地址:https://github.com/jarlor/hadoop_on_docker
博客:https://www.jarlor.site/2023/10/15/hadoop-on-docker/

当今时代信息资源日益丰富大量,信息资源的利用对社会的发展起着主要作用,运用信息技术协助产业设计越来越成为行业发展的重要趋势。
旅游产业是典型的体验服务产业,在任何发展阶段,信息反馈的准确性与及时性都具有非凡的意义。大数据的3V特征,海量的数据规模(Volume)、快速的数据流转和动态的数据体系(Velocity)、多样的数据类型(Variety)都能够很好地满足旅游产业对信息的各方面需求。从现阶段发展来看,旅游大数据在系统了解旅游市场构成、细分市场特征、消费者需求和竞争者状况,保证品牌市场个性化方面以及在统计分析消费者行为、兴趣偏好和产品的市场口碑,有针对性地制订旅游产品和营销计划方面;在帮助企业管理者掌握旅游行业潜在的市场需求推进旅游行业收益管理等方面得到了有效应用,大数据分析技术在定制旅游上的应用更是逐渐发展成为一种全新的旅游生产方式。本文通过分析国内旅游市场现状、大数据的应用特点以及现有定制旅游网站产品服务的模式及特征,试图通过某种方式理解旅游用户的真正需求,从而帮助实现定制旅游网站的产品及服务设计最优。
“定制旅游”是旅游市场发展的需要,同样是高度同质化的在线旅游市场发展的结果。它是以旅游者为主导进行旅游行动流程的设计,通常根据旅游者的消费能力,以满足其个性化的需求为原则,,设计出最大限度符合旅游者心理预期产品的一种旅游方式。定制旅游发展到现在不仅包括面向垂直细分人群的旅游产品设计更衍生出多种在线旅游产品平台模式。通过资料研究,现有基于大数据的定制旅游网站一般为两种模式。
其一,“反向定制”旅游网站模式。基于庞大的用户数据,进行旅游用户群行为的预测,从而根据旅游用户群体的喜好或消费倾向,制订相应主题的旅游产品。
其二,自主旅游定制模式。由旅游者提出具体求,旅游平台进行对接。“反向定制”模式创造性地结合了多样化与标准化,在满足客户个性化需求的同时,能够降低定制成本,加快定制速度。而自主旅游定制模式要求网站能够第一时间对用户需求做出反应,这里是指利用大数据和智能化技术,为用户一键生成出游路线计划。两种模式的定制旅游突破了传统旅游典型的标准化产品和服务,向人们展示了一种更便捷、更主动的旅行方式,在产品或服务的设计过程中,行程计划根据用户的需求定制,使旅行的灵活性极大增强,有效提升了旅游质量。自主定制旅游更突出科技的高效精准,大数据挖掘技术代替旅游用户本人做了行前大量的准备、调研工作,能够节省用户更多的时间成本。
然而,通过实例分析,现有定制旅游网站在概念层面以及满足用户个性化需求层面上存在不同程度的局限性。所谓“定制”是指个人属性强烈的产品,“反向定制”突出反映产品设计中人们普遍关注一个在线旅游用户群体,而较少从旅游用户个体的角度进行关联分析的现状;自主旅游模式更是从用户简单的几步倾向选择出发,进行用户求片面妄断。两种旅游定制模式严格意义上无法真正触及每个旅游个体用户的真正心理,无法实现真正的个性化定制。
本文用到的开发环境如下:
- IDEA 2018.3
- Hadoop 2.7.2
- Zookeeper 3.4.10
- Hive 1.2.1
- HBase 1.3.1
- Echarts 5.1.1
Java中支持的爬虫框架有很多,比如WebMagic、Spider、Jsoup等。我们使用Jsoup来实现一个简单的爬虫程序。
Jsoup拥有十分方便的api来处理html文档,比如参考了DOM对象的文档遍历方法,参考了CSS选择器的用法等等,因此我们可以使用Jsoup快速地掌握爬取页面数据的技巧。
通过Jsoup对网页中有用的数据进行解析,之后我们将得到想要的数据。获取城市所有信息,首先需要获取到城市名称也就是获取所有<dd></dd>标签中的所有a链接的文本。
数据清洗是指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。与问卷审核不同,录入后的数据清理一般是由计算机而不是人工完成。
使用Jsoup获取到的是整个页面的资源,其中包含html的代码,也就会包含无意义的数据,需将它进行清洗。
-
获取所有<dd></dd>标签。
Elements all_dd = pinyin_filter.getElementsByTag("dd");
-
获取<dd></dd>标签下的所有a标签。
String cityID = StringUtil.getNumbers(element.attr("href"));
-
获取所有a标签中的文本并添加到HotelCity类中,HotelCity实体类信息如表2-1所示:
表2-1 HotelCity实体类信息
| id | int |
|---|---|
| name | varchar |
| price | double |
| lat | double |
| lon | double |
| url | varchar |
| img | varchar |
| score | double |
| dpsocre | int |
| star | varchar |
| stardesc | varchar |
| shortName | varchar |
核心代码如下:
String headPinyin = dt_headPinyin.text();
