 | 26498 | 26977 | 2% |
| pr152 | 152 | 15.28 | 73682 | 73682 | 0 |
| kroA200 | 200 | 90.99 | 29209 | 29459 | 1% |
| kroB200 | 200 | 31.69 | 29437 | 29437 | 0 |
| pr226 | 226 | 74.61 | 80369 | 80369 | 0 |
| gil262 | 262 | 91.58 | 2365 | 2416 | 2% |
| pr264 | 264 | 92.03 | 49121 | 49512 | 1% |
| pr299 | 299 | 92.18 | 47709 | 49217 | 3% |
| linhp318 | 318 | 92.45 | 41915 | 52032 | 19% |
| lin318 | 318 | 92.43 | 41915 | 52025 | 19% |
| pr439 | 439 | 94.22 | 105610 | 163452 | 35% |
You can even go completely bonkers and work with arrays in your model. The
element at a variable index can be accessed via an AddElement constraint.
The second constraint is actually more of a stable matching in array form. For
two arrays of variables
# ai = [x,y,z][i] assign ai the value of the i-th entry.
ai = model.NewIntVar(-100, 100, "a[i]")
i = model.NewIntVar(0, 2, "i")
model.AddElement(index=i, variables=[x, y, z], target=ai)
model.AddInverse([x, y, z], [z, y, x])A special case of variables are the interval variables, that allow to model intervals, i.e., a span of some length with a start and an end. There are fixed length intervals, flexible length intervals, and optional intervals to model various use cases. These intervals become interesting in combination with the no-overlap constraints for 1D and 2D. We can use this for geometric packing problems, scheduling problems, and many other problems, where we have to prevent overlaps between intervals. These variables are special because they are actually not a variable, but a container that bounds separately defined start, length, and end variables.
from ortools.sat.python import cp_model
start_var = model.NewIntVar(0, 100, "start")
length_var = model.NewIntVar(10, 20, "length")
end_var = model.NewIntVar(0, 100, "end")
is_present_var = model.NewBoolVar("is_present")
# creating an interval of fixed length
fixed_interval = model.NewFixedSizeIntervalVar(
start=start_var, size=10, end=end_var, name="fixed_interval"
)
# creating an interval whose length can be influenced by a variable (more expensive)
flexible_interval = model.NewIntervalVar(
start=start_var, size=length_var, end=end_var, name="flexible_interval"
)
# creating an interval that can be present or not
optional_fixed_interval = model.NewOptionalFixedSizeIntervalVar(
start=start_var,
size=10,
end=end_var,
is_present=is_present_var,
name="optional_fixed_interval",
)
# creating an interval that can be present or not and whose length can be influenced by a variable (most expensive)
optional_interval = model.NewOptionalIntervalVar(
start=start_var,
size=length_var,
end=end_var,
is_present=is_present_var,
name="optional_interval",
)There are now the two no-overlap constraints for 1D and 2D that can be used to prevent overlaps between intervals. The 1D no-overlap constraint is used to prevent overlaps between intervals on a single dimension, e.g., time. The 2D no-overlap constraint is used to prevent overlaps between intervals on two dimensions, e.g., time and resources or for packing rectangles.
# 1D no-overlap constraint
model.AddNoOverlap([__INTERVAL_VARS__])
# 2D no-overlap constraint. The two lists need to have the same length.
model.AddNoOverlap2D(
[__INTERVAL_VARS_FIRST_DIMENSION__], [__INTERVAL_VARS_SECOND_DIMENSION__]
)Let us take a quick look on how we can use this to check if we can pack a set of rectangles into a container without overlaps. This can be an interesting problem in logistics, where we have to pack boxes into a container, or in cutting stock problems, where we have to cut pieces from a larger piece of material.
class RectanglePackingWithoutRotationsModel:
def __init__(self, instance: Instance) -> None:
self.instance = instance
self.model = cp_model.CpModel()
# We have to create the variable for the bottom left corner of the boxes.
# We directly limit their range, such that the boxes are inside the container
self.x_vars = [
self.model.NewIntVar(
0, instance.container.width - box.width, name=f"x1_{i}"
)
for i, box in enumerate(instance.rectangles)
]
self.y_vars = [
self.model.NewIntVar(
0, instance.container.height - box.height, name=f"y1_{i}"
)
for i, box in enumerate(instance.rectangles)
]
# Interval variables are actually more like constraint containers, that are then passed to the no overlap constraint
# Note that we could also make size and end variables, but we do not need them here
x_interval_vars = [
self.model.NewFixedSizeIntervalVar(
start=self.x_vars[i], # the x value of the bottom left corner
size=box.width, # the width of the rectangle
name=f"x_interval_{i}",
)
for i, box in enumerate(instance.rectangles)
]
y_interval_vars = [
self.model.NewFixedSizeIntervalVar(
start=self.y_vars[i], # the y value of the bottom left corner
size=box.height, # the height of the rectangle
name=f"y_interval_{i}",
)
for i, box in enumerate(instance.rectangles)
]
# Enforce that no two rectangles overlap
self.model.AddNoOverlap2D(x_interval_vars, y_interval_vars)
def _extract_solution(self, solver: cp_model.CpSolver) -> Optional[Solution]:
if self.status not in (cp_model.OPTIMAL, cp_model.FEASIBLE):
return None
placements = []
for i, box in enumerate(self.instance.rectangles):
x = solver.Value(self.x_vars[i])
y = solver.Value(self.y_vars[i])
placements.append(Placement(x=x, y=y))
return Solution(placements=placements)
def solve(self, time_limit: float = 900.0):
solver = cp_model.CpSolver()
solver.parameters.log_search_progress = True
solver.parameters.max_time_in_seconds = time_limit
self.status = solver.Solve(self.model)
self.solution = self._extract_solution(solver)
self.upper_bound = solver.BestObjectiveBound()
self.objective_value = solver.ObjectiveValue()
return self.status
def is_infeasible(self):
return self.status == cp_model.INFEASIBLE
def is_feasible(self):
return self.status in (cp_model.OPTIMAL, cp_model.FEASIBLE)The optional intervals with flexible length allow us to even model rotations and instead of just checking if a feasible packing exists, finding the largest possible packing. The code may look a bit more complex, but considering the complexity of the problem, it is still quite simple.
class RectangleKnapsackWithRotationsModel:
def __init__(self, instance: Instance) -> None:
self.instance = instance
self.model = cp_model.CpModel()
# Create coordinates for the placement. We need variables for the begin and end of each rectangle.
# This will also ensure that the rectangles are placed inside the container.
self.bottom_left_x_vars = [
self.model.NewIntVar(0, instance.container.width, name=f"x1_{i}")
for i, box in enumerate(instance.rectangles)
]
self.bottom_left_y_vars = [
self.model.NewIntVar(0, instance.container.height, name=f"y1_{i}")
for i, box in enumerate(instance.rectangles)
]
self.upper_right_x_vars = [
self.model.NewIntVar(0, instance.container.width, name=f"x2_{i}")
for i, box in enumerate(instance.rectangles)
]
self.upper_right_y_vars = [
self.model.NewIntVar(0, instance.container.height, name=f"y2_{i}")
for i, box in enumerate(instance.rectangles)
]
# These variables indicate if a rectangle is rotated or not
self.rotated_vars = [
self.model.NewBoolVar(f"rotated_{i}")
for i in range(len(instance.rectangles))
]
# Depending on if a rectangle is rotated or not, we have to adjust the width and height variables
self.width_vars = [
self.model.NewIntVar(0, max(box.width, box.height), name=f"width_{i}")
for i, box in enumerate(instance.rectangles)
]
self.height_vars = [
self.model.NewIntVar(0, max(box.width, box.height), name=f"height_{i}")
for i, box in enumerate(instance.rectangles)
]
# Here we enforce that the width and height variables are correctly set
for i, box in enumerate(instance.rectangles):
if box.width > box.height:
diff = box.width - box.height
self.model.Add(
self.width_vars[i] == box.width - self.rotated_vars[i] * diff
)
self.model.Add(
self.height_vars[i] == box.height + self.rotated_vars[i] * diff
)
else:
diff = box.height - box.width
self.model.Add(
self.width_vars[i] == box.width + self.rotated_vars[i] * diff
)
self.model.Add(
self.height_vars[i] == box.height - self.rotated_vars[i] * diff
)
# And finally, a variable indicating if a rectangle is packed or not
self.packed_vars = [
self.model.NewBoolVar(f"packed_{i}")
for i in range(len(instance.rectangles))
]
# Interval variables are actually more like constraint containers, that are then passed to the no overlap constraint
# Note that we could also make size and end variables, but we do not need them here
self.x_interval_vars = [
self.model.NewOptionalIntervalVar(
start=self.bottom_left_x_vars[i],
size=self.width_vars[i],
is_present=self.packed_vars[i],
end=self.upper_right_x_vars[i],
name=f"x_interval_{i}",
)
for i, box in enumerate(instance.rectangles)
]
self.y_interval_vars = [
self.model.NewOptionalIntervalVar(
start=self.bottom_left_y_vars[i],
size=self.height_vars[i],
is_present=self.packed_vars[i],
end=self.upper_right_y_vars[i],
name=f"y_interval_{i}",
)
for i, box in enumerate(instance.rectangles)
]
# Enforce that no two rectangles overlap
self.model.AddNoOverlap2D(self.x_interval_vars, self.y_interval_vars)
# maximize the number of packed rectangles
self.model.Maximize(
sum(
box.value * self.packed_vars[i]
for i, box in enumerate(instance.rectangles)
)
)
def _extract_solution(self, solver: cp_model.CpSolver) -> Optional[Solution]:
if self.status not in (cp_model.OPTIMAL, cp_model.FEASIBLE):
return None
placements = []
for i, box in enumerate(self.instance.rectangles):
if solver.Value(self.packed_vars[i]):
placements.append(
Placement(
x=solver.Value(self.bottom_left_x_vars[i]),
y=solver.Value(self.bottom_left_y_vars[i]),
rotated=bool(solver.Value(self.rotated_vars[i])),
)
)
else:
placements.append(None)
return Solution(placements=placements)
def solve(self, time_limit: float = 900.0, opt_tol: float = 0.01):
solver = cp_model.CpSolver()
solver.parameters.log_search_progress = True
solver.parameters.max_time_in_seconds = time_limit
solver.parameters.relative_gap_limit = opt_tol
self.status = solver.Solve(self.model)
self.solution = self._extract_solution(solver)
self.upper_bound = solver.BestObjectiveBound()
self.objective_value = solver.ObjectiveValue()
return self.status |
|---|
| This dense packing was found by CP-SAT in less than 0.3s, which is quite impressive and seems to be more efficient than a naive Gurobi implementation. |
You can find the full code here:
| Problem Variant | Code |
|---|---|
| Deciding feasibility of packing rectangles without rotations | ./evaluations/packing/solver/packing_wo_rotations.py |
| Finding the largest possible packing of rectangles without rotations | ./evaluations/packing/solver/knapsack_wo_rotations.py |
| Deciding feasibility of packing rectangles with rotations | ./evaluations/packing/solver/packing_with_rotations.py |
| Finding the largest possible packing of rectangles with rotations | ./evaluations/packing/solver/knapsack_with_rotations.py |
CP-SAT is good at finding a feasible packing, but incapable of proofing infeasibility in most cases. When using the knapsack variant, it can still pack most of the rectangles even for the larger instances.
 |
|---|
| The number of solved instances for the packing problem (90s time limit). Rotations make things slightly more difficult. None of the used instances were proofed infeasible. |
 |
| However, CP-SAT is able to pack nearly all rectangles even for the largest instances. |
In earlier versions of CP-SAT, the performance of no-overlap constraints was greatly influenced by the resolution. This impact has evolved, yet it remains somewhat inconsistent. In a notebook example, I explored how resolution affects the execution time of the no-overlap constraint in versions 9.3 and 9.8 of CP-SAT. For version 9.3, there is a noticeable increase in execution time as the resolution grows. Conversely, in version 9.8, execution time actually reduces when the resolution is higher, a finding supported by repeated tests. This unexpected behavior suggests that the performance of CP-SAT regarding no-overlap constraints has not stabilized and may continue to vary in upcoming versions.
| Resolution | Runtime (CP-SAT 9.3) | Runtime (CP-SAT 9.8) |
|---|---|---|
| 1x | 0.02s | 0.03s |
| 10x | 0.7s | 0.02s |
| 100x | 7.6s | 1.1s |
| 1000x | 75s | 40.3s |
| 10_000x | >15min | 0.4s |
This notebook was used to create the table above.
However, while playing around with less documented features, I noticed that the performance for the older version can be improved drastically with the following parameters:
solver.parameters.use_energetic_reasoning_in_no_overlap_2d = True
solver.parameters.use_timetabling_in_no_overlap_2d = True
solver.parameters.use_pairwise_reasoning_in_no_overlap_2d = TrueWith the latest version of CP-SAT, I did not notice a significant difference in performance when using these parameters.
In practice, you often have cost functions that are not linear. For example, consider a production problem where you have three different items you produce. Each item has different components, you have to buy. The cost of the components will first decrease with the amount you buy, then at some point increase again as your supplier will be out of stock and you have to buy from a more expensive supplier. Additionally, you only have a certain amount of customers willing to pay a certain price for your product. If you want to sell more, you will have to lower the price, which will decrease your profit.
Let us assume such a function looks like
 |
|---|
| We can model an arbitrary continuous function with a piecewise linear function. Here, we split the original function into a number of straight segments. The accuracy can be adapted to the requirements. The linear segments can then be expressed in CP-SAT. The fewer such segments, the easier it remains to model and solve. |
Using linear constraints (model.Add) and reification (.OnlyEnforceIf), we
can model such a piecewise linear function in CP-SAT. For this we simply use
boolean variables to decide for a segment, and then activate the corresponding
linear constraint via reification. However, this has two problems in CP-SAT, as
shown in the next figure.
 |
|---|
| Even if the function f(x) now consists of linear segments, we cannot simply implement |
-
Problem A: Even if we can express a segment as a linear function, the result of the function may not be integral. In the example,
$f(5)$ would be$3.5$ and, thus, if we enforce$y=f(x)$ ,$x$ would be prohibited to be$5$ , which is not what we want. There are two options now. Either, we use a more complex piecewise linear approximation that ensures that the function will always yield integral solutions or we use inequalities instead. The first solution has the issue that this can require too many segments, making it far too expensive to optimize. The second solution will be a weaker constraint as now we can only enforce$y<=f(x)$ or$y>=f(x)$ , but not$y=f(x)$ . If you try to enforce it by$y<=f(x)$ and$y>=f(x)$ , you will end with the same infeasibility as before. However, often an inequality will be enough. If the problem is to prevent$y$ from becoming too large, you use$y<=f(x)$ , if the problem is to prevent$y$ from becoming too small, you use$y>=f(x)$ . If we want to represent the costs by$f(x)$ , we would use$y>=f(x)$ to minimize the costs. -
Problem B: The canonical representation of a linear function is
$y=ax+b$ . However, this will often require non-integral coefficients. Luckily, we can automatically scale them up to integral values by adding a scaling factor. The inequality$y=0.5x+0.5$ in the example can also be represented as$2y=x+1$ . I will spare you the math, but it just requires a simple trick with the least common multiple. Of course, the required scaling factor can become large, and at some point lead to overflows.
