- NoSQL 的概述
- Redis 的概述
- Redis 的安装和使用
- Jedis 的入门
- Redis 的数据类型
- Keys 的通用操作
- Redis 的特性
- Redis 的持久化
NoSQL:NoSQL = Not Only SQL,全新的数据库理念,泛指非关系型数据库。
- High performance - 高并发读写
- Huge Storage - 海量数据的高效率存储和访问
- High Scalability && High Availability - 高可扩展性和高可用性
- Redis
- mongoDB
- CouchDB
- Cassandra
- riak
- membase
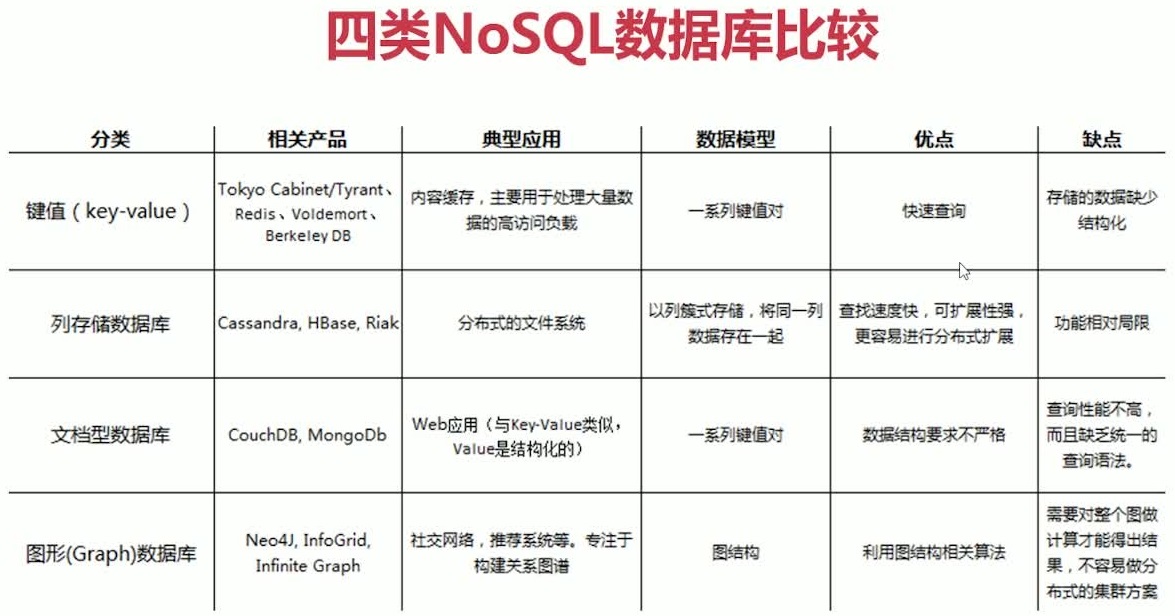
- 键值(Key-Value)存储
- Redis
- 优点:快速查询
- 缺点:存储的数据缺少结构化
- 列存储
- HBase
- 优点:查找速度快,可扩展性强,更容易进行分布式扩展
- 缺点:功能相对局限
- 文档数据库
- mongoDB
- 优点:要求数据格式不是很严格
- 缺点:查询性能不是很好,缺少统一的查询语法
- 图形数据库
- InfoGrid
- 优点:利用图结构相关算法
- 缺点:需要对整个图做计算才能得出结果,不容易做分布式的集群方案
- 易扩展(它属于非关系型的,数据之间没有关系)
- 灵活的数据类型(不需要对读写的数据建立字段)
- 大数据量,高性能(对于大数据量和高并发的读写性能支持很好)
- 高可用(在不影响系统性能情况下,可以使用框架)
Redis:C 语言开发的开源的、高性能的数据库,通过提供多种键值数据类型来适应不同情况下的场景需求。
高性能键值对数据库。
- 字符串类型
- 列表类型
- 有序集合类型
- 散列类型
- 集合类型
- 缓存
- 任务队列
- 应用排行榜
- 网站访问统计
- 数据过期处理
- 分布式集群架构中的 session 分离
4.1. 安装
tar -zxvf redis-6.2.1.tar.gz
cd redis-6.2.1
make
make PREFIX=/usr/local/redis install
cp redis.conf /usr/local/redis
cd /usr/local/redis
# PATH="/usr/local/redis:$PATH"# 前端启动
redis-server# vim redis.conf
daemonize yes# 后端启动
redis-server redis.conf# 查看进程
ps -ef | grep -i redis# 停止
redis-cli shutdown# 客户端
redis-cli4.2. Docker
docker pull redis:latestdocker run --name some-redis -d -p 63790:6379 redisdocker exec -it some-redis bashset name zhangsanget namekeys *del name<dependencies>
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.5.1</version>
</dependency>
</dependencies>// 1、设置ip和port
Jedis jedis = new Jedis("192.168.9.16", 63790);
// 2、保存数据
jedis.set("name", "mooc");