hotelCity.setHeadPinyin(headPinyin);将获取到携程网的城市酒店的HTML数据(包含所有元素)进行清洗,得到我们需要的标签数据。为了更好的解析数据,我们要将一些无意义的数据进行清洗。Jsoup在这里提供了一个方便的清洗数据方法。然后就可以通过Jsoup进行数据的清洗。
通过分析酒店相关信息是ajax加载存放在json数据中,价格也在同一个json中但是放在另外的位置通过酒店id对应,并且请求方式是POST,请求的参数有很多,经检验可只传城市id获取,下面简单介绍通过网络请求将json数据拿到,最后将重要数据进行截取,返回一个清晰重要的json数据,再对json数据进行解析便可得到酒店相关信息。
HBase是一个分布式的、面向列的开源数据库,该技术来源于Fay Chang所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
HBase——Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
与FUJITSU Cliq等商用大数据产品不同,HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用Zookeeper作为对应。
下图描述Hadoop EcoSystem中的各层系统。其中,HBase位于结构化存储层,Hadoop HDFS为HBase提供了高可靠性的底层存储支持;Hadoop MapReduce为HBase提供了高性能的计算能力;Zookeeper为HBase提供了稳定服务和failover机制。
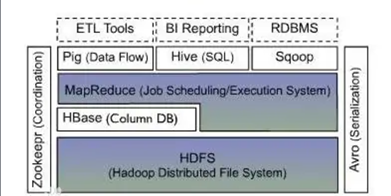
图3-1 HBase结构图
HBase中的所有数据文件都存储在Hadoop HDFS文件系统上,主要包括上述提出的两种文件类型:
-
HFile,HBase中KeyValue数据的存储格式,HFile是Hadoop的二进制格式文件,实际上StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile。
-
HLog File,HBase中WAL(Write Ahead Log)的存储格式,物理上是Hadoop的Sequence File。
- 创建Hbase表的方法
代码如下:
public static void createTable(String tableName, String... columnNames) throws IOException {
startConn();
//获取表对象操作
Admin admin = conn.getAdmin();
TableName tableNameObj = TableName.valueOf(Bytes.toBytes(tableName));
//判断表是否为空
if (tableName != null && !tableName.isEmpty()) {
if (!admin.tableExists(tableNameObj)) {
HTableDescriptor hdr = new HTableDescriptor(tableNameObj);
for (String columnName : columnNames) {
hdr.addFamily(new HColumnDescriptor(columnName));}
admin.createTable(hdr);
}
}
closeConn();
}- 向指定表插入数据的方法
代码如下:
public static long putDataByTable(String tablename, List<Put> puts) throws Exception {
startConn();
long currentTime = System.currentTimeMillis();
Table table = conn.getTable(TableName.valueOf(Bytes.toBytes(tablename)));
try {
table.put(puts);
} finally {
table.close();
closeConn();
}
return System.currentTimeMillis() - currentTime; //返回插入数据花费的时间(毫秒)}表名: t_city_hotels_info
列族:cityInfo、hotel_info
列族cityinfo下的列:cityId、cityName、pinyin、collectionTime
列族hotel_info下的列:id、name、price、lon、url、img、address、score、dpscore、dpscore、dpcount、star、stardesc、shortName、isSingleRec
从Hotel实体类中提取数据并保存到Hbase表中。
核心代码如下:
表名: t_hotel_comment
列族:hotel_info、comment_info
列族c hotel_info下的列:hotel_name、hotel_id
列族comment_info下的列:id、baseRoomId、baseRoomName、checkInDate、postDate、content、highlightPosition、hasHotelFeedback、userNickName
从HotelComment实体类中提取数据并保存到Hbase表中。
核心代码如下:
List<Hotel> parseArray = JSONObject.parseArray(readFileToString, Hotel.class);