An implementation could now look as follows:
# We want to enforce y=f(x)
x = model.NewIntVar(0, 7, "x")
y = model.NewIntVar(0, 5, "y")
# use boolean variables to decide for a segment
segment_active = [model.NewBoolVar("segment_1"), model.NewBoolVar("segment_2")]
model.AddAtMostOne(segment_active) # enforce one segment to be active
# Segment 1
# if 0<=x<=3, then y >= 0.5*x + 0.5
model.Add(2 * y >= x + 1).OnlyEnforceIf(segment_active[0])
model.Add(x >= 0).OnlyEnforceIf(segment_active[0])
model.Add(x <= 3).OnlyEnforceIf(segment_active[0])
# Segment 2
model.Add(_SLIGHTLY_MORE_COMPLEX_INEQUALITY_).OnlyEnforceIf(segment_active[1])
model.Add(x >= 3).OnlyEnforceIf(segment_active[1])
model.Add(x <= 7).OnlyEnforceIf(segment_active[1])
model.Minimize(y)
# if we were to maximize y, we would have used <= instead of >=This can be quite tedious, but luckily, I wrote a small helper class that will do this automatically for you. You can find it in ./utils/piecewise_functions. Simply copy it into your code.
This code does some further optimizations:
- Considering every segment as a separate case can be quite expensive and inefficient. Thus, it can make a serious difference if you can combine multiple segments into a single case. This can be achieved by detecting convex ranges, as the constraints of convex areas do not interfere with each other.
- Adding the convex hull of the segments as a redundant constraint that does
not depend on any
OnlyEnforceIfcan in some cases help the solver to find better bounds.OnlyEnforceIf-constraints are often not very good for the linear relaxation, and having the convex hull as independent constraint can directly limit the solution space, without having to do any branching on the cases.
Let us use this code to solve an instance of the problem above.
We have two products that each require three components. The first product requires 3 of component 1, 5 of component 2, and 2 of component 3. The second product requires 2 of component 1, 1 of component 2, and 3 of component 3. We can buy up to 1500 of each component for the price given in the figure below. We can produce up to 300 of each product and sell them for the price given in the figure below.
 |
 |
|---|---|
| Costs for buying components necessary for production. | Selling price for the products. |
We want to maximize the profit, i.e., the selling price minus the costs for buying the components. We can model this as follows:
requirements_1 = (3, 5, 2)
requirements_2 = (2, 1, 3)
from ortools.sat.python import cp_model
model = cp_model.CpModel()
buy_1 = model.NewIntVar(0, 1_500, "buy_1")
buy_2 = model.NewIntVar(0, 1_500, "buy_2")
buy_3 = model.NewIntVar(0, 1_500, "buy_3")
produce_1 = model.NewIntVar(0, 300, "produce_1")
produce_2 = model.NewIntVar(0, 300, "produce_2")
model.Add(produce_1 * requirements_1[0] + produce_2 * requirements_2[0] <= buy_1)
model.Add(produce_1 * requirements_1[1] + produce_2 * requirements_2[1] <= buy_2)
model.Add(produce_1 * requirements_1[2] + produce_2 * requirements_2[2] <= buy_3)
# You can find this code it ./utils!
from piecewise_functions import PiecewiseLinearFunction, PiecewiseLinearConstraint
# Define the functions for the costs
costs_1 = [(0, 0), (1000, 400), (1500, 1300)]
costs_2 = [(0, 0), (300, 300), (700, 500), (1200, 600), (1500, 1100)]
costs_3 = [(0, 0), (200, 400), (500, 700), (1000, 900), (1500, 1500)]
# PiecewiseLinearFunction is a pydantic model and can be serialized easily!
f_costs_1 = PiecewiseLinearFunction(
xs=[x for x, y in costs_1], ys=[y for x, y in costs_1]
)
f_costs_2 = PiecewiseLinearFunction(
xs=[x for x, y in costs_2], ys=[y for x, y in costs_2]
)
f_costs_3 = PiecewiseLinearFunction(
xs=[x for x, y in costs_3], ys=[y for x, y in costs_3]
)
# Define the functions for the gain
gain_1 = [(0, 0), (100, 800), (200, 1600), (300, 2_000)]
gain_2 = [(0, 0), (80, 1_000), (150, 1_300), (200, 1_400), (300, 1_500)]
f_gain_1 = PiecewiseLinearFunction(xs=[x for x, y in gain_1], ys=[y for x, y in gain_1])
f_gain_2 = PiecewiseLinearFunction(xs=[x for x, y in gain_2], ys=[y for x, y in gain_2])
# Create y>=f(x) constraints for the costs
x_costs_1 = PiecewiseLinearConstraint(model, buy_1, f_costs_1, upper_bound=False)
x_costs_2 = PiecewiseLinearConstraint(model, buy_2, f_costs_2, upper_bound=False)
x_costs_3 = PiecewiseLinearConstraint(model, buy_3, f_costs_3, upper_bound=False)
# Create y<=f(x) constraints for the gain
x_gain_1 = PiecewiseLinearConstraint(model, produce_1, f_gain_1, upper_bound=True)
x_gain_2 = PiecewiseLinearConstraint(model, produce_2, f_gain_2, upper_bound=True)
# Maximize the gain minus the costs
model.Maximize(x_gain_1.y + x_gain_2.y - (x_costs_1.y + x_costs_2.y + x_costs_3.y))
solver = cp_model.CpSolver()
solver.parameters.log_search_progress = True
status = solver.Solve(model)
print(f"Buy {solver.Value(buy_1)} of component 1")
print(f"Buy {solver.Value(buy_2)} of component 2")
print(f"Buy {solver.Value(buy_3)} of component 3")
print(f"Produce {solver.Value(produce_1)} of product 1")
print(f"Produce {solver.Value(produce_2)} of product 2")
print(f"Overall gain: {solver.ObjectiveValue()}")This will give you the following output:
Buy 930 of component 1
Buy 1200 of component 2
Buy 870 of component 3
Produce 210 of product 1
Produce 150 of product 2
Overall gain: 1120.0
Unfortunately, these problems quickly get very complicated to model and solve. This is just a proof that, theoretically, you can model such problems in CP-SAT. Practically, you can lose a lot of time and sanity with this if you are not an expert.
CP-SAT has even more constraints, but I think I covered the most important ones. If you need more, you can check out the official documentation.
![]()
The CP-SAT solver has a lot of parameters to control its behavior. They are
implemented via
Protocol Buffer and can be
manipulated via the parameters-member. If you want to find out all options,
you can check the reasonably well documented proto-file in the
official repository.
I will give you the most important right below.
⚠️ Only a few of the parameters (e.g., timelimit) are beginner-friendly. Most other parameters (e.g., decision strategies) should not be touched as the defaults are well-chosen, and it is likely that you will interfere with some optimizations. If you need a better performance, try to improve your model of the optimization problem.
If we have a huge model, CP-SAT may not be able to solve it to optimality (if the constraints are not too difficult, there is a good chance we still get a good solution). Of course, we do not want CP-SAT to run endlessly for hours (years, decades,...) but simply abort after a fixed time and return us the best solution so far. If you are now asking yourself why you should use a tool that may run forever: There are simply no provably faster algorithms and considering the combinatorial complexity, it is incredible that it works so well. Those not familiar with the concepts of NP-hardness and combinatorial complexity, I recommend reading the book 'In Pursuit of the Traveling Salesman' by William Cook. Actually, I recommend this book to anyone into optimization: It is a beautiful and light weekend-read.
To set a time limit (in seconds), we can simply set the following value before we run the solver:
solver.parameters.max_time_in_seconds = 60 # 60s timelimitWe now of course have the problem, that maybe we will not have an optimal solution, or a solution at all, we can continue on. Thus, we need to check the status of the solver.
status = solver.Solve(model)
if status == cp_model.OPTIMAL or status == cp_model.FEASIBLE:
print("We have a solution.")
else:
print("Help?! No solution available! :( ")The following status codes are possible:
OPTIMAL: Perfect, we have an optimal solution.FEASIBLE: Good, we have at least a feasible solution (we may also have a bound available to check the quality viasolver.BestObjectiveBound()).INFEASIBLE: There is a proof that no solution can satisfy all our constraints.MODEL_INVALID: You used CP-SAT wrongly.UNKNOWN: No solution was found, but also no infeasibility proof. Thus, we actually know nothing. Maybe there is at least a bound available?
If you want to print the status, you can use solver.StatusName(status).
We can not only limit the runtime but also tell CP-SAT, we are satisfied with a
solution within a specific, provable quality range. For this, we can set the
parameters absolute_gap_limit and relative_gap_limit. The absolute limit
tells CP-SAT to stop as soon as the solution is at most a specific value apart
to the bound, the relative limit is relative to the bound. More specifically,
CP-SAT will stop as soon as the objective value(O) is within relative ratio
solver.parameters.relative_gap_limit = 0.05Now we may want to stop after we did not make progress for some time or whatever. In this case, we can make use of the solution callbacks.
For those familiar with Gurobi: Unfortunately, we can only abort the solution progress and not add lazy constraints or similar. For those not familiar with Gurobi or MIPs: With Mixed Integer Programming we can adapt the model during the solution process via callbacks which allows us to solve problems with many(!) constraints by only adding them lazily. This is currently the biggest shortcoming of CP-SAT for me. Sometimes you can still do dynamic model building with only little overhead feeding information of previous iterations into the model
For adding a solution callback, we have to inherit from a base class. The documentation of the base class and the available operations can be found in the documentation.
class MySolutionCallback(cp_model.CpSolverSolutionCallback):
def __init__(self, stuff):
cp_model.CpSolverSolutionCallback.__init__(self)
self.stuff = stuff # just to show that we can save some data in the callback.
def on_solution_callback(self):
obj = self.ObjectiveValue() # best solution value
bound = self.BestObjectiveBound() # best bound
print(f"The current value of x is {self.Value(x)}")
if abs(obj - bound) < 10:
self.StopSearch() # abort search for better solution
# ...
solver.Solve(model, MySolutionCallback(None))You can find an official example of using such callbacks .
Beside querying the objective value of the currently best solution, the solution
itself, and the best known bound, you can also find out about internals such as
NumBooleans(self), NumConflicts(self), NumBranches(self). What those
values mean will be discussed later.
With version 9.10, CP-SAT also supports bound callbacks. These are called when CP-SAT is able to improve the proven bound. As the solution callback is only called when a new solution is found, you may want to additionally use the bound callback when you want to abort the search as soon as the bound is good enough.
solver = cp_model.CpSolver()
def bound_callback(bound):
print(f"New bound: {bound}")
if bound > 100:
solver.StopSearch()
solver.best_bound_callback = bound_callbackYou can also try to directly hook into the log output of CP-SAT, which should be
called for new solutions, new bounds, and other important events. This can be
done by setting the log_callback parameter.
solver.log_callback = lambda msg: print("LOG:", msg) # (str)->NoneCP-SAT is a portfolio-solver that uses different techniques to solve the problem. There is some information exchange between the different workers, but it does not split the solution space into different parts, thus, it does not parallelize the branch-and-bound algorithm as MIP-solvers do. This can lead to some redundancy in the search, but running different techniques in parallel will also increase the chance of running the right technique. Predicting which technique will be the best for a specific problem is often hard, thus, this parallelization can be quite useful.
You can control the parallelization of CP-SAT by setting the number of search workers.
solver.parameters.num_search_workers = 8 # use 8 coresHere the solvers used by CP-SAT 9.9 on different parallelization levels for an optimization problem and no additional specifications (e.g., decision strategies). Note that some parameters/constraints/objectives can change the parallelization strategy Also check the official documentation.