// 3、获取数据
String value = jedis.get("name");
System.out.println(value);
// 4、释放资源
jedis.close();// 1、获取连接池的配置对象
JedisPoolConfig config = new JedisPoolConfig();
// 设置对打连接数
config.setMaxTotal(30);
// 设置最大空闲连接数
config.setMinIdle(10);
// 2、获取连接池
JedisPool pool = new JedisPool(config, "192.168.9.16", 63790);
// 3、获取核心对象
Jedis jedis = null;
try {
// 通过连接池获得连接
jedis = pool.getResource();
// 设置数据
jedis.set("name", "zhangsan");
// 获取数据
System.out.println(jedis.get("name"));
} catch (Exception e) {
e.printStackTrace();
} finally {
// 释放资源
if (jedis != null) {
jedis.close();
}
if (pool != null) {
pool.close();
}
}- 字符串(String)
- 哈希(hash)
- 字符串列表(list)
- 字符串集合(set)
- 有序字符串集合(sorted-set)
Key 定义的注意点:
- 不要过长,浪费内存,降低性能
- 不要过短,可读性差
- 统一的命名规范
- 二进制是安全的,存入和获取的数据相同
- Value 最多可以容纳的数据长度是 512M
# 赋值
set name zhangsan
getset name lisi
# 取值
get name
# 删除
del name
# 数值增减
incr num
decr num
incrby num 5
decrby num 3
# 字符串追加,返回字符串的长度
append num 5- String Key 和 String Value 的 map 容器
- 每一个 Hash 可以存储 4294967295 个键值对
# 赋值
hset myhash username jack
hset myhash age 18
hmset myhash2 username rose age 21
# 取值
hget myhash username
hmget myhash username age
hgetall myhash
# 删除
hdel myhash2 username
hdel myhash2 username age
del myhash2
# 数值增减
hincrby myhash age 5
hdecrby myhash age 3
# 键存在
hexists myhash username
hexists myhash password
# 长度
hlen myhash
# 键值查看
hkeys myhash
hvals myhash- ArrayList 使用数组方式
- LinkedList 使用双向链接方式
- 双向链表中增加数据
- 双向链表中删除数据
# 两端添加
lpush mylist a b c
lpush mylist 1 2 3
rpush mylist2 a b c
rpush mylist2 1 2 3
# 查看列表
lrange mylist 0 5