List<Hotel> hongkongHotel = JSONObject.parseArray(hongkong, Hotel.class);
parseArray.addAll(hongkongHotel);
HBaseUtil.putDataByTable("t_city_hotels_info", puts);- Mapper阶段
输入类型:< ImmutableBytesWritable, Result>
输出类型:<ImmutableBytesWritable, DoubleWritable>
在Mapper阶段,从Hbase表t_city_hotels_info中读取数据,查询出每个RowKey的列cityInfo:cityName、列hotel_info:price对应的值。将列cityInfo:cityName对应的值设置为输出的K、列hotel_info:price对应的值设置为输出的V。
核心代码如下:
byte[] cityName = value.getValue(Bytes.toBytes("cityInfo"), Bytes.toBytes("cityName"));
k.set(cityName);
byte[] byte_price = value.getValue(Bytes.toBytes("hotel_info"), Bytes.toBytes("price"));
double doulble_price = Double.parseDouble(Bytes.toString(byte_price));
v.set(doulble_price);
context.write(k, v);-
Reducer阶段
输入类型:<ImmutableBytesWritable, DoubleWritable>
输出类型:<ImmutableBytesWritable, Put>
在Reducer阶段,从Mapper中取出数据,取出具有相同的K的V,求平均值。
将结果输出到Hbase表AveragePrice,将K设置为RowKey,平均值设置为列info: price的值。
核心代码如下:
for (DoubleWritable value : values) {
sum += value.get();
count++;}
double average = sum / count;
v.addColumn(Bytes.toBytes("info"), Bytes.toBytes("price"), Bytes.toBytes(String.valueOf(average)));
context.write(key,v);- Driver阶段
Hbase提供了TableMapReduceUtil的initTableMapperJob和initTableReducerJob两个方法来完成MapReduce的配置。需指定Mapper要读取的表以及Reducer分析数据后要导入的表。
核心代码如下:
TableMapReduceUtil.initTableMapperJob(
"t_city_hotels_info",
new Scan(),
APMapper.class,
Text.class,
IntWritable.class,
job);
//reducer
TableMapReduceUtil.initTableReducerJob(
"AveragePrice",
CWReducer.class,
job);word分词是一个Java实现的中文分词组件,提供了多种基于词典的分词算法。能准确识别英文、数字,以及日期、时间等数量词,能识别人名、地名、组织机构名等未登录词。通过HBASE的MapReduce进行数据分析,得到词频较高的数量并进行汇总。
- Mapper阶段
输入类型:< ImmutableBytesWritable, Result>
输出类型:<Text, IntWritable>
在Mapper阶段,从Hbase表t_hotel_comment中读取数据,查询出每个RowKey的列comment_info: content对应的值。将列comment_info: content对应的值设置为输出的K、该词出现次数指定为1并设置为V。
核心代码如下:
private static byte[] family = "comment_info".getBytes();
private static byte[] column = "content".getBytes();
byte[] value = result.getValue(family, column);
String word = new String(value,"utf-8");
if(!word.isEmpty()){
String filter = EmojiParser.removeAllEmojis(word);
List<Word> segs = WordSegmenter.seg(filter);
for(Word cont : segs) {
Text text = new Text(cont.getText());
IntWritable v = new IntWritable(1);
context.write(text,v);
}
}-
Reducer阶段
输入类型:<Text, IntWritable>
输出类型:<ImmutableBytesWritable, Put>