solver.parameters.num_search_workers = 1: Single-threaded search with[default_lp].- 1 full problem subsolver: [default_lp]
solver.parameters.num_search_workers = 2: Additional use of heuristics to support thedefault_lpsearch.- 1 full problem subsolver: [default_lp]
- 13 incomplete subsolvers: [feasibility_pump, graph_arc_lns, graph_cst_lns, graph_dec_lns, graph_var_lns, packing_precedences_lns, packing_rectangles_lns, packing_slice_lns, rins/rens, rnd_cst_lns, rnd_var_lns, scheduling_precedences_lns, violation_ls]
- 3 helper subsolvers: [neighborhood_helper, synchronization_agent, update_gap_integral]
solver.parameters.num_search_workers = 3: Using a second full problem solver that does not try to linearize the model.- 2 full problem subsolvers: [default_lp, no_lp]
- 13 incomplete subsolvers: [feasibility_pump, graph_arc_lns, graph_cst_lns, graph_dec_lns, graph_var_lns, packing_precedences_lns, packing_rectangles_lns, packing_slice_lns, rins/rens, rnd_cst_lns, rnd_var_lns, scheduling_precedences_lns, violation_ls]
- 3 helper subsolvers: [neighborhood_helper, synchronization_agent, update_gap_integral]
solver.parameters.num_search_workers = 4: Additionally using a third full problem solver that tries to linearize the model as much as possible.- 3 full problem subsolvers: [default_lp, max_lp, no_lp]
- 13 incomplete subsolvers: [feasibility_pump, graph_arc_lns, graph_cst_lns, graph_dec_lns, graph_var_lns, packing_precedences_lns, packing_rectangles_lns, packing_slice_lns, rins/rens, rnd_cst_lns, rnd_var_lns, scheduling_precedences_lns, violation_ls]
- 3 helper subsolvers: [neighborhood_helper, synchronization_agent, update_gap_integral]
solver.parameters.num_search_workers = 5: Additionally using a first solution subsolver.- 3 full problem subsolvers: [default_lp, max_lp, no_lp]
- 1 first solution subsolver: [fj_short_default]
- 13 incomplete subsolvers: [feasibility_pump, graph_arc_lns, graph_cst_lns, graph_dec_lns, graph_var_lns, packing_precedences_lns, packing_rectangles_lns, packing_slice_lns, rins/rens, rnd_cst_lns, rnd_var_lns, scheduling_precedences_lns, violation_ls]
- 3 helper subsolvers: [neighborhood_helper, synchronization_agent, update_gap_integral]
solver.parameters.num_search_workers = 6: Using a fourth full problem solverquick_restartthat does more "probing".- 4 full problem subsolvers: [default_lp, max_lp, no_lp, quick_restart]
- 1 first solution subsolver: [fj_short_default]
- 13 incomplete subsolvers: [feasibility_pump, graph_arc_lns, graph_cst_lns, graph_dec_lns, graph_var_lns, packing_precedences_lns, packing_rectangles_lns, packing_slice_lns, rins/rens, rnd_cst_lns, rnd_var_lns, scheduling_precedences_lns, violation_ls]
- 3 helper subsolvers: [neighborhood_helper, synchronization_agent, update_gap_integral]
solver.parameters.num_search_workers = 7:- 5 full problem subsolvers: [default_lp, max_lp, no_lp, quick_restart, reduced_costs]
- 1 first solution subsolver: [fj_short_default]
- 13 incomplete subsolvers: [feasibility_pump, graph_arc_lns, graph_cst_lns, graph_dec_lns, graph_var_lns, packing_precedences_lns, packing_rectangles_lns, packing_slice_lns, rins/rens, rnd_cst_lns, rnd_var_lns, scheduling_precedences_lns, violation_ls]
- 3 helper subsolvers: [neighborhood_helper, synchronization_agent, update_gap_integral]
solver.parameters.num_search_workers = 8:- 6 full problem subsolvers: [default_lp, max_lp, no_lp, quick_restart, quick_restart_no_lp, reduced_costs]
- 1 first solution subsolver: [fj_short_default]
- 13 incomplete subsolvers: [feasibility_pump, graph_arc_lns, graph_cst_lns, graph_dec_lns, graph_var_lns, packing_precedences_lns, packing_rectangles_lns, packing_slice_lns, rins/rens, rnd_cst_lns, rnd_var_lns, scheduling_precedences_lns, violation_ls]
- 3 helper subsolvers: [neighborhood_helper, synchronization_agent, update_gap_integral]
solver.parameters.num_search_workers = 12:- 8 full problem subsolvers: [default_lp, lb_tree_search, max_lp, no_lp, pseudo_costs, quick_restart, quick_restart_no_lp, reduced_costs]
- 3 first solution subsolvers: [fj_long_default, fj_short_default, fs_random]
- 13 incomplete subsolvers: [feasibility_pump, graph_arc_lns, graph_cst_lns, graph_dec_lns, graph_var_lns, packing_precedences_lns, packing_rectangles_lns, packing_slice_lns, rins/rens, rnd_cst_lns, rnd_var_lns, scheduling_precedences_lns, violation_ls]
- 3 helper subsolvers: [neighborhood_helper, synchronization_agent, update_gap_integral]
solver.parameters.num_search_workers = 16:- 11 full problem subsolvers: [default_lp, lb_tree_search, max_lp, no_lp, objective_lb_search, objective_shaving_search_no_lp, probing, pseudo_costs, quick_restart, quick_restart_no_lp, reduced_costs]
- 4 first solution subsolvers: [fj_long_default, fj_short_default, fs_random, fs_random_quick_restart]
- 13 incomplete subsolvers: [feasibility_pump, graph_arc_lns, graph_cst_lns, graph_dec_lns, graph_var_lns, packing_precedences_lns, packing_rectangles_lns, packing_slice_lns, rins/rens, rnd_cst_lns, rnd_var_lns, scheduling_precedences_lns, violation_ls]
- 3 helper subsolvers: [neighborhood_helper, synchronization_agent, update_gap_integral]
solver.parameters.num_search_workers = 20:- 13 full problem subsolvers: [default_lp, lb_tree_search, max_lp, no_lp, objective_lb_search, objective_shaving_search_max_lp, objective_shaving_search_no_lp, probing, probing_max_lp, pseudo_costs, quick_restart, quick_restart_no_lp, reduced_costs]
- 5 first solution subsolvers: [fj_long_default, fj_short_default, fj_short_lin_default, fs_random, fs_random_quick_restart]
- 13 incomplete subsolvers: [feasibility_pump, graph_arc_lns, graph_cst_lns, graph_dec_lns, graph_var_lns, packing_precedences_lns, packing_rectangles_lns, packing_slice_lns, rins/rens, rnd_cst_lns, rnd_var_lns, scheduling_precedences_lns, violation_ls]
- 3 helper subsolvers: [neighborhood_helper, synchronization_agent, update_gap_integral]
solver.parameters.num_search_workers = 32:- 15 full problem subsolvers: [default_lp, lb_tree_search, max_lp, no_lp, objective_lb_search, objective_lb_search_max_lp, objective_lb_search_no_lp, objective_shaving_search_max_lp, objective_shaving_search_no_lp, probing, probing_max_lp, pseudo_costs, quick_restart, quick_restart_no_lp, reduced_costs]
- 15 first solution subsolvers: [fj_long_default, fj_long_lin_default, fj_long_lin_random, fj_long_random, fj_short_default, fj_short_lin_default, fj_short_lin_random, fj_short_random, fs_random(2), fs_random_no_lp(2), fs_random_quick_restart(2), fs_random_quick_restart_no_lp]
- 15 incomplete subsolvers: [feasibility_pump, graph_arc_lns, graph_cst_lns, graph_dec_lns, graph_var_lns, packing_precedences_lns, packing_rectangles_lns, packing_slice_lns, rins/rens, rnd_cst_lns, rnd_var_lns, scheduling_precedences_lns, violation_ls(3)]
- 3 helper subsolvers: [neighborhood_helper, synchronization_agent, update_gap_integral]
solver.parameters.num_search_workers = 64:- 15 full problem subsolvers: [default_lp, lb_tree_search, max_lp, no_lp, objective_lb_search, objective_lb_search_max_lp, objective_lb_search_no_lp, objective_shaving_search_max_lp, objective_shaving_search_no_lp, probing, probing_max_lp, pseudo_costs, quick_restart, quick_restart_no_lp, reduced_costs]
- 47 first solution subsolvers: [fj_long_default(2), fj_long_lin_default(2), fj_long_lin_perturb(2), fj_long_lin_random(2), fj_long_perturb(2), fj_long_random(2), fj_short_default(2), fj_short_lin_default(2), fj_short_lin_perturb(2), fj_short_lin_random(2), fj_short_perturb(2), fj_short_random(2), fs_random(6), fs_random_no_lp(6), fs_random_quick_restart(6), fs_random_quick_restart_no_lp(5)]
- 19 incomplete subsolvers: [feasibility_pump, graph_arc_lns, graph_cst_lns, graph_dec_lns, graph_var_lns, packing_precedences_lns, packing_rectangles_lns, packing_slice_lns, rins/rens, rnd_cst_lns, rnd_var_lns, scheduling_precedences_lns, violation_ls(7)]
- 3 helper subsolvers: [neighborhood_helper, synchronization_agent, update_gap_integral]
Important steps:
- With a single worker, only the default subsolver is used.
- With two workers or more, CP-SAT starts using incomplete subsolvers, i.e., heuristics such as LNS.
- With five workers, CP-SAT will also have a first solution subsolver.
- With 23 workers, all 15 full problem subsolvers are used.
- For more than 32 workers, primarily the number of first solution subsolvers is increased.
Full problem subsolvers are solvers that search the full problem space, e.g., by a branch-and-bound algorithm. Available full problem subsolvers are:
default_lp: LCG-based search with default linearization of the model.max_lp: Same asdefault_lpbut with maximal linearization.no_lp: Same asdefault_lpbut without linearization.
lb_tree_search: This solver is focussed on improving the proven bound, not on finding better solutions. By disproving the feasibility of the cheapest nodes in the search tree, it incrementally improves the bound, but has only little chances to find better solutions.objective_lb_search: Also focussed on improving the bound by disproving the feasibility of the current lower bound.objective_lb_search_max_lp: With maximal linearization.objective_lb_search_no_lp: Without linearization.objective_shaving_search_max_lp: Should be quite similar toobjective_lb_search_max_lp.objective_shaving_search_no_lp: Should be quite similar toobjective_lb_search_no_lp.
probing: Fixing variables and seeing what happens.probing_max_lp: Same as probing but with maximal linearization.
pseudo_costs: Uses pseudo costs for branching, which are computed from historical changes in objective bounds following certain branching decisions.quick_restart: Restarts the search more eagerly. Restarts rebuild the search tree from scratch, but keep learned clauses. This allows to recover from bad decisions, and lead to smaller search trees by learning from the mistakes of the past.quick_restart_no_lp: Same asquick_restartbut without linearization.
reduced_costs: Uses the reduced costs of the linear relaxation for branching.core: A strategy from the SAT-community that extracts unsatisfiable cores of the formula.fixed: User-specified search strategy.
You can specify the used full problem subsolvers manually by
# make sure list is empty
while solver.parameters.subsolvers:
solver.parameters.subsolvers.pop()
# set new list
solver.parameters.subsolvers.extend(["default_lp", "fixed", "less_encoding", "no_lp", "max_lp", "pseudo_costs", "reduced_costs", "quick_restart", "quick_restart_no_lp", "lb_tree_search", "probing"])
This can be interesting, e.g., if you are using CP-SAT especially because the
linear relaxation is not useful (and the BnB-algorithm performing badly). There
are even more options, but for these you can simply look into the
documentation.
Be aware that fine-tuning such a solver is not a simple task, and often you do
more harm than good by tinkering around. However, I noticed that decreasing the
number of search workers can actually improve the runtime for some problems.
This indicates that at least selecting the right subsolvers that are best fitted
for your problem can be worth a shot. For example max_lp is probably a waste
of resources if you know that your model has a terrible linear relaxation. In
this context I want to recommend having a look on some relaxed solutions when
dealing with difficult problems to get a better understanding of which parts a
solver may struggle with (use a linear programming solver, like Gurobi, for
this).
You can evaluate the performance of the different strategies by looking at the
Solutions and Objective bounds blocks in the log. Here an example:
Solutions (7) Num Rank
'no_lp': 3 [1,7]
'quick_restart': 1 [3,3]
'quick_restart_no_lp': 3 [2,5]
Objective bounds Num
'initial_domain': 1
'objective_lb_search': 2
'objective_lb_search_no_lp': 4
'objective_shaving_search_no_lp': 1
For solutions, the first number is the number of solutions found by the
strategy, the second number is the range of the ranks of the solutions. The
value [1,7] indicates that the solutions found by the strategy have ranks
between 1 and 7. In this case, it means that the strategy no_lp found the best
and the worst solution.
For objective bounds, the number indicates how often the strategy contributed to
the best bound. For this example, it seems that the no_lp strategies are the
most successful. Note that for both cases, it is more interesting, which
strategies do not appear in the list.
In the search log, you can also see at which time which subsolver contributed something. This log also includes the incomplete and first solution subsolvers.
#1 0.01s best:43 next:[6,42] no_lp (fixed_bools=0/155)
#Bound 0.01s best:43 next:[7,42] objective_shaving_search_no_lp (vars=73 csts=120)
#2 0.01s best:33 next:[7,32] quick_restart_no_lp (fixed_bools=0/143)
#3 0.01s best:31 next:[7,30] quick_restart (fixed_bools=0/123)
#4 0.01s best:17 next:[7,16] quick_restart_no_lp (fixed_bools=2/143)
#5 0.01s best:16 next:[7,15] quick_restart_no_lp (fixed_bools=22/147)
#Bound 0.01s best:16 next:[8,15] objective_lb_search_no_lp
#6 0.01s best:15 next:[8,14] no_lp (fixed_bools=41/164)
#7 0.01s best:14 next:[8,13] no_lp (fixed_bools=42/164)
#Bound 0.01s best:14 next:[9,13] objective_lb_search
#Bound 0.02s best:14 next:[10,13] objective_lb_search_no_lp
#Bound 0.04s best:14 next:[11,13] objective_lb_search_no_lp
#Bound 0.06s best:14 next:[12,13] objective_lb_search
#Bound 0.25s best:14 next:[13,13] objective_lb_search_no_lp
#Model 0.26s var:125/126 constraints:162/162
#Model 2.24s var:124/126 constraints:160/162
#Model 2.58s var:123/126 constraints:158/162
#Model 2.91s var:121/126 constraints:157/162
#Model 2.95s var:120/126 constraints:155/162
#Model 2.97s var:109/126 constraints:140/162
#Model 2.98s var:103/126 constraints:135/162
#Done 2.98s objective_lb_search_no_lp
#Done 2.98s quick_restart_no_lp
#Model 2.98s var:66/126 constraints:91/162
Incomplete subsolvers are solvers that do not search the full problem space,
but work heuristically. Notable strategies are large neighborhood search (LNS)
and feasibility pumps. The first one tries to find a better solution by changing
only a few variables, the second one tries to make infeasible/incomplete
solutions feasible. If you want to use more workers heuristically searching for
good solutions, you can specify solver.parameters.min_num_lns_workers. You can
also run only the incomplete subsolvers by setting
solver.parameters.use_lns_only = True, but this need to be combined with a
time limit, as the incomplete subsolvers do not know when to stop.
First solution subsolvers are strategies that try to find a first solution as fast as possible. They are often used to warm up the solver and to get a first impression of the problem.
If you are interested in how Gurobi parallelizes its search, you can find a great video here. Ed Rothberg also explains the general opportunities and challenges of parallelizing a solver, making it also interesting for understanding the parallelization of CP-SAT.
⚠️ This section could need some help as there is the possibility that I am mixing up some of the strategies, or am drawing wrong connections.
If you want to compare the performance of different parallelization levels or different hardware, you can use the following code snippets to export a model. Instead of having to rebuild the model or share any code, you can then simply load the model on a different machine and run the solver.
from ortools.sat.python import cp_model
from google.protobuf import text_format
def export_model(model: cp_model.CpModel, filename: str):
with open(filename, "w") as file:
file.write(text_format.MessageToString(model.Proto()))
def import_model(filename: str) -> cp_model.CpModel:
model = cp_model.CpModel()
with open(filename, "r") as file:
text_format.Parse(file.read(), model.Proto())
return modelQuite often you want to find out what happens if you force some variables to a
specific value. Because you possibly want to do that multiple times, you do not
want to copy the whole model. CP-SAT has a nice option of adding assumptions
that you can clear afterwards, without needing to copy the object to test the
next assumptions. This is a feature also known from many SAT-solvers and CP-SAT
also only allows this feature for boolean literals. You cannot add any more
complicated expressions here, but for boolean literals it seems to be pretty
efficient. By adding some auxiliary boolean variables, you can also use this
technique to play around with more complicated expressions without the need to
copy the model. If you really need to temporarily add complex constraints, you
may have to copy the model using model.CopyFrom (maybe you also need to copy
the variables. Need to check that.).
model.AddAssumptions([b1, b2.Not()]) # assume b1=True, b2=False
model.AddAssumption(b3) # assume b3=True (single literal)
# ... solve again and analyse ...
model.ClearAssumptions() # clear all assumptionsAn assumption is a temporary fixation of a boolean variable to true or false. It can be efficiently handled by a SAT-solver (and thus probably also by CP-SAT) and does not harm the learned clauses (but can reuse them).
Maybe we already have a good intuition on how the solution will look like (this could be, because we already solved a similar model, have a good heuristic, etc.). In this case it may be useful, to tell CP-SAT about it, so it can incorporate this knowledge into its search. For Mixed Integer Programming Solver, this often yields a visible boost, even with mediocre heuristic solutions. For CP-SAT I actually also encountered downgrades of the performance if the hints were not great (but this may depend on the problem).
model.AddHint(x, 1) # Tell CP-SAT that x will probably be 1
model.AddHint(y, 2) # and y probably be 2.You can also find an official example.
To make sure, your hints are actually correct, you can use the following parameters to make CP-SAT throw an error if your hints are wrong.
solver.parameters.debug_crash_on_bad_hint = TrueIf you have the feeling that your hints are not used, you may have made a logical error in your model or just have a bug in your code. This parameter will tell you about it.
(TODO: Have not tested this, yet)
Sometimes it is useful to activate logging to see what is going on. This can be achieved by setting the following two parameters.
solver = cp_model.CpSolver()
solver.parameters.log_search_progress = True
solver.log_callback = print # (str)->NoneIf you get a doubled output, remove the last line.