lrange mylist20 -1
lrange mylist20 -2
# 两端弹出
lpop mylist
rpop mylist2
# 获取列表元素个数
llen mylist
llen mylist3
# 添加成功
lpushx mylist x
rpushx mylist2 y
# 失败
lpushx mylist3 xlpush mylist3 1 2 3
lpush mylist3 1 2 3
lpush mylist3 1 2 3
lrange mylist3 0 -1
# 删除从左边开始2个3
lrem mylist3 2 3
lrange mylist3 0 -1
# 删除从右边开始2个1
lrem mylist3 -2 1
lrange mylist3 0 -1
# 删除所有的2
lrem mylist3 0 2
lrange mylist3 0 -1# 设置下标为3(下标从0开始)的元素值为mmm
lset mylist 3 mmmlpush mylist4 a b c
lpush mylist4 a b c
lrange mylist4 0 -1
linsert mylist4 before b 11
linsert mylist4 after b 22lpush mylist5 1 2 3
lpush mylist6 a b c
lrange mylist5 0 -1
lrange mylist6 0 -1
rpoplpush mylist5 mylist6
lrange mylist5 0 -1
lrange mylist6 0 -1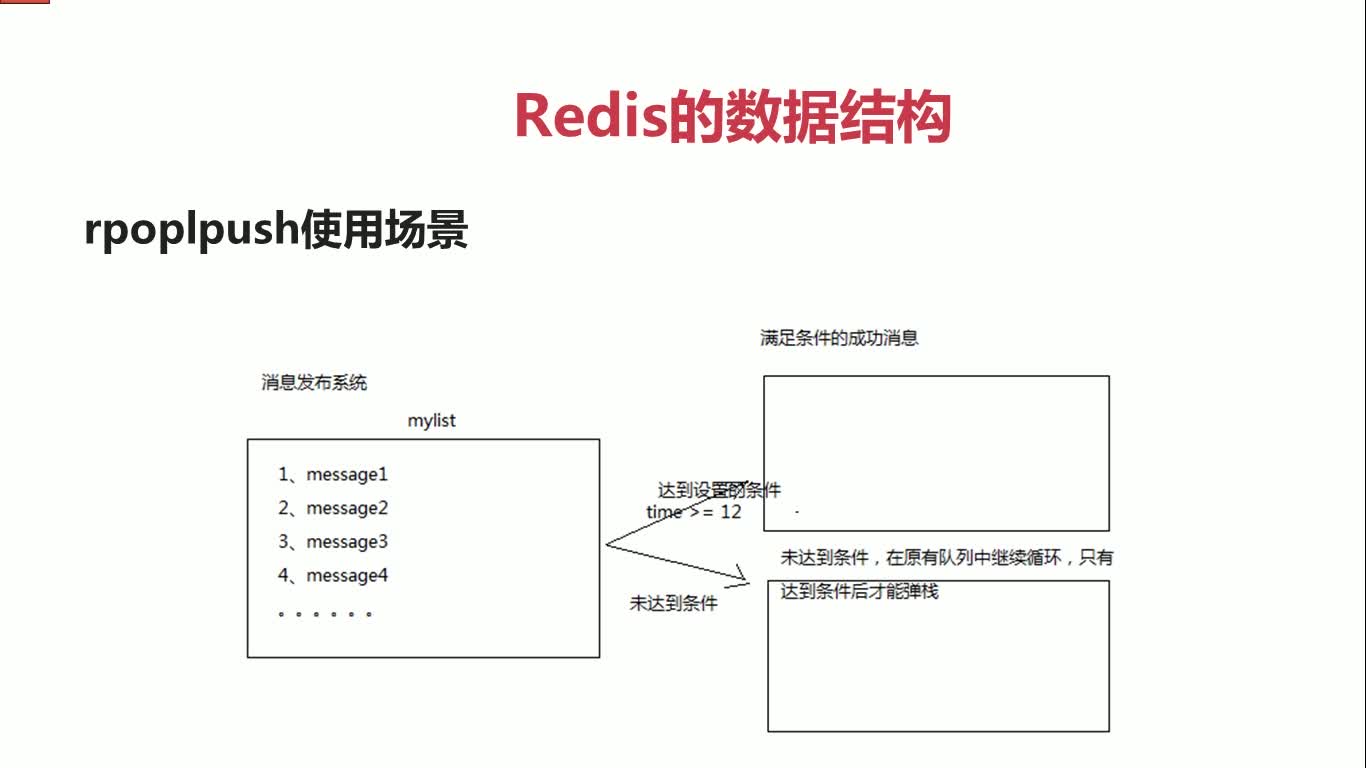
- 和 List 类型不同的是,Set 集合中不允许出现重复的元素
- Set 可包含的最大元素数量是 4294967295
# 添加、删除元素
sadd myset a b c
sadd mysey a
sadd myset 1 2 3
srem myset 1 2
# 获得集合中的元素
smembers myset
sismember myset x
# 集合的差集运算
sadd mya1 a b c
sadd myb1 a c 1 2
sdiff mya1 myb1
sdiffstore my1 mya1 myb1
# 集合的交集运算
sinter mya1 myb1
sinterstore my2 mya1 myb1
# 集合的并集运算
sunion mya1 myb1
sunionstore my3 mya1 myb1
# 数量
scard myset
# 随机
srandmember myset使用场景:
- 跟踪一些唯一性数据
- 用于维护数据对象之间的关联关系
- sorted-set 和 set 的区别
- sorted-set 中的成员在集合中的位置是有序的
# 添加元素
zadd mysort 70 zhangsan 80 lisi 90 wangwu
zadd mysort 100 zhangsan
zadd mysort 85 jack 95 rose
zadd mysort 60 tom
# 获得元素
zscore mysort zhangsan
zcard mysort
# 删除元素
zrem mysort tom wangwu
# 范围查询
zrange mysort 0 -1
zrange mysort 0 -1 withscores
zrevrange mysort 0 -1 withscores
# 按排序删除
zremrangebyrank mysort 0 4