在Reducer阶段,从Mapper中取出数据,取出具有相同的K的V,求和。将结果输出到Hbase表CountWord,将K设置为RowKey,求和结果设置为列word_info: count的值。
核心代码如下:
int sum=0;
for(IntWritablevalue:values){
sum+=value.get();
}
Put put=new Put(Bytes.toBytes(key.toString()));
put.addColumn(family,column,Bytes.toBytes(sum));
context.write(null,put);- Driver阶段
需指定Mapper要读取的表以及Reducer分析数据后要导入的表。
核心代码如下:
//mapper
TableMapReduceUtil.initTableMapperJob(
"t_hotel_comment",
new Scan(),
CWMapper.class,
Text.class,
IntWritable.class,
job);
//reducer
TableMapReduceUtil.initTableReducerJob(
"CountWord",
CWReducer.class,
job);数据可视化主要是对数据分析得到的结果进行可视化,形成直观的图表展示。对于分析出来的数据,我们只有将他们进行展示才能彰显分析出来的数据的真正的价值,因此一个好的可视化框架至关重要,因此,我们将选取Echarts作为我们数据可视化的框架。
ECharts是一款基于JavaScript的数据可视化图表库,提供直观,生动,可交互,可个性化定制的数据可视化图表。
丰富的可视化类型。ECharts 提供了常规的折线图、柱状图、散点图、饼图、K线图,用于统计的核型图,用于地理数据可视化的地图、热力图、线图,用于关系数据可视化的关系图、旭日图,多维数据可视化的平行坐标,还有用于 BI 的漏斗图,仪表盘,并且支持图与图之间的混搭。
除了已经内置的包含了丰富功能的图表,ECharts 还提供自定义系列,只需要传入一个renderItem函数,就可以从数据映射到任何你想要的图形,更棒的是这些都还能和已有的交互组件结合使用而不需要操心其它事情。
你可以在下载界面下载包含所有图表的构建文件,如果只是需要其中一两个图表,又嫌包含所有图表的构建文件太大,也可以在在线构建中选择需要的图表类型后自定义构建。
多种数据格式无需转化直接使用。ECharts 内置的 dataset 属性(4.0+)支持直接传入包括二维表,key-value 等多种格式的数据源,通过简单的设置 encode 属性就可以完成从数据到图形的映射,这种方式更符合可视化的直觉,省去了大部分场景下数据转换的步骤,而且多个组件能够共享一份数据而不用克隆。为了配合大数据量的展现,ECharts 还支持输入 TypedArray 格式的数据,TypedArray 在大数据量的存储中可以占用更少的内存,对 GC 友好等特性也可以大幅度提升可视化应用的性能。
本设计采用Echarts作为可视化数据展示框架,并采用柱状图展示酒店价格分布, 最终效果如图5-1所示。
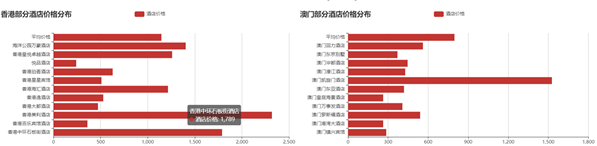
图 5-1 酒店价格分布图
酒店平均价格对比图,最终效果如图5-2所示。
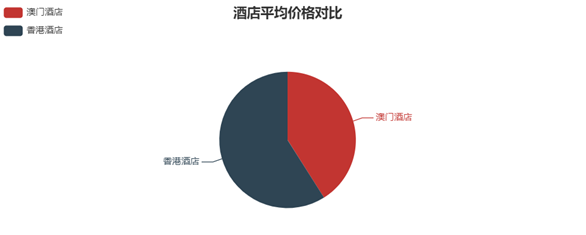
图 5-2 酒店平均价格对比图
酒店房型统计图,最终效果如图5-3所示。
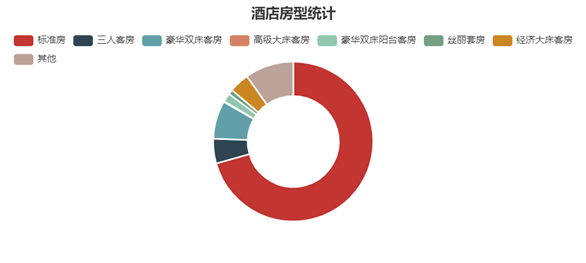
图 5-3 酒店房型统计图
通过echarts框架可以轻松实现数据的可视化展示,下图是根据echarts统计绘制的图表信息。
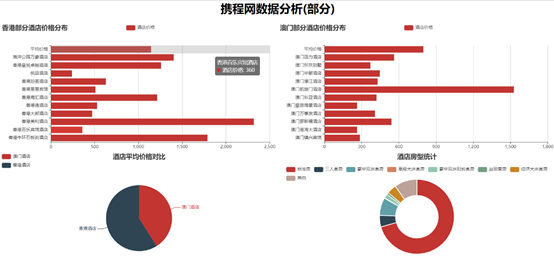
图 5‑4 携程网数据分析
由于受硬件资源的限制,本项目只分析了携程网部分酒店的信息。在统计词频这一MR程序上,由于调用了第三方Jar包,导致在服务器上运行MR程序的过程中碰到了ClassNotFoundException。经多次调试依旧无法解决问题。考虑到数据量相对较小的情况,最终通过JAVA SE程序设计分析数据并转存到HBase中。
考虑到工作量的问题,本设计最终可视化展示为静态网页。同时由于小组缺少美工,最终展示效果较为单调。
从数据抓取,数据清洗,数据分析,数据存储,数据可视化过程中,本小组通过Gitee实现开发同步。本小组通过多种形式的学习,不断地提高自己的技术水平。总的来说,本次项目开发获益良多。
随着大数据时代的到来,国内不同的旅游行业也开始重视大数据的应用,相信未来大数据将随着产业互联网深入到广大传统行业,相应的生态建设也会越来越完善。
-
王泽梁,汪丽华."互联网+旅游大数据时代旅游人才计算机能力培养[J].西昌学院学报(自然科学版),2019,33(3):109-113.
-
刘力钢,陈金大数据时代边境地区县域全域旅游目的地品牌形象提升策略[J].企业经济,2019,38(10):48-54.
-
吕雨阶.大数据背景下智慧旅游管理模式研究[J].旅游纵览(下半月),2019(18):34-35.
-
彭灵芝.大数据时代在线旅游企业发展路径研究[J].商场现代化,2019(17):138-139.
-
秦燕.大数据在旅游管理中的应肌[J]佳木斯职业学院学报,2019(9):61-62.
-
王秀玲大数据在旅游统计中的应用研究[J].产业与科技论坛,2018,17(23);:47-48.