The output can look as follows:
Starting CP-SAT solver v9.3.10497
Parameters: log_search_progress: true
Setting number of workers to 16
Initial optimization model '':
#Variables: 290 (#ints:1 in objective)
- 290 in [0,17]
#kAllDiff: 34
#kLinMax: 1
#kLinear2: 2312 (#complex_domain: 2312)
Starting presolve at 0.00s
[ExtractEncodingFromLinear] #potential_supersets=0 #potential_subsets=0 #at_most_one_encodings=0 #exactly_one_encodings=0 #unique_terms=0 #multiple_terms=0 #literals=0 time=9.558e-06s
[Probing] deterministic_time: 0.053825 (limit: 1) wall_time: 0.0947566 (12427/12427)
[Probing] - new integer bounds: 1
[Probing] - new binary clause: 9282
[DetectDuplicateConstraints] #duplicates=0 time=0.00993671s
[DetectDominatedLinearConstraints] #relevant_constraints=2312 #work_done=14118 #num_inclusions=0 #num_redundant=0 time=0.0013379s
[DetectOverlappingColumns] #processed_columns=0 #work_done=0 #nz_reduction=0 time=0.00176239s
[ProcessSetPPC] #relevant_constraints=612 #num_inclusions=0 work=29376 time=0.0022503s
[Probing] deterministic_time: 0.0444515 (limit: 1) wall_time: 0.0820382 (11849/11849)
[Probing] - new binary clause: 9282
[DetectDuplicateConstraints] #duplicates=0 time=0.00786558s
[DetectDominatedLinearConstraints] #relevant_constraints=2312 #work_done=14118 #num_inclusions=0 #num_redundant=0 time=0.000688681s
[DetectOverlappingColumns] #processed_columns=0 #work_done=0 #nz_reduction=0 time=0.000992311s
[ProcessSetPPC] #relevant_constraints=612 #num_inclusions=0 work=29376 time=0.00121334s
Presolve summary:
- 0 affine relations were detected.
- rule 'all_diff: expanded' was applied 34 times.
- rule 'deductions: 10404 stored' was applied 1 time.
- rule 'linear: simplified rhs' was applied 7514 times.
- rule 'presolve: 0 unused variables removed.' was applied 1 time.
- rule 'presolve: iteration' was applied 2 times.
- rule 'variables: add encoding constraint' was applied 5202 times.
Presolved optimization model '':
#Variables: 5492 (#ints:1 in objective)
- 5202 in [0,1]
- 289 in [0,17]
- 1 in [1,17]
#kAtMostOne: 612 (#literals: 9792)
#kLinMax: 1
#kLinear1: 10404 (#enforced: 10404)
#kLinear2: 2312 (#complex_domain: 2312)
Preloading model.
#Bound 0.45s best:inf next:[1,17] initial_domain
Starting Search at 0.47s with 16 workers.
9 full subsolvers: [default_lp, no_lp, max_lp, reduced_costs, pseudo_costs, quick_restart, quick_restart_no_lp, lb_tree_search, probing]
Interleaved subsolvers: [feasibility_pump, rnd_var_lns_default, rnd_cst_lns_default, graph_var_lns_default, graph_cst_lns_default, rins_lns_default, rens_lns_default]
#1 0.71s best:17 next:[1,16] quick_restart_no_lp fixed_bools:0/11849
#2 0.72s best:16 next:[1,15] quick_restart_no_lp fixed_bools:289/11849
#3 0.74s best:15 next:[1,14] no_lp fixed_bools:867/11849
#Bound 1.30s best:15 next:[8,14] max_lp initial_propagation
#Done 3.40s max_lp
#Done 3.40s probing
Sub-solver search statistics:
'max_lp':
LP statistics:
final dimension: 2498 rows, 5781 columns, 106908 entries with magnitude in [6.155988e-02, 1.000000e+00]
total number of simplex iterations: 3401
num solves:
- #OPTIMAL: 6
- #DUAL_UNBOUNDED: 1
- #DUAL_FEASIBLE: 1
managed constraints: 5882
merged constraints: 3510
coefficient strenghtenings: 19
num simplifications: 1
total cuts added: 3534 (out of 4444 calls)
- 'CG': 1134
- 'IB': 150
- 'MIR_1': 558
- 'MIR_2': 647
- 'MIR_3': 490
- 'MIR_4': 37
- 'MIR_5': 60
- 'MIR_6': 20
- 'ZERO_HALF': 438
'reduced_costs':
LP statistics:
final dimension: 979 rows, 5781 columns, 6456 entries with magnitude in [3.333333e-01, 1.000000e+00]
total number of simplex iterations: 1369
num solves:
- #OPTIMAL: 15
- #DUAL_FEASIBLE: 51
managed constraints: 2962
merged constraints: 2819
shortened constraints: 1693
coefficient strenghtenings: 675
num simplifications: 1698
total cuts added: 614 (out of 833 calls)
- 'CG': 7
- 'IB': 439
- 'LinMax': 1
- 'MIR_1': 87
- 'MIR_2': 80
'pseudo_costs':
LP statistics:
final dimension: 929 rows, 5781 columns, 6580 entries with magnitude in [3.333333e-01, 1.000000e+00]
total number of simplex iterations: 1174
num solves:
- #OPTIMAL: 14
- #DUAL_FEASIBLE: 33
managed constraints: 2923
merged constraints: 2810
shortened constraints: 1695
coefficient strenghtenings: 675
num simplifications: 1698
total cuts added: 575 (out of 785 calls)
- 'CG': 5
- 'IB': 400
- 'LinMax': 1
- 'MIR_1': 87
- 'MIR_2': 82
'lb_tree_search':
LP statistics:
final dimension: 929 rows, 5781 columns, 6650 entries with magnitude in [3.333333e-01, 1.000000e+00]
total number of simplex iterations: 1249
num solves:
- #OPTIMAL: 16
- #DUAL_FEASIBLE: 14
managed constraints: 2924
merged constraints: 2809
shortened constraints: 1692
coefficient strenghtenings: 675
num simplifications: 1698
total cuts added: 576 (out of 785 calls)
- 'CG': 8
- 'IB': 400
- 'LinMax': 2
- 'MIR_1': 87
- 'MIR_2': 79
Solutions found per subsolver:
'no_lp': 1
'quick_restart_no_lp': 2
Objective bounds found per subsolver:
'initial_domain': 1
'max_lp': 1
Improving variable bounds shared per subsolver:
'no_lp': 579
'quick_restart_no_lp': 1159
CpSolverResponse summary:
status: OPTIMAL
objective: 15
best_bound: 15
booleans: 12138
conflicts: 0
branches: 23947
propagations: 408058
integer_propagations: 317340
restarts: 23698
lp_iterations: 1174
walltime: 3.5908
usertime: 3.5908
deterministic_time: 6.71917
gap_integral: 11.2892
The log is actually very interesting to understand CP-SAT, but also to learn about the optimization problem at hand. It gives you a lot of details on, e.g., how many variables could be directly removed or which techniques contributed to lower and upper bounds the most.
As the log can be quite overwhelming, I developed a small tool to visualize and comment the log. You can just copy and paste your log into it, and it will automatically show you the most important details. Also be sure to check out the examples in it.
 |
|---|
| A plot of the search progress over time as visualized by the log analyzer by utilizing the information from the log (a different log than displayed above). Such a plot helps you understand what part of your problem is more challenging: Finding a good solution or proving its quality. Based on that you can implement respective countermeasures. |
You can also find an older explanation of the log here.
In the end of this section, a more advanced parameter that looks interesting for advanced users as it gives some insights into the search algorithm, but is probably better left alone.
We can tell CP-SAT, how to branch (or make a decision) whenever it can no longer deduce anything via propagation. For this, we need to provide a list of the variables (order may be important for some strategies), define which variable should be selected next (fixed variables are automatically skipped), and define which value should be probed.
We have the following options for variable selection:
CHOOSE_FIRST: the first not-fixed variable in the list.CHOOSE_LOWEST_MIN: the variable that could (potentially) take the lowest value.CHOOSE_HIGHEST_MAX: the variable that could (potentially) take the highest value.CHOOSE_MIN_DOMAIN_SIZE: the variable that has the fewest feasible assignments.CHOOSE_MAX_DOMAIN_SIZE: the variable the has the most feasible assignments.
For the value/domain strategy, we have the options:
SELECT_MIN_VALUE: try to assign the smallest value.SELECT_MAX_VALUE: try to assign the largest value.SELECT_LOWER_HALF: branch to the lower half.SELECT_UPPER_HALF: branch to the upper half.SELECT_MEDIAN_VALUE: try to assign the median value.
CAVEAT: In the documentation there is a warning about the completeness of the domain strategy. I am not sure, if this is just for custom strategies or you have to be careful in general. So be warned.
model.AddDecisionStrategy([x], cp_model.CHOOSE_FIRST, cp_model.SELECT_MIN_VALUE)
# your can force CP-SAT to follow this strategy exactly
solver.parameters.search_branching = cp_model.FIXED_SEARCHFor example for coloring (with
integer representation of the color), we could order the variables by decreasing
neighborhood size (CHOOSE_FIRST) and then always try to assign the lowest
color (SELECT_MIN_VALUE). This strategy should perform an implicit
kernelization, because if we need at least CHOOSE_LOWEST_MIN to always select the vertex that has the
lowest color available. Whether this will actually help, has to be evaluated:
CP-SAT will probably notice by itself which vertices are the critical ones after
some conflicts.
⚠️ I played around a little with selecting a manual search strategy. But even for the coloring, where this may even seem smart, it only gave an advantage for a bad model and after improving the model by symmetry breaking, it performed worse. Further, I assume that CP-SAT can learn the best strategy (Gurobi does such a thing, too) much better dynamically on its own.
![]()
In this section, we will explore various coding patterns that are essential for structuring implementations for optimization problems using CP-SAT. While we will not delve into the modeling of specific problems, our focus will be on demonstrating how to organize your code to enhance its readability and maintainability. These practices are crucial for developing robust and scalable optimization solutions that can be easily understood, modified, and extended by other developers. We will concentrate on basic patterns, as more complex patterns are better understood within the context of larger problems and are beyond the scope of this primer.
Warning
The naming conventions for patterns in optimization problems are not standardized. There is no comprehensive guide on coding patterns for optimization issues, and my insights are primarily based on personal experience. Most online examples tend to focus solely on the model, often presented as Jupyter notebooks or sequential scripts. The gurobi-optimods provide the closest examples to production-ready code that I am aware of, yet they offer limited guidance on code structuring. I aim to address this gap, which many find challenging, though it is important to note that my approach is highly opinionated.
For straightforward optimization problems, encapsulating the model creation and solving within a single function is a practical approach. This method is best suited for simpler cases due to its straightforward nature but lacks flexibility for more complex scenarios. Parameters such as the time limit and optimality tolerance can be customized via keyword arguments with default values.
The following Python function demonstrates solving a simple knapsack problem using CP-SAT. To recap, in the knapsack problem, we select items - each with a specific weight and value - to maximize total value without exceeding a predefined weight limit. Given its simplicity, involving only one constraint, the knapsack problem serves as an ideal model for introductory examples.
from ortools.sat.python import cp_model
from typing import List
def solve_knapsack(
weights: List[int],
values: List[int],
capacity: int,
*,
time_limit: int = 900,
opt_tol: float = 0.01,
) -> List[int]:
# initialize the model
model = cp_model.CpModel()
n = len(weights) # Number of items
# Decision variables for items
x = [model.NewBoolVar(f"x_{i}") for i in range(n)]
# Capacity constraint
model.Add(sum(weights[i] * x[i] for i in range(n)) <= capacity)
# Objective function to maximize value
model.Maximize(sum(values[i] * x[i] for i in range(n)))
# Solve the model
solver = cp_model.CpSolver()
solver.parameters.max_time_in_seconds = time_limit # Solver time limit
solver.parameters.relative_gap_limit = opt_tol # Solver optimality tolerance
status = solver.Solve(model)
# Extract solution
return (
# Return indices of selected items
[i for i in range(n) if solver.Value(x[i])]
if status in [cp_model.OPTIMAL, cp_model.FEASIBLE]
else []
)When working with more complex optimization problems, logging the model-building process can be essential to find and fix issues. Often, the problem lies not within the solver but in the model itself.
In the following example, we add some basic logging to the solver function to give us some insights into the model-building process. This logging can be easily activated or deactivated by the logging framework, allowing us to use it not only during development but also in production.
If you do not know about the logging framework of Python, this is an excellent moment to learn about it. I consider it an essential skill for production code and this and similar frameworks are used for most production code in any language. The official Python documentation contains a good tutorial.
import logging
from ortools.sat.python import cp_model
from typing import List
_logger = logging.getLogger(__name__) # get a logger for the current module
def solve_knapsack(
weights: List[int],
values: List[int],
capacity: int,
*,
time_limit: int = 900,
opt_tol: float = 0.01,
) -> List[int]:
_logger.debug("Building the knapsack model")
# initialize the model
model = cp_model.CpModel()
n = len(weights) # Number of items
_logger.debug("Number of items: %d", n)
if n > 0:
_logger.debug(
"Min/Mean/Max weight: %d/%.2f/%d",
min(weights),
sum(weights) / n,
max(weights),
)
_logger.debug(
"Min/Mean/Max value: %d/%.2f/%d", min(values), sum(values) / n, max(values)
)
# Decision variables for items
x = [model.NewBoolVar(f"x_{i}") for i in range(n)]
# Capacity constraint
model.Add(sum(weights[i] * x[i] for i in range(n)) <= capacity)
# Objective function to maximize value
model.Maximize(sum(values[i] * x[i] for i in range(n)))
# Log the model
_logger.debug("Model created with %d items", n)
# Solve the model
solver = cp_model.CpSolver()
solver.parameters.max_time_in_seconds = time_limit # Solver time limit
solver.parameters.relative_gap_limit = opt_tol # Solver optimality tolerance
_logger.debug(
"Starting the solution process with time limit %d seconds", time_limit
)
status = solver.Solve(model)
# Extract solution
selected_items = (
[i for i in range(n) if solver.Value(x[i])]
if status in [cp_model.OPTIMAL, cp_model.FEASIBLE]
else []
)
_logger.debug("Selected items: %s", selected_items)
return selected_itemsWe will not use logging in the following examples to save space, but you should consider adding it to your code.
Tip
A great hack you can do with the logging framework is that you can easily hook
into your code and do analysis beyond the simple logging. You can simply write
a handler that, e.g., waits for the tag "Selected items: %s" and then can
directly access the selected items, as the actual object is passed to the
handler (and not just the string). This can be very useful to gather
statistics or to visualize the search process.
Incorporating serializable data classes to manage instances, configurations, and solutions significantly enhances the readability and maintainability of your code. These classes also facilitate the documentation process, testing, and ensure data consistency across larger projects where data exchange among different components is necessary.
Implemented Changes: We introduce data classes using Pydantic, a popular Python library that supports data validation and settings management through Python type annotations. The changes include:
- Instance Class: Defines the knapsack problem with attributes for weights, values, and capacity. It includes a validation method to ensure that the number of weights matches the number of values, thereby enhancing data integrity.
- Configuration Class: Manages solver settings such as time limits and optimality tolerance, allowing for easy adjustments and fine-tuning of the solver’s performance. Default values ensure backward compatibility, facilitating the seamless integration of older configurations with new parameters.