# 按分数范围删除
zremrangebyscore mysort 80 90
# 按分数过滤
zrangebyscore mysort 80 90 withscores
zrevrangebyscore mysort 90 80 withscores
zrevrangebyscore mysort 90 80 withscores limit 0 2
# 数值增减
zincrby mysort 3 lisi
zscore mysort lisi
# 按分数计数
zcount mysort 80 90使用场景:
- 如大型在线游戏积分排行榜
- 构建索引数据
keys *
keys my?
del my1 my2 my3
exists my1
exists mya1get company
rename company new_company
get new_company# 单位:秒
expire new_company 1000
# 剩余时间
ttl new_companytype new_company
type mylist
type myset
type myhash
type mysort# 从 0 到 15
select 0# 将 set 移动到 1 号数据库
move myset 1# multi 开启事务# exec 提交事务# discard 回滚事务两种持久化的方式:
- RDB 方式
- AOF 方式
持久化使用的方式:
- RDB 持久化:默认支持,在指定的时间间隔内,将内存中的数据集快照写入到磁盘
- AOF 持久化:日志的形式记录服务器处理的每一个操作,服务器启动之初,读取文件,重新构建数据库
- 无持久化:通过配置禁用 Redis 持久化功能,Redis 缓存机制
- 同时使用 RDB 和 AOF
- 数据库只包含一个文件,通过文件备份策略,定期配置,恢复系统灾难
- 压缩文件转移到其他介质上
- 性能最大化,Redis 开始持久化时,分叉出进程,由子进程完成持久化的工作,避免服务器进程执行 I/O 操作,启动效率高
- 无法高可用:系统一定在定时持久化之前宕机,数据还没写入,数据已经丢失
- 通过 fork 分叉子进程完成工作,数据集大的时候,服务器需要停止几百毫秒甚至 1 秒
# vim redis.conf
# 每 900 秒(15min)至少有 1 个key 发生变化,那么就保存快照
save 900 1
# 每 300 秒(5min)至少有 10 个key 发生变化,那么就保存快照
save 300 10
# 每 60 秒(1min)至少有 10000 个key 发生变化,那么就保存快照
save 60 10000dbfilename dump.rdb
dir ./- 同步:
- 每秒同步:异步完成,效率高,一旦系统宕机,修改的数据丢失
- 每修改同步:同步持久化,每分钟发生的变化记录到磁盘中,效率低,安全
- 不同步
- 日志写入操作追加模式 append
- 系统宕机,不影响存在的内容
- 写入一半数据,若系统崩溃,下次启动 redis,redis-check-aof 工具解决数据一致性
- 如果日志过大,自动重写机制,修改的数据写入到到磁盘文件,创建新文件,记录产生的修改命令,重写切换时,保证数据安全
- 格式清晰的日志文件,完成数据的重建
- 对于相同数据文件,相比 RDB,AOF 文件较大
- 效率低
# vim redis.conf
appendonly noappendfsync always
# appendfsync everysec
# appendfsync no