- Solution Class: Captures the outcome of the optimization process, including which items were selected, the objective value, and the upper bound of the solution. This class allows us to add additional information, instead of just returning the pure solution. It also allows us to later extend the attached information without breaking the API, by just making the new entries optional or providing a default value. For example, you may be interested in the solution time that was required to find the solution.
from ortools.sat.python import cp_model
from pydantic import BaseModel, PositiveInt, List, NonNegativeFloat
class KnapsackInstance(BaseModel):
weights: List[PositiveInt] # the weight of each item
values: List[PositiveInt] # the value of each item
capacity: PositiveInt # the capacity of the knapsack
@model_validator(mode="after")
def check_lengths(cls, v):
if len(v.weights) != len(v.values):
raise ValueError("Mismatch in number of weights and values.")
return v
class KnapsackSolverConfig(BaseModel):
time_limit: PositiveInt = 900 # Solver time limit in seconds
opt_tol: NonNegativeFloat = 0.01 # Optimality tolerance (1% gap allowed)
class KnapsackSolution(BaseModel):
selected_items: List[int] # Indices of the selected items
objective: int # Objective value of the solution
upper_bound: float # Upper bound of the solution
def solve_knapsack(
instance: KnapsackInstance, config: KnapsackSolverConfig
) -> KnapsackSolution:
model = cp_model.CpModel()
n = len(instance.weights)
x = [model.NewBoolVar(f"x_{i}") for i in range(n)]
model.Add(sum(instance.weights[i] * x[i] for i in range(n)) <= instance.capacity)
model.Maximize(sum(instance.values[i] * x[i] for i in range(n)))
solver = cp_model.CpSolver()
solver.parameters.max_time_in_seconds = config.time_limit
solver.parameters.relative_gap_limit = config.opt_tol
status = solver.Solve(model)
if status in [cp_model.OPTIMAL, cp_model.FEASIBLE]:
return KnapsackSolution(
selected_items=[i for i in range(n) if solver.Value(x[i])],
objective=solver.ObjectiveValue(),
upper_bound=solver.BestObjectiveBound(),
)
return KnapsackSolution(selected_items=[], objective=0, upper_bound=0)Key Benefits:
- Structured Data Handling: Defining explicit structures for each aspect of the problem ensures robust data handling and minimizes errors, facilitating easier integration and API exposition.
- Easy Serialization: Pydantic models support straightforward conversion to and from JSON, simplifying the storage and transmission of configurations and results.
- Enhanced Testing and Documentation: Clear data definitions make it easier to generate documentation and conduct tests that confirm the model and solver's behavior.
- Backward Compatibility: Default values in data classes enable seamless integration of older configurations with new software versions, accommodating new parameters without disrupting existing setups.
One challenge I often face is designing data classes to be as generic as possible so that they can be used with multiple solvers and remain compatible throughout various stages of the optimization process. For instance, a graph might be represented as an edge list, an adjacency matrix, or an adjacency list, each with its own pros and cons, complicating the decision of which format is optimal for all stages. However, converting between different data class formats is typically straightforward, often requiring only a few lines of code and having a negligible impact compared to the optimization process itself. Therefore, I recommend focusing on functionality with your current solver without overcomplicating this aspect. There is little harm in having to call a few convert functions because you created separate specialized data classes.
In many real-world optimization scenarios, problems may require iterative refinement of the model and solution. For instance, new constraints might only become apparent after presenting an initial solution to a user or another algorithm. In such cases, flexibility is crucial, making it beneficial to encapsulate both the model and the solver within a single class. This setup facilitates the dynamic addition of constraints and subsequent re-solving without needing to rebuild the entire model.
Implemented Changes: We introduce the KnapsackSolver class, which
encapsulates the entire setup and solving process of the knapsack problem:
class KnapsackSolver:
def __init__(self, instance: KnapsackInstance, config: KnapsackSolverConfig):
self.instance = instance
self.config = config
self.model = cp_model.CpModel()
self.n = len(instance.weights)
self.x = [self.model.NewBoolVar(f"x_{i}") for i in range(self.n)]
self._build_model()
self.solver = cp_model.CpSolver()
def _add_constraints(self):
used_weight = sum(
weight * x_i for weight, x_i in zip(self.instance.weights, self.x)
)
self.model.Add(used_weight <= self.instance.capacity)
def _add_objective(self):
self.model.Maximize(
sum(value * x_i for value, x_i in zip(self.instance.values, self.x))
)
def _build_model(self):
self._add_constraints()
self._add_objective()
def solve(self) -> KnapsackSolution:
self.solver.parameters.max_time_in_seconds = self.config.time_limit
self.solver.parameters.relative_gap_limit = self.config.opt_tol
self.solver.parameters.log_search_progress = self.config.log_search_progress
status = self.solver.Solve(self.model)
if status in [cp_model.OPTIMAL, cp_model.FEASIBLE]:
return KnapsackSolution(
selected_items=[
i for i in range(self.n) if self.solver.Value(self.x[i])
],
objective=self.solver.ObjectiveValue(),
upper_bound=self.solver.BestObjectiveBound(),
)
return KnapsackSolution(
selected_items=[], objective=0, upper_bound=float("inf")
)
def prohibit_combination(self, item_a: int, item_b: int):
self.model.Add(self.x[item_a] + self.x[item_b] <= 1)
if __name__ == "__main__":
instance = KnapsackInstance(weights=[1, 2, 3], values=[4, 5, 6], capacity=3)
config = KnapsackSolverConfig(time_limit=10, opt_tol=0.01, log_search_progress=True)
solver = KnapsackSolver(instance, config)
solution = solver.solve()
print(solution)
solver.prohibit_combination(0, 1)
solution = solver.solve()
print(solution)Key Benefits:
- Incremental Model Building and Re-solving: The class structure not only
facilitates incremental additions of constraints for iterative model
modifications without starting from scratch but also supports multiple
invocations of the
solvemethod. This allows for iterative refinement of the solution by adjusting constraints or solver parameters such as time limits and optimality tolerance. - Direct Model and Solver Access: Provides direct access to the model and solver, enhancing flexibility for advanced operations and debugging, a capability not exposed in the function-based approach.
Modularization is crucial in software engineering for maintaining and scaling complex codebases. In the context of optimization models, modularizing by separating variables from the core model logic is a strategic approach. This separation facilitates easier management of variables and provides methods for more structured interactions with them.
Implemented Changes: We introduce the _ItemVariables class, which acts as
a container for the decision variables associated with the knapsack items. This
class not only creates these variables but also offers several utility methods
to interact with them, improving the clarity and maintainability of the code.
from typing import Generator, Tuple
class _ItemVariables:
def __init__(self, instance: KnapsackInstance, model: cp_model.CpModel):
self.instance = instance
self.x = [model.NewBoolVar(f"x_{i}") for i in range(len(instance.weights))]
def __getitem__(self, i):
return self.x[i]
def extract_packed_items(self, solver: cp_model.CpSolver) -> List[int]:
return [i for i, x_i in enumerate(self.x) if solver.Value(x_i)]
def used_weight(self) -> cp_model.LinearExpr:
return sum(weight * x_i for weight, x_i in zip(self.instance.weights, self.x))
def packed_value(self) -> cp_model.LinearExpr:
return sum(value * x_i for value, x_i in zip(self.instance.values, self.x))
def iter_items(
self,
weight_lb: float = 0.0,
weight_ub: float = float("inf"),
value_lb: float = 0.0,
value_ub: float = float("inf"),
) -> Generator[Tuple[int, cp_model.BoolVar], None, None]:
for i, (weight, x_i) in enumerate(zip(self.instance.weights, self.x)):
if (
weight_lb <= weight <= weight_ub
and value_lb <= self.instance.values[i] <= value_ub
):
yield i, x_i
class KnapsackSolver:
def __init__(self, instance: KnapsackInstance, config: KnapsackSolverConfig):
self.instance = instance
self.config = config
self.model = cp_model.CpModel()
self._item_vars = _ItemVariables(instance, self.model)
self._build_model()
self.solver = cp_model.CpSolver()
def _add_constraints(self):
self.model.Add(self._item_vars.used_weight() <= self.instance.capacity)
def _add_objective(self):
self.model.Maximize(self._item_vars.packed_value())
def _build_model(self):
self._add_constraints()
self._add_objective()
def solve(self) -> KnapsackSolution:
self.solver.parameters.max_time_in_seconds = self.config.time_limit
self.solver.parameters.relative_gap_limit = self.config.opt_tol
self.solver.parameters.log_search_progress = self.config.log_search_progress
status = self.solver.Solve(self.model)
if status in [cp_model.OPTIMAL, cp_model.FEASIBLE]:
return KnapsackSolution(
selected_items=self._item_vars.extract_packed_items(self.solver),
objective=self.solver.ObjectiveValue(),
upper_bound=self.solver.BestObjectiveBound(),
)
return KnapsackSolution(
selected_items=[], objective=0, upper_bound=float("inf")
)
def prohibit_combination(self, item_a: int, item_b: int):
self.model.Add(self._item_vars[item_a] + self._item_vars[item_b] <= 1)Key Benefits:
- Enhanced Readability: By encapsulating the item variables and their interactions within a dedicated class, the main solver class becomes more focused and easier to understand.
- Improved Modularity: The
_ItemVariables-class allows to easily hand over the variables to a function that may create complex constraints, without creating a cyclic dependency. The model can now be split over multiple files without any issues.
As optimization models increase in complexity, it may be beneficial to divide the overall model into smaller, more manageable submodels. These submodels can encapsulate specific parts of the problem, communicating with the main model via shared variables but hiding internal details like auxiliary variables.
For instance, piecewise linear functions can be modeled as submodels, as done
for PiecewiseLinearConstraint in
./utils/piecewise_functions/piecewise_linear_function.py.
Each submodel handles a piecewise linear function independently, interfacing
with the main model through shared x and y variables. By encapsulating the
logic for each piecewise function in a dedicated class, we standardize and reuse
the logic across multiple instances, enhancing modularity and maintainability.
requirements_1 = (3, 5, 2)
requirements_2 = (2, 1, 3)
from ortools.sat.python import cp_model
model = cp_model.CpModel()
buy_1 = model.NewIntVar(0, 1_500, "buy_1")
buy_2 = model.NewIntVar(0, 1_500, "buy_2")
buy_3 = model.NewIntVar(0, 1_500, "buy_3")
produce_1 = model.NewIntVar(0, 300, "produce_1")
produce_2 = model.NewIntVar(0, 300, "produce_2")
model.Add(produce_1 * requirements_1[0] + produce_2 * requirements_2[0] <= buy_1)
model.Add(produce_1 * requirements_1[1] + produce_2 * requirements_2[1] <= buy_2)
model.Add(produce_1 * requirements_1[2] + produce_2 * requirements_2[2] <= buy_3)
# You can find this code it ./utils!
from piecewise_functions import PiecewiseLinearFunction, PiecewiseLinearConstraint
# Define the functions for the costs
costs_1 = [(0, 0), (1000, 400), (1500, 1300)]
costs_2 = [(0, 0), (300, 300), (700, 500), (1200, 600), (1500, 1100)]
costs_3 = [(0, 0), (200, 400), (500, 700), (1000, 900), (1500, 1500)]
# PiecewiseLinearFunction is a pydantic model and can be serialized easily!
f_costs_1 = PiecewiseLinearFunction(
xs=[x for x, y in costs_1], ys=[y for x, y in costs_1]
)
f_costs_2 = PiecewiseLinearFunction(
xs=[x for x, y in costs_2], ys=[y for x, y in costs_2]
)
f_costs_3 = PiecewiseLinearFunction(
xs=[x for x, y in costs_3], ys=[y for x, y in costs_3]
)
# Define the functions for the gain
gain_1 = [(0, 0), (100, 800), (200, 1600), (300, 2_000)]
gain_2 = [(0, 0), (80, 1_000), (150, 1_300), (200, 1_400), (300, 1_500)]
f_gain_1 = PiecewiseLinearFunction(xs=[x for x, y in gain_1], ys=[y for x, y in gain_1])
f_gain_2 = PiecewiseLinearFunction(xs=[x for x, y in gain_2], ys=[y for x, y in gain_2])
# Create y>=f(x) constraints for the costs
x_costs_1 = PiecewiseLinearConstraint(model, buy_1, f_costs_1, upper_bound=False)
x_costs_2 = PiecewiseLinearConstraint(model, buy_2, f_costs_2, upper_bound=False)
x_costs_3 = PiecewiseLinearConstraint(model, buy_3, f_costs_3, upper_bound=False)
# Create y<=f(x) constraints for the gain
x_gain_1 = PiecewiseLinearConstraint(model, produce_1, f_gain_1, upper_bound=True)
x_gain_2 = PiecewiseLinearConstraint(model, produce_2, f_gain_2, upper_bound=True)
# Maximize the gain minus the costs
model.Maximize(x_gain_1.y + x_gain_2.y - (x_costs_1.y + x_costs_2.y + x_costs_3.y))Key Benefits:
- Testing: Testing complex optimization models is often very difficult as
the outputs are often sensitive to small changes in the model. Even if you
have a good test case with predictable results, detected errors may be very
difficult to track down. If you extracted elements into submodels, you can
test these submodels independently, ensuring that they work correctly before
integrating them into the main model.
def test_piecewise_linear_upper_bound_constraint(): model = cp_model.CpModel() # Defining the input. Note that for some problems it may be # easier to fix variables to a specific value and then just # test feasibility. x = model.NewIntVar(0, 20, "x") f = PiecewiseLinearFunction(xs=[0, 10, 20], ys=[0, 10, 5]) # Using the submodel c = PiecewiseLinearConstraint(model, x, f, upper_bound=True) model.Maximize(c.y) # Checking its behavior solver = cp_model.CpSolver() assert solver.Solve(model) == cp_model.OPTIMAL assert solver.Value(c.y) == 10 assert solver.Value(x) == 10
- Modularity: Submodels allow for the encapsulation of complex logic into smaller, more manageable components, enhancing code organization and readability.
- Reusability: By defining submodels for common functions or constraints, you can reuse these components across multiple instances of the main model, promoting code reuse and reducing redundancy.
- Abstraction: Submodels abstract the internal details of specific functions, enabling users to interact with them at a higher level without needing to understand the underlying implementation.
In models with numerous auxiliary variables, often only a subset is actually used by the constraints. You can now try to only create the variables that may actually be needed later on, but this can require some complex code to ensure that exactly the right variables are created. If the model is extended later on, things can get even more complicated as you may not know which variables are needed upfront. This is where lazy variable construction comes into play. Here, we create variables only when they are accessed, ensuring that only necessary variables are generated, reducing memory usage and computational overhead. While this can be more expensive that just creating a vector with all variables, when in the end most variables are needed anyway, but it can save a lot of memory and computation time if only a small subset is actually used.
Implemented Changes: We introduce the new class _CombiVariables that
manages auxiliary variables indicating that a pair of items were packed,
allowing to give additional bonuses for packing certain items together.
Theoretically, there is a square number of possible combinations, but there will
probably only be a handful of them that are actually used. By creating the
variables only when they are accessed, we can reduce memory usage and
computational overhead.
class _ItemVariables:
def __init__(self, instance: KnapsackInstance, model: cp_model.CpModel):
self.instance = instance
self.x = [model.NewBoolVar(f"x_{i}") for i in range(len(instance.weights))]
def __getitem__(self, i):
return self.x[i]
def extract_packed_items(self, solver: cp_model.CpSolver) -> List[int]:
return [i for i, x_i in enumerate(self.x) if solver.Value(x_i)]
def used_weight(self) -> cp_model.LinearExpr:
return sum(weight * x_i for weight, x_i in zip(self.instance.weights, self.x))
def packed_value(self) -> cp_model.LinearExpr:
return sum(value * x_i for value, x_i in zip(self.instance.values, self.x))
def iter_items(
self,
weight_lb: float = 0.0,
weight_ub: float = float("inf"),
value_lb: float = 0.0,
value_ub: float = float("inf"),
) -> Generator[Tuple[int, cp_model.BoolVar], None, None]:
for i, (weight, x_i) in enumerate(zip(self.instance.weights, self.x)):
if (
weight_lb <= weight <= weight_ub
and value_lb <= self.instance.values[i] <= value_ub
):
yield i, x_i
class _CombiVariables:
def __init__(
self,
instance: KnapsackInstance,
model: cp_model.CpModel,
item_vars: _ItemVariables,
):
self.instance = instance
self.model = model
self.item_vars = item_vars
self.bonus = {}
def __getitem__(self, i, j):
i, j = min(i, j), max(i, j)
if (i, j) not in self.bonus:
self.bonus[(i, j)] = self.model.NewBoolVar(f"bonus_{i}_{j}")
self.model.Add(
self.item_vars[i] + self.item_vars[j] >= 2 * self.bonus[(i, j)]
)
return self.bonus[(i, j)]
class KnapsackSolver:
def __init__(self, instance: KnapsackInstance, config: KnapsackSolverConfig):
self.instance = instance
self.config = config
self.model = cp_model.CpModel()
self._item_vars = _ItemVariables(instance, self.model)
self._bonus_vars = _CombiVariables(instance, self.model, self._item_vars)
self._objective = self._item_vars.packed_value() # Initial objective setup
self.solver = cp_model.CpSolver()
def solve(self) -> KnapsackSolution:
self.model.Maximize(self._objective)
self.solver.parameters.max_time_in_seconds = self.config.time_limit
self.solver.parameters.relative_gap_limit = self.config.opt_tol
self.solver.parameters.log_search_progress = self.config.log_search_progress
status = self.solver.Solve(self.model)
if status in [cp_model.OPTIMAL, cp_model.FEASIBLE]:
return KnapsackSolution(
selected_items=self._item_vars.extract_packed_items(self.solver),
objective=self.solver.ObjectiveValue(),
upper_bound=self.solver.BestObjectiveBound(),
)
return KnapsackSolution(
selected_items=[], objective=0, upper_bound=float("inf")
)
def add_bonus(self, item_a: int, item_b: int, bonus: int):
self._objective += bonus * self._bonus_vars[item_a, item_b]Key Benefits:
- Efficiency: Lazy construction of variables ensures that only necessary variables are created, reducing memory usage and computational overhead.
- Simplicity: By just creating the variables when accessed, we do not need any logic to decide which variables are needed upfront, simplifying the model construction process.
![]()
CP-SAT is a versatile portfolio solver, centered around a Lazy Clause Generation (LCG) based Constraint Programming Solver, although it encompasses a broader spectrum of technologies.
In its role as a portfolio solver, CP-SAT concurrently executes a multitude of diverse algorithms and strategies, each possessing unique strengths and weaknesses. These elements operate largely independently but engage in information exchange, sharing progress when better solutions emerge or tighter bounds become available.
While this may initially appear as an inefficient approach due to potential redundancy, it proves highly effective in practice. The rationale behind this lies in the inherent challenge of predicting which algorithm is best suited to solve a given problem (No Free Lunch Theorem). Thus, the pragmatic strategy involves running various approaches in parallel, with the hope that one will effectively address the problem at hand. Note that you can also specify which algorithms should be used if you already know which strategies are promising or futile.
In contrast, Branch and Cut-based Mixed Integer Programming solvers like Gurobi implement a more efficient partitioning of the search space to reduce redundancy. However, they specialize in a particular strategy, which may not always be the optimal choice, although it frequently proves to be so.
CP-SAT employs Branch and Cut techniques, including linear relaxations and cutting planes, as part of its toolkit. Models that can be efficiently addressed by a Mixed Integer Programming (MIP) solver are typically a good match for CP-SAT as well. Nevertheless, CP-SAT's central focus is the implementation of Lazy Clause Generation, harnessing SAT-solvers rather than relying primarily on linear relaxations. As a result, CP-SAT may exhibit somewhat reduced performance when confronted with MIP problems compared to dedicated MIP solvers. However, it gains a distinct advantage when dealing with problems laden with intricate logical constraints.
The concept behind Lazy Clause Generation involves the (incremental) transformation of the problem into a SAT-formula, subsequently employing a SAT-solver to seek a solution (or prove bounds by infeasibility). To mitigate the impracticality of a straightforward conversion, Lazy Clause Generation leverages an abundance of lazy variables and clauses.
Notably, the Cook-Levin Theorem attests that any problem within the realm of NP can be translated into a SAT-formula. Optimization, in theory, could be achieved through a simple binary search. However, this approach, while theoretically sound, lacks efficiency. CP-SAT employs a more refined encoding scheme to tackle optimization problems more effectively.
If you want to understand the inner workings of CP-SAT, you can follow the following learning path:
- Learn how to get a feasible solution based on boolean logics with SAT-solvers: Backtracking, DPLL, CDCL, VSIDS, ...
- Learn how to get provably optimal solutions via classical Mixed Integer
Programming:
- Linear Programming: Simplex, Duality, Dual Simplex, ...
- Understanding and Using Linear Programming (book)
- Optimization in Operations Research by Ronald Rardin (very long book also containing Mixed Integer Programming, Heuristics, and advanced topics. For those who want to dive deep.)
- Video Series by Gurobi
- Mixed Integer Programming: Branch and Bound, Cutting Planes, Branch and
Cut, ...
- Discrete Optimization on Coursera with Pascal Van Hentenryck and Carleton Coffrin (video course, including also Constraint Programming and Heuristics)
- Gurobi Resources (website)
- Linear Programming: Simplex, Duality, Dual Simplex, ...
- Learn the additional concepts of LCG Constraint Programming: Propagation, Lazy Clause Generation, ...
- Learn the details of CP-SAT:
- The proto-file of the parameters (source)
- The complete source code (source)
- A recent talk by the developers of CP-SAT (video)
- Another recent talk by the developers of CP-SAT (video)
- A talk by the developers of CP-SAT (video)
If you already have a background in Mixed Integer Programming, you may directly jump into the slides of Combinatorial Optimisation and Constraint Programming. This is a full and detailed course on constraint programming, and will probably take you some time to work through. However, it gives you all the knowledge you need to understand the constraint programming part of CP-SAT.
Originally, I wrote a short introduction into each of the topics, but I decided to remove them as the material I linked to is much better than what I could have written. You can find a backup of the old version here.
What actually happens when you execute solver.Solve(model)?
- The model is read.
- The model is verified.
- Preprocessing (multiple iterations):
- Presolve (domain reduction) - Check this video for SAT preprocessing, this video for MaxSAT preprocessing, and this paper for MIP presolving.
- Expanding higher-level constraints to lower-level constraints. See also the analogous FlatZinc and Flattening.
- Detection of equivalent variables and affine relations.
- Substitute these by canonical representations
- Probe some variables to detect if they are actually fixed or detect further equivalences.
- Load the preprocessed model into the underlying solver and create the linear relaxations.
- Search for solutions and bounds with the different solvers until the lower and upper bound match or another termination criterion is reached (e.g., time limit)
- Transform solution back to original model.
This is taken from this talk and slightly extended.
As already mentioned before, CP-SAT also utilizes the (dual) simplex algorithm and linear relaxations. The linear relaxation is implemented as a propagator and potentially executed at every node in the search tree but only at lowest priority. A significant difference to the application of linear relaxations in branch and bound algorithms is that only some pivot iterations are performed (to make it faster). However, as there are likely much deeper search trees and the warm-starts are utilized, the optimal linear relaxation may still be computed, just deeper down the tree (note that for SAT-solving, the search tree is usually traversed DFS). At root level, even cutting planes such as Gomory-Cuts are applied to improve the linear relaxation.
The linear relaxation is used for detecting infeasibility (IPs can actually be more powerful than simple SAT, at least in theory), finding better bounds for the objective and variables, and also for making branching decisions (using the linear relaxation's objective and the reduced costs).
The used Relaxation Induced Neighborhood Search RINS (LNS worker), a very successful heuristic, of course also uses linear programming.
While CP-SAT is undeniably a potent solver, it does possess certain limitations when juxtaposed with alternative techniques:
- While proficient, it may not match the speed of a dedicated SAT-solver when tasked with solving SAT-formulas, although its performance remains quite commendable.
- Similarly, for classical MIP-problems, CP-SAT may not outpace dedicated MIP-solvers in terms of speed, although it still delivers respectable performance.
- Unlike MIP/LP-solvers, CP-SAT lacks support for continuous variables, and the workarounds to incorporate them may not always be highly efficient. In cases where your problem predominantly features continuous variables and linear constraints, opting for an LP-solver is likely to yield significantly improved performance.
- CP-SAT does not offer support for lazy constraints or iterative model building, a feature available in MIP/LP-solvers and select SAT-solvers. Consequently, the application of exponential-sized models, which are common and pivotal in Mixed Integer Programming, may be restricted.
- CP-SAT is limited to the Simplex algorithm and does not feature interior point methods. This limitation prevents it from employing polynomial time algorithms for certain classes of quadratic constraints, such as Second Order Cone constraints. In contrast, solvers like Gurobi utilize the Barrier algorithm to efficiently tackle these constraints in polynomial time.
CP-SAT might also exhibit inefficiency when confronted with certain constraints, such as modulo constraints. However, it's noteworthy that I am not aware of any alternative solver capable of efficiently addressing these specific constraints. At times, NP-hard problems inherently pose formidable challenges, leaving us with no alternative but to seek more manageable modeling approaches instead of looking for better solvers.
![]()
When you begin exploring optimization, you will encounter a plethora of tools, techniques, and communities. It can be overwhelming, as these groups, while sharing many similarities, also differ significantly. They might use the same terminology for different concepts or different terms for the same concepts, adding to the confusion. Not too many experts can effectively navigate these varied communities and techniques. Often, even specialists, including professors, concentrate on a singular technique or community, remaining unaware of potentially more efficient methods developed in other circles.
If you are interested in understanding the connections between different optimization concepts, consider watching the talk Logic, Optimization, and Constraint Programming: A Fruitful Collaboration by John Hooker. Please note that this is an academic presentation and assumes some familiarity with theoretical computer science.
Let us now explore the various tools and techniques available, and see how they compare to CP-SAT. Please note that this overview is high-level and not exhaustive. If you have any significant additions, feel free to open an issue, and I will consider including them.
- Mixed Integer (Linear) Programming (MIP): MIP is a highly effective method
for solving a variety of optimization problems, particularly those involving
networks like flow or tour problems. While MIP only supports linear
constraints, making it less expressive than CP-SAT, it is often the best
choice if your model is compatible with these constraints. CP-SAT incorporates
techniques from MIP, but with limitations, including the absence of continuous
variables and incremental modeling. Consequently, pure MIP-solvers, being more
specialized, tend to offer greater efficiency for certain applications.
Notable MIP-solvers include:
- Gurobi: A commercial solver known for its state-of-the-art capabilities in MIP-solving. It offers free academic licenses, exceptional performance, user-friendliness, and comprehensive support through documentation and expert-led webinars. Gurobi is particularly impressive in handling complex, large-scale problems.
- SCIP: An open-source solver that provides a Python interface. Although not as efficient or user-friendly as Gurobi, SCIP allows extensive customization and is ideal for research and development, especially for experts needing to implement advanced decomposition techniques.
- HiGHS: A newer solver licensed under MIT, presenting an interesting alternative to SCIP. It is possibly faster and features a more user-friendly interface, but is less versatile. For performance benchmarks, see here.
- Constraint Programming (CP): Constraint Programming is a more general
approach to optimization problems than MIP. As the name suggests, it focuses
on constraints and solvers usually come with a lot of advanced constraints
that can be used to describe your problem more naturally. A classical example
is the
AllDifferent-constraint, which is very hard to model in MIP, but would allow, e.g., to trivially model a Sudoku problem. Constraint Programming has been very successful for example in solving scheduling problems, where you have a lot of constraints that are hard to model with linear constraints. The internal techniques of CP-solvers are often more logic-based and less linear algebra-based than MIP-solvers. Popular CP-solvers are:- OR-Tools' CP-SAT: Discussed in this primer, CP-SAT combines various optimization techniques, including those from MIP solvers, but its primary technique is Lazy Clause Generation. This approach translates problems into (Max-)SAT formulas for resolution.
- Choco: A traditional CP solver developed in Java, licensed under the BSD 4-Clause. While it may not match CP-SAT in efficiency or modernity, Choco offers significant flexibility, including the option to integrate custom propagators.
- SAT-Solvers: If your problem is actually just to find a feasible solution
for some boolean variables, you may want to use a SAT-solver. SAT-solvers are
surprisingly efficient and can often handle problems with millions of
variables. If you are clever, you can also do some optimization problems with
SAT-solvers, as CP-SAT actually does. Most SAT-solvers support incremental
modelling, and some support cardinality constraints. However, they are pretty
low-level and CP-SAT actually can achieve similar performance for many
problems. A popular library for SAT-solvers is:
- PySAT: PySAT is a Python library under MIT license that provides a nice interface to many SAT-solvers. It is very easy to use and allows you to switch between different solvers without changing your code. It is a good choice if you want to experiment with SAT-solvers.
- There are many solvers popping up every year and many of them are open source. Check out the SAT Competition to see the current state of the art. Most of the solvers are written in C or C++ and do not provide much documentation. However, as SAT-formulas are very simple and the solvers usually do not have complex dependencies, they can still be reasonably easy to use.
- Satisfiability modulo theories (SMT): SMT-solvers represent an advanced
tier above traditional SAT-solvers. They aim to check the satisfiability of
mathematical formulas by extending propositional logic with additional
theories like linear arithmetic, bit-vectors, arrays, and quantifiers. For
instance, an SMT-solver can determine if a formula is satisfiable under
conditions where all variables are integers that meet specific linear
constraints. Similar to the Lazy Clause Generation utilized by CP-SAT,
SMT-solvers usually use a SAT-solver in the backend, extended by complex
encodings and additional propagators to handle an extensive portfolio of
expressions. These solvers are commonly used in automated theorem proving and
system verification. A popular SMT-solver is:
- Z3: Developed by Microsoft and available under the MIT license, Z3 offers a robust Python interface and comprehensive documentation, making it accessible for a variety of applications.
- Nonlinear Programming (NLP): Many MIP-solvers can actually handle some
nonlinear constraints, as people noticed that some techniques are actually
more general than just for linear constraints, e.g., interior points methods
can also solve second-order cone problems. However, you will notice serious
performance downgrades. If your constraints and objectives get too complex,
they may also no longer be a viable option. If you have smaller optimization
problems of (nearly) any kind, you may want to look into:
- SciPy: SciPy is a Python library that offers a wide range of optimization algorithms. Do not expect it to get anywhere near the performance of a specialized solver, but it gives you a bunch of different options to solve a multitude of problems.
- Modeling Languages: Modeling languages provide a high-level, user-friendly
interface for formulating optimization problems, focusing on the challenges of
developing and maintaining models that accurately reflect real-world
scenarios. These languages are solver-agnostic, allowing easy switching
between different solvers - such as from the free SCIP solver to the
commercial Gurobi - without modifying the underlying model. They also
facilitate the use of diverse techniques, like transitioning between
constraint programming and mixed integer programming. However, the trade-off
is a potential loss of control and performance for the sake of generality and
simplicity. Some of the most popular modeling languages include:
- MiniZinc: Very well-documented and free modelling language that seems to have a high reputation especially in the academic community. The amazing course on constraint programming by Pierre Flener also uses MiniZinc. It supports many backends and there are the MiniZinc Challenges, where CP-SAT won quite a lot of medals.
- AMPL: AMPL is possibly the most popular modelling language. It has free and commercial solvers. There is not only extensive documentation, but even a book on how to use it.
- GAMS: This is a commercial system which supports many solvers and also has gotten a Python-interface. I actually know the guys from GAMS as they have a location in Braunschweig. They have a lot of experience in optimization, but I have never used their software myself.
- pyomo: Pyomo is a Python library that allows you to model your optimization problem in Python and then let it solve by different solvers. It is not as high-level as AMPL or GAMS, but it is free and open source. It is also very flexible and allows you to use Python to model your problem, which is a huge advantage if you are already familiar with Python. It actually has support for CP-SAT and could be an option if you just want to have a quick solution.
- OR-Tools' MathOpt: A very new competitor and sibling of CP-SAT. It only supports a few solvers, but may be still interesting.
- Specialized Algorithms: For many optimization problems, there are
specialized algorithms that can be much more efficient than general-purpose
solvers. Examples are:
- Concorde: Concorde is a solver for the Traveling Salesman Problem that despite its age is still blazingly fast for many instances.
- OR-Tools' Routing Solver: OR-Tools also comes with a dedicated solver for routing problems.
- OR-Tools' Network Flows: OR-Tools also comes with a dedicated solver for network flow problems.
- ...
As evident, there exists a diverse array of tools and techniques for solving optimization problems. CP-SAT stands out as a versatile approach, particularly well-suited for combinatorial optimization challenges. If you frequently encounter these types of problems, becoming proficient with CP-SAT is highly recommended. Its effectiveness across a broad spectrum of scenarios - excelling in many - is remarkable for a tool that is both free and open-source.
![]()
Benchmarking is an essential step if your model is not yet meeting the performance standards of your application or if you are aiming for an academic publication. This process involves analyzing your model's performance, especially important if your model has adjustable parameters. Running your model on a set of predefined instances (a benchmark) allows you to fine-tune these parameters and compare results. Moreover, if alternative models exist, benchmarking helps you ascertain whether your model truly outperforms these competitors.
Designing an effective benchmark is a nuanced task that demands expertise. This section aims to guide you in creating a reliable benchmark suitable for publication purposes.
Given the breadth and complexity of benchmarking, our focus will be on the
basics, particularly through the lens of the Traveling Salesman Problem (TSP),
as previously discussed in the AddCircuit section. We refer to the different
model implementations as 'solvers', and we'll explore four specific types:
- A solver employing the
AddCircuitapproach. - A solver based on the Miller-Tucker-Zemlin formulation.
- A solver utilizing the Dantzig-Fulkerson-Johnson formulation with iterative addition of subtour constraints until a connected tour is achieved.
- A Gurobi-based solver applying the Dantzig-Fulkerson-Johnson formulation via Lazy Constraints, which are not supported by CP-SAT.
This example highlights common challenges in benchmarking and strategies to address them. A key obstacle in solving NP-hard problems is the variability in solver performance across different instances. For instance, a solver might easily handle a large instance but struggle with a smaller one, and vice versa. Consequently, it's crucial to ensure that your benchmark encompasses a representative variety of instances. This diversity is vital for drawing meaningful conclusions, such as the maximum size of a TSP instance that can be solved or the most effective solver to use.
For a comprehensive exploration of benchmarking, I highly recommend Catherine C. McGeoch's book, "A Guide to Experimental Algorithmics", which offers an in-depth discussion on this topic.
Before diving into comprehensive benchmarking, it’s essential to conduct preliminary investigations to assess your model’s capabilities and identify any foundational issues. This phase, known as exploratory studies, is crucial for establishing the basis for more detailed benchmarking, subsequently termed as workhorse studies. These latter studies aim to provide reliable answers to specific research questions and are often the core of academic publications. It's important to explicitly differentiate between these two study types and maintain their distinct purposes: exploratory studies for initial understanding and flexibility, and workhorse studies for rigorous, reproducible research.
Exploratory studies serve as an introduction to both your model and the problem it addresses. This phase is about gaining preliminary understanding and insights.
- Objective: The goal here is to gather early insights rather than definitive conclusions. This phase is instrumental in identifying realistic problem sizes, potential challenges, and narrowing down hyperparameter search spaces.
For instance, in the AddCircuit-section, an exploratory study helped us
determine that our focus should be on instances with 100 to 200 nodes. If you
encounter fundamental issues with your model at this stage, it’s advisable to
address these before proceeding to workhorse studies.
Occasionally, the primary performance bottleneck in your model may not be CP-SAT but rather the Python segment where the model is being generated. In these instances, identifying the most resource-intensive parts of your Python code is crucial. I have found the profiler Scalene to be well-suited to investigate and pinpoint these bottlenecks.
Workhorse studies follow the exploratory phase, characterized by more structured and meticulous approaches. This stage is vital for a comprehensive evaluation of your model and collecting substantive data for analysis.
- Objective: These studies are designed to answer specific research questions and provide meaningful insights. The approach here is more methodical, focusing on clearly defined research questions. The benchmarks designed should be well-structured and large enough to yield statistically significant results.
Remember, the aim is not to create a flawless benchmark right away but to evolve it as concrete questions emerge and as your understanding of the model and problem deepens. These studies, unlike exploratory ones, will be the focus of your scientific publications, with exploratory studies only referenced for justifying certain design decisions.
Hint: Use the SIGPLAN Empirical Evaluation Checklist if your evaluation has to satisfy academic standards.
When undertaking both exploratory and workhorse studies, the creation of a well-designed benchmark is a critical step. This benchmark is the basis upon which you'll test and evaluate your solvers. For exploratory studies, your benchmark can start simple and progressively evolve. However, when it comes to workhorse studies, the design of your benchmark demands meticulous attention to ensure comprehensiveness and reliability.
While exploratory studies also benefit from a thoughtfully designed benchmark—as it accelerates insight acquisition—the primary emphasis at this stage is to have a functioning benchmark in place. This initial benchmark acts as a springboard, providing a foundation for deeper, more detailed analysis in the subsequent workhorse studies. The key is to balance the immediacy of starting with a benchmark against the long-term goal of refining it for more rigorous evaluations.
Ideally, a robust benchmark would consist of a large set of real-world instances, closely reflecting the actual performance of your solver. Real-world instances, however, are often limited in quantity and may not provide enough data for a statistically significant benchmark. In such cases, it's advisable to explore existing benchmarks from literature, like the TSPLIB for TSP. Leveraging established benchmarks allows for comparison with prior studies, but be cautious about their quality, as not all are equally well-constructed. For example, TSPLIB's limitations in terms of instance size variation and heterogeneity can hinder result aggregation.
Therefore, creating custom instances might be necessary. When doing so, aim for enough instances per size category to establish reliable and statistically significant data points. For instance, generating 10 instances for each size category (e.g., 25, 50, 75, 100, 150, 200, 250, 300, 350, 400, 450, 500) can provide a solid basis for analysis. This approach, though modest in scale, suffices to illustrate the benchmarking process.
Exercise caution with random instance generators, as they may not accurately represent real-world scenarios. For example, randomly generated TSP instances might lack collinear points common in real-world situations, like houses aligned on straight roads, or they might not replicate real-world clustering patterns. To better mimic reality, incorporate real-world data or use diverse generation methods to ensure a broader variety of instances. For the TSP, we could for example also have sampled from the larger TSPLIB instances.
Consider conducting your evaluation using two distinct benchmarks, especially when dealing with different data types. For instance, you might have one benchmark derived from real-world data which, although highly relevant, is too limited in size to provide robust statistical insights. Simultaneously, you could use a second benchmark based on a larger set of random instances, better suited for detailed statistical analysis. This dual-benchmark approach allows you to demonstrate the consistency and reliability of your results, ensuring they are not merely artifacts of a particular dataset's characteristics. It's a strategy that adds depth to your evaluation, showcasing the robustness of your findings across varied data sources. We will use this approach below, generating robust plots from random instances, but also comparing them to real-world instances. Mixing the two benchmarks would not be advisable, as the random instances would dominate the results.
Lastly, always separate the creation of your benchmark from the execution of experiments. Create and save instances in a separate process to minimize errors. The goal is to make your evaluation as error-proof as possible, avoiding the frustration and wasted effort of basing decisions on flawed data. Be particularly cautious with pseudo-random number generators; while theoretically deterministic, their use can inadvertently lead to irreproducible results. Sharing benchmarks is also more straightforward when you can distribute the instances themselves, rather than the code used to generate them.
Managing benchmark data can become complex, especially with multiple experiments and research questions. Here are some strategies to keep things organized:
- Folder Structure: Maintain a clear folder structure for your experiments,
with a top-level
evaluationsfolder and descriptive subfolders for each experiment. For our experiment we have the following structure:evaluations ├── tsp │ ├── 2023-11-18_random_euclidean │ │ ├── PRIVATE_DATA │ │ │ ├── ... all data for debugging │ │ ├── PUBLIC_DATA │ │ │ ├── ... selected data to share │ │ ├── README.md: Provide a short description of the experiment │ │ ├── 00_generate_instances.py │ │ ├── 01_run_experiments.py │ │ ├── .... │ ├── 2023-11-18_tsplib │ │ ├── PRIVATE_DATA │ │ │ ├── ... all data for debugging │ │ ├── PUBLIC_DATA │ │ │ ├── ... selected data to share │ │ ├── README.md: Provide a short description of the experiment │ │ ├── 01_run_experiments.py │ │ ├── .... - Redundancy and Documentation: While some redundancy is acceptable, comprehensive documentation of each experiment is crucial for future reference.
- Simplified Results: Keep a streamlined version of your results for easy access, especially for plotting and sharing.
- Data Storage: Save all your data, even if it seems insignificant at the time. This ensures you have a comprehensive dataset for later analysis or unexpected inquiries. Because this can become a lot of data, it's advisable to have two folders: One with all data and one with a selection of data that you want to share.
- Experiment Flexibility: Design experiments to be interruptible and extendable, allowing for easy resumption or modification. This is especially important for exploratory studies, where you may need to make frequent adjustments. However, if your workhorse study takes a long time to run, you do not want to repeat it from scratch if you want to add a further solver.
- Utilizing Technology: Employ tools like slurm for efficient distribution of experiments across computing clusters, saving time and resources. The faster you have your results, the faster you can act on them.
Due to a lack of tools that exactly fitted my needs I developed AlgBench to manage the results, and Slurminade to easily distribute the experiments on a cluster via a simple decorator. However, there may be better tools out there, now, especially from the Machine Learning community. Drop me a quick mail if you have found some tools you are happy with, and I will take a look myself.
Let us now come to the actual analysis of the results. We will focus on the following questions:
- Up to which size can we solve TSP instances with the different solvers?
- Which solver is the fastest?
- How does the performance change if we increase the optimality tolerance?
Our Benchmarks: We executed the four solvers with a time limit of 90s and the optimality tolerances [0.1%, 1%, 5%, 10%, 25%] on a random benchmark set and a TSPLIB benchmark set. The random benchmark set consists of 10 instances for each number of nodes [25, 50, 75, 100, 150, 200, > 250, 300, 350, 400, > >
450, 500]. The weights were chosen based on randomly embedding the nodes into a 2D plane and using the Euclidean distances. The TSPLIB benchmark consists of all euclidean instances with less than 500 nodes. It is critical to have a time limit, as otherwise, the benchmarks would take forever. You can find all find the whole experiment here.
Let us first look at the results of the random benchmark, as they are easier to interpret. We will then compare them to the TSPLIB benchmark.
A common, yet simplistic method to assess a model's performance involves plotting its runtime against the size of the instances it processes. However, this approach can often lead to inaccurate interpretations, particularly because time-limited cutoffs can disproportionately affect the results. Instead of the expected exponential curves, you will get skewed sigmoidal curves. Consequently, such plots might not provide a clear understanding of the instance sizes your model is capable of handling efficiently.
 |
|---|
| The runtimes are sigmoidal instead of exponential because the time limit skews the results. The runtime can frequently exceed the time limit, because of expensive model building, etc. Thus, a pure runtime plot says surprisingly little (or is misleading) and can usually be discarded. |
To gain a more accurate insight into the capacities of your model, consider plotting the proportion of instances of a certain size that your model successfully solves. This method requires a well-structured benchmark to yield meaningful statistics for each data point. Without this structure, the resulting curve may appear erratic, making it challenging to draw dependable conclusions.
 |
|---|
| For each x-value: What are the chances (y-values) that a model of this size (x) can be solved? |
Furthermore, if the pursuit is not limited to optimal solutions but extends to encompass solutions of acceptable quality, the analysis can be expanded. One can plot the number of instances that the model solves within a defined optimality tolerance, as demonstrated in the subsequent figure:
 |
|---|
| For each x-value: What are the chances (y-values) that a model of this size (x) can be solved to what quality (line style)? |
For a comparative analysis across various models against an arbitrary benchmark,
cactus plots emerge as a potent tool. These plots illustrate the number of
instances solved over time, providing a clear depiction of a model's efficiency.
For example, a coordinate of
Cactus plots are notably prevalent in the evaluation of SAT-solvers, where instance size is a poor indicator of difficulty. A more detailed discussion on this subject can be found in the referenced academic paper: Benchmarking Solvers, SAT-style by Brain, Davenport, and Griggio
 |
|---|
| For each x-value: How many (y) of the benchmark instances could have been solved with this time limit (x)? |
Additionally, the analysis can be refined to account for different quality tolerances. This requires either multiple experimental runs or tracking the progression of the lower and upper bounds within the solver. In the context of CP-SAT, for instance, this tracking can be implemented via the Solution Callback, although its activation is may depend on updates to the objective rather than the bounds.
 |
|---|
| For each x-value: How many (y) of the benchmark instances could have been solved to a specific quality (line style) with this time limit (x)? |
Instead of plotting the number of solved instances, one can also plot the number of unsolved instances over time. This can be easier to read and additionally indicates the number of instances in the benchmark. However, I personally do not have a preference for one or the other, and would recommend using the one that is more intuitive to read for you.
Our second benchmark for the Traveling Salesman Problem leverages the TSPLIB, a set of instances based on real-world data. This will introduce two challenges:
- The difficulty in aggregating benchmark data due to its limited size and heterogeneous nature.
- Notable disparities in results, arising from the differing characteristics of random and real-world instances.
The irregularity in instance sizes makes traditional plotting methods, like plotting the number of solved instances over time, less effective. While data smoothing methods, such as rolling averages, are available, they too have their limitations.
 |
|---|
| Such a plot may prove inefficient when dealing with high variability, particularly when some data points are underrepresented. |
In contrast, the cactus plot still provides a clear and comprehensive
perspective of various model performances. An interesting observation we can
clearly see in it, is the diminished capability of the "Iterative Dantzig" model
in solving instances, and a closer performance alignment between the
AddCircuit and Gurobi models.
 |
|---|
| Cactus plots maintain clarity and relevance, and show a performance differences between TSPLib and random instances. |
However, since cactus plots do not offer insights into individual instances,
it's beneficial to complement them with a detailed table of results for the
specific model you are focusing on. This approach ensures a more nuanced
understanding of model performance across varied instances. The following table
provides the results for the AddCircuit-model.
| Instance | # nodes | runtime | lower bound | objective | opt. gap |
|---|---|---|---|---|---|
| att48 | 48 | 0.47 | 33522 | 33522 | 0 |
| eil51 | 51 | 0.69 | 426 | 426 | 0 |
| st70 | 70 | 0.8 | 675 | 675 | 0 |
| eil76 | 76 | 2.49 | 538 | 538 | 0 |
| pr76 | 76 | 54.36 | 108159 | 108159 | 0 |
| kroD100 | 100 | 9.72 | 21294 | 21294 | 0 |
| kroC100 | 100 | 5.57 | 20749 | 20749 | 0 |
| kroB100 | 100 | 6.2 | 22141 | 22141 | 0 |
| kroE100 | 100 | 9.06 | 22049 | 22068 | 0 |
| kroA100 | 100 | 8.41 | 21282 | 21282 | 0 |
| eil101 | 101 | 2.24 | 629 | 629 | 0 |
| lin105 | 105 | 1.37 | 14379 | 14379 | 0 |
| pr107 | 107 | 1.2 | 44303 | 44303 | 0 |
| pr124 | 124 | 33.8 | 59009 | 59030 | 0 |
| pr136 | 136 | 35.98 | 96767 | 96861 | 0 |
| pr144 | 144 | 21.27 | 58534 | 58571 | 0 |
| kroB150 | 150 | 58.44 | 26130 | 26130 | 0 |
| kroA150 | 150 | 90.94 | 26498 | 26977 | 2% |
| pr152 | 152 | 15.28 | 73682 | 73682 | 0 |
| kroA200 | 200 | 90.99 | 29209 | 29459 | 1% |
| kroB200 | 200 | 31.69 | 29437 | 29437 | 0 |
| pr226 | 226 | 74.61 | 80369 | 80369 | 0 |
| gil262 | 262 | 91.58 | 2365 | 2416 | 2% |
| pr264 | 264 | 92.03 | 49121 | 49512 | 1% |
| pr299 | 299 | 92.18 | 47709 | 49217 | 3% |
| linhp318 | 318 | 92.45 | 41915 | 52032 | 19% |
| lin318 | 318 | 92.43 | 41915 | 52025 | 19% |
| pr439 | 439 | 94.22 | 105610 | 163452 | 35% |
A last option is to split the y-axis into the part where the solving time is still within the time limit, and the part where it is not and the optimality gap becomes relevant. Such a plot has some benefits but can also be difficult to scale or aggregate.
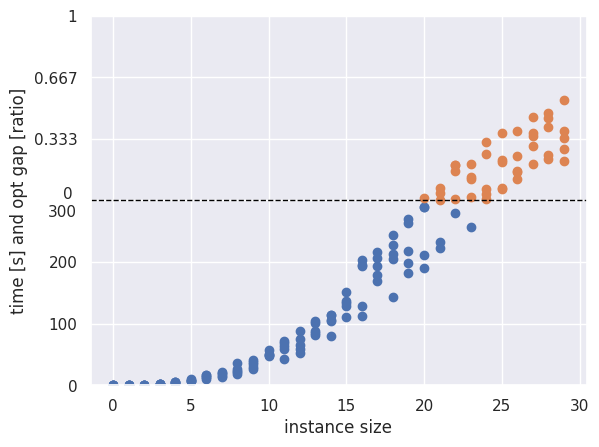 |
|---|
| This plot splits the y-axis into a part where the instances can still be solved within the time limit, such that the time can be shown, and the part where the time limit is exceeded, such that the optimality gap can be shown. This example was generated by my student assistant Rouven Kniep, and he is working on creating an easy-to-use script for such plots. |
This should highlight that often you need a combination of different benchmarks and plots to get a good understanding of the performance of your model.
Benchmarking solvers for NP-hard problems is not as straightforward as it might seem at first. There are many pitfalls and often there is no perfect solution. On the example of the TSP, we have seen how we can still get some useful results and nice plots on which we can base our decisions.
If you want to make an automated decision on what model/solver to use, things can get complicated. Often, there is none that dominates on all instances. If you want a single metric for comparing the performance, there is no perfect solution. I am actually the technical lead and co-organizer of a yearly challenge on solving hard optimization problems in computational geometry CG:SHOP, which is part of CG Week. Here, I am confronted with scoring the solutions of the participants, without having any useful bounds. It turned out that giving a score between zero and one for each instance, based on the squared difference to the best solution, works quite well. While it still has flaws, it is showed to be relatively fair and robust. The general problem of selecting the right strategy for a specific instance is called Algorithm Selection problem and can be surprisingly complex, too.
![]()
CP-SAT is great at solving small and medium-sized problems. But what if you have a really big problem on your hands? One option might be to use a special kind of algorithm known as a "meta-heuristic", like a genetic algorithm. But these can be hard to set up and might not even give you good results.
Sometimes you will see new algorithms with cool-sounding names in scientific papers. While tempting, these are often just small twists on older methods and might leave out key details that make them work. If you are interested, there's a discussion about this issue in a paper by Sörensen, called "Metaheuristics – The Metaphor Exposed".
The good news? You do not have to implement an algorithm that simulates the mating behavior of forest frogs to solve your problem. If you already know how to use CP-SAT, you can stick with it to solve big problems without adding unnecessary complications. Even better? This technique, called Large Neighborhood Search, often outperforms all other approaches.
Many traditional methods generate several "neighbor" options around an existing solution and pick the best one. However, making each neighbor solution takes time, limiting how many you can examine.
Large Neighborhood Search (LNS) offers a more efficient approach. Instead of generating neighbors one by one, LNS formulates a "mini-problem" that modifies parts of the current solution. This often involves randomly selecting some variables, resetting them, and using CP-SAT (or a similar tool) to find the optimal new values within the context of the remaining solution. This method, known as "destroy and repair," allows for a broader exploration of neighbor solutions without constructing each one individually.
Moreover, LNS can easily be mixed with other methods like genetic algorithms. If you are already using a genetic algorithm, you could supercharge it by applying CP-SAT to find the best possible crossover of two or more existing solutions. It is like genetic engineering, but without any ethical worries!
When looking into the logs of CP-SAT, you may notice that it uses LNS itself to find better solutions.
8 incomplete subsolvers: [feasibility_pump, graph_arc_lns, graph_cst_lns, graph_dec_lns, graph_var_lns, rins/rens, rnd_cst_lns, rnd_var_lns]
Why does it not suffice to just run CP-SAT if it already solves the problem with LNS? The reason is that CP-SAT has to be relatively problem-agnostic. It has no way of knowing the structure of your problem and thus cannot use this information to improve the search. You on the other hand know a lot about your problem and can use this knowledge to implement a more efficient version.
Literature:
- General Paper on LNS-variants: Pisinger and Ropke - 2010
- A generic variant (RINS), that is also used by CP-SAT: Danna et al. 2005
We will now look into some examples to see this approach in action.
You are given a knapsack that can carry a certain weight limit
This is one of the simplest NP-hard problems and can be solved with a dynamic programming approach in pseudo-polynomial time. CP-SAT is also able to solve many large instances of this problem in an instant. However, its simple structure makes it a good example to demonstrate the use of Large Neighborhood Search, even if the algorithm will not be of much use for this problem.
A simple idea for the LNS is to delete some elements from the current solution, compute the remaining capacity after deletion, select some additional items from the remaining items, and try to find the optimal solution to fill the remaining capacity with the deleted items and the newly selected items. Repeat this until you are happy with the solution quality. The number of items you delete and select can be fixed such that the problem can be easily solved by CP-SAT. You can find a full implementation under examples/lns_knapsack.ipynb.
Let us look only on an example here:
Instance:
Initial solution of value 442:
We will now repeatedly delete 5 items from the current solution and try to fill
the newly gained capacity with an optimal solution built from the deleted items
and 10 additional items. Note that this approach essentially considers
Round 1 of LNS algorithm:
- Deleting the following 5 items from the solution:
$\{I_{0}, I_{7}, I_{8}, I_{9}, I_{6}\}$ - Repairing solution by considering the following subproblem:
- Subproblem:
$C=72$ ,$I=\{I_{6},I_{9},I_{86},I_{13},I_{47},I_{73},I_{0},I_{8},I_{7},I_{38},I_{57},I_{11},I_{60},I_{14}\}$
- Subproblem:
- Computed the following solution of value 244 for the subproblem:
$\{I_{8}, I_{9}, I_{13}, I_{38}, I_{47}\}$ - Combining
$\{I_{1}, I_{2}, I_{3}, I_{4}, I_{5}\}\cup \{I_{8}, I_{9}, I_{13}, I_{38}, I_{47}\}$ - New solution of value 455:
$\{I_{1}, I_{2}, I_{3}, I_{4}, I_{5}, I_{8}, I_{9}, I_{13}, I_{38}, I_{47}\}$
Round 2 of LNS algorithm:
- Deleting the following 5 items from the solution:
$\{I_{3}, I_{13}, I_{2}, I_{9}, I_{1}\}$ - Repairing solution by considering the following subproblem:
- Subproblem:
$C=78$ ,$I=\{I_{13},I_{9},I_{84},I_{41},I_{15},I_{42},I_{74},I_{16},I_{3},I_{1},I_{2},I_{67},I_{50},I_{89},I_{43}\}$
- Subproblem:
- Computed the following solution of value 275 for the subproblem:
$\{I_{1}, I_{15}, I_{43}, I_{50}, I_{84}\}$ - Combining
$\{I_{4}, I_{5}, I_{8}, I_{38}, I_{47}\}\cup \{I_{1}, I_{15}, I_{43}, I_{50}, I_{84}\}$ - New solution of value 509:
$\{I_{1}, I_{4}, I_{5}, I_{8}, I_{15}, I_{38}, I_{43}, I_{47}, I_{50}, I_{84}\}$
Round 3 of LNS algorithm:
- Deleting the following 5 items from the solution:
$\{I_{8}, I_{43}, I_{84}, I_{1}, I_{50}\}$ - Repairing solution by considering the following subproblem:
- Subproblem:
$C=79$ ,$I=\{I_{84},I_{76},I_{34},I_{16},I_{37},I_{20},I_{8},I_{43},I_{50},I_{1},I_{12},I_{35},I_{53}\}$
- Subproblem:
- Computed the following solution of value 283 for the subproblem:
$\{I_{8}, I_{12}, I_{20}, I_{37}, I_{50}, I_{84}\}$ - Combining
$\{I_{4}, I_{5}, I_{15}, I_{38}, I_{47}\}\cup \{I_{8}, I_{12}, I_{20}, I_{37}, I_{50}, I_{84}\}$ - New solution of value 526:
$\{I_{4}, I_{5}, I_{8}, I_{12}, I_{15}, I_{20}, I_{37}, I_{38}, I_{47}, I_{50}, I_{84}\}$
Round 4 of LNS algorithm:
- Deleting the following 5 items from the solution:
$\{I_{37}, I_{4}, I_{20}, I_{5}, I_{15}\}$ - Repairing solution by considering the following subproblem:
- Subproblem:
$C=69$ ,$I=\{I_{37},I_{4},I_{20},I_{15},I_{82},I_{41},I_{56},I_{76},I_{85},I_{5},I_{32},I_{57},I_{7},I_{67}\}$
- Subproblem:
- Computed the following solution of value 260 for the subproblem:
$\{I_{5}, I_{7}, I_{15}, I_{20}, I_{37}\}$ - Combining
$\{I_{8}, I_{12}, I_{38}, I_{47}, I_{50}, I_{84}\}\cup \{I_{5}, I_{7}, I_{15}, I_{20}, I_{37}\}$ - New solution of value 540:
$\{I_{5}, I_{7}, I_{8}, I_{12}, I_{15}, I_{20}, I_{37}, I_{38}, I_{47}, I_{50}, I_{84}\}$
Round 5 of LNS algorithm:
- Deleting the following 5 items from the solution:
$\{I_{38}, I_{12}, I_{20}, I_{47}, I_{37}\}$ - Repairing solution by considering the following subproblem:
- Subproblem:
$C=66$ ,$I=\{I_{20},I_{47},I_{37},I_{86},I_{58},I_{56},I_{54},I_{38},I_{12},I_{39},I_{68},I_{75},I_{66},I_{2},I_{99}\}$
- Subproblem:
- Computed the following solution of value 254 for the subproblem:
$\{I_{12}, I_{20}, I_{37}, I_{47}, I_{75}\}$ - Combining
$\{I_{5}, I_{7}, I_{8}, I_{15}, I_{50}, I_{84}\}\cup \{I_{12}, I_{20}, I_{37}, I_{47}, I_{75}\}$ - New solution of value 560:
$\{I_{5}, I_{7}, I_{8}, I_{12}, I_{15}, I_{20}, I_{37}, I_{47}, I_{50}, I_{75}, I_{84}\}$
Simply removing a portion of the solution and then trying to fix it is not the most effective approach. In this section, we will explore various neighborhoods for the Traveling Salesman Problem (TSP). The geometry of TSP not only permits advantageous neighborhoods but also offers visually appealing representations. When you have several neighborhood strategies, they can be dynamically integrated using an Adaptive Large Neighborhood Search (ALNS).
The image illustrates an optimization process for a tour that needs to traverse the green areas, factoring in turn costs, within an embedded graph (mesh). The optimization involves choosing specific regions (highlighted in red) and calculating the optimal tour within them. As iterations progress, the initial tour generally improves, although some iterations may not yield any enhancement. Regions in red are selected due to the high cost of the tour within them. Once optimized, the center of that region is added to a tabu list, preventing it from being chosen again.
 |
|---|
| Large Neighbordhood Search for Coverage Path Planning by repeatedly selecting a geometric region (red) and optimizing the tour within it. The red parts of the tour highlight the changes in the iteration. Read from left to right, and from up to down. |
How can you determine the appropriate size of a region to select? You have two main options: conduct preliminary experiments or adjust the size adaptively during the search. Simply allocate a time limit for each iteration. If the solver does not optimize within that timeframe, decrease the region size. Conversely, if it does, increase the size. Utilizing exponential factors will help the size swiftly converge to its optimal dimension. However, it's essential to note that this method assumes subproblems are of comparable difficulty and may necessitate additional conditions.
For the Euclidean TSP, as opposed to a mesh, optimizing regions is not straightforward. Multiple effective strategies exist, such as employing a segment from the previous tour rather than a geometric region. By implementing various neighborhoods and evaluating their success rates, you can allocate a higher selection probability to the top-performing ones. This approach is demonstrated in an animation crafted by two of my students, Gabriel Gehrke and Laurenz Illner. They incorporated four distinct neighborhoods and utilized ALNS to dynamically select the most effective one.
 |
|---|
| Animation of an Adaptive Large Neighborhood Search for the classical Traveling Salesman Problem. It uses four different neighborhood strategies which are selected randomly with a probability based on their success rate in previous iterations. If you check the logs of the latest (v9.8) version of CP-SAT, it also rates the performance of its LNS-strategies and uses the best performing strategies more often (UCB1-algorithm). |
Having multiple strategies for each iteration of your LNS available is great, but how do you decide which one to use? You could just pick one randomly, but this is not very efficient as it is unlikely to select the best one. You could also use the strategy that worked best in the past, but maybe there is a better one you have not tried yet. This is the so-called exploration vs. exploitation dilemma. You want to exploit the strategies that worked well in the past, but you also want to explore new strategies to find even better ones. Luckily, this problem has been studied extensively as the Multi-Armed Bandit Problem for decades, and there are many good solutions. One of the most popular ones is the Upper Confidence Bound (UCB1) algorithm, which is also used by CP-SAT. In the following, you can see the a LNS-statistic of the CP-SATs strategies.
LNS stats Improv/Calls Closed Difficulty TimeLimit
'graph_arc_lns': 5/65 49% 0.26 0.10
'graph_cst_lns': 4/65 54% 0.47 0.10
'graph_dec_lns': 3/65 49% 0.26 0.10
'graph_var_lns': 4/66 55% 0.56 0.10
'rins/rens': 23/66 39% 0.03 0.10
'rnd_cst_lns': 12/66 50% 0.19 0.10
'rnd_var_lns': 6/66 52% 0.36 0.10
'routing_path_lns': 41/65 48% 0.10 0.10
'routing_random_lns': 24/65 52% 0.26 0.10
We will not dig into the details of the algorithm here, but if you are interested, you can find many good resources online. I just wanted to make you aware of the exploration vs. exploitation dilemma and that many smart people have already thought about it.
TODO: Continue...