Welcome to the research code repository for my Master's Thesis work on Deep Learning Based Recommendation Systems. This work is still in progress.
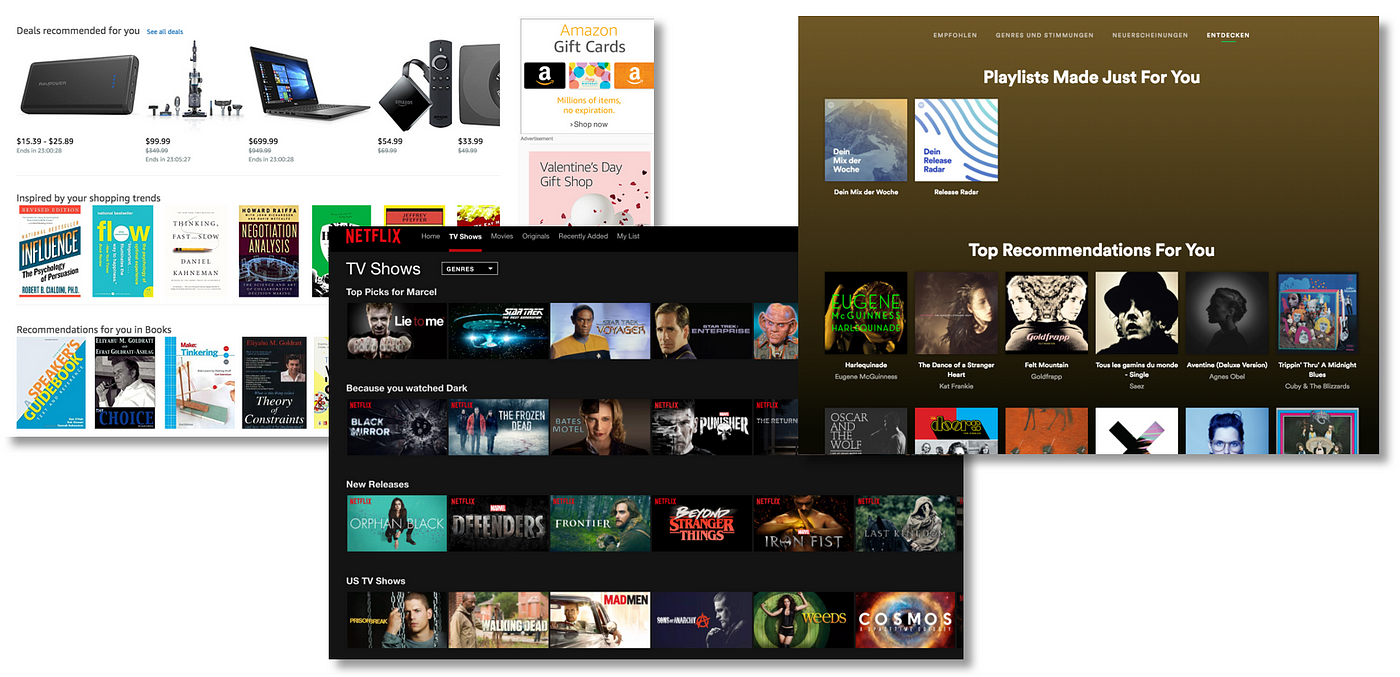
Recommendation systems are technologies and techniques that can provide recommendations for items to be of use to a user. The recommendations provided are aimed at supporting their users in various decision-making processes, such as what products to purchase, what music to listen, or what routes to take. Correspondingly, various techniques for recommendation generation have been proposed and deployed in commercial environments. The goal of this research is to impose a degree of order upon this diversity by presenting a coherent and unified repository of the most common recommendation methods to solve the collaborative filtering problem: from classic matrix factorization to cutting-edge deep neural networks.
For my experiments thus far, I worked with the MovieLens1M Dataset, a famous dataset within the recommendation systems research community. The data contains 1,000,209 anonymous ratings of approximately 3,900 movies made by 6,040 MovieLens users who joined MovieLens in 2000.
Here are the 7 different Matrix Factorization models for Collaborative Filtering:
- Vanilla Matrix Factorization
- Matrix Factorization with Biases
- Matrix Factorization with Side Features
- Matrix Factorization with Temporal Features
- Factorization Machines
- Matrix Factorization with Mixture of Tastes
- Variational Matrix Factorization
Here are the 5 different Multilayer Perceptron models for Collaborative Filtering:
- Wide and Deep Learning (paper)
- Deep Factorization Machines (paper)
- Extreme Deep Factorization Machines (paper)
- Neural Factorization Machines (paper)
- Neural Collaborative Filtering (paper)
Here are the 6 different Autoencoders models for Collaborative Filtering:
- AutoRec (paper)
- DeepRec (paper)
- Collaborative Denoising Autoencoders (paper)
- Multinomial Variational Autoencoders (paper)
- Sequential Variational Autoencoders (paper)
- Embarrassingly Shallow Autoencoders (paper)
Here are the 3 different Boltzmann Machines models for Collaborative Filtering:
- Restricted Boltzmann Machines (paper)
- Explainable Restricted Boltzmann Machines (paper)
- Neural Autoregressive Distribution Estimator (paper)
Here I built a recommendation web service with Python 3.6 and Django 2.2.4. It has these properties:
- Can handle many API endpoints,
- Each API endpoint can have several research algorithms with different versions,
- Research code and artifacts (files with model parameters) are stored in the code repository (git),
- Supports fast deployments and continuous integration (tests for both: server and research code),
- Supports monitoring and algorithm diagnostic (support A/B tests),
- Is scalable (deployed with containers),
- Has a user interface.
I have written a series of blog posts documenting my experiments on my website:
- Part 1: An Executive Guide to Building Recommendation System
- Part 2: The 10 Categories of Deep Recommendation Systems That Academic Researchers Should Pay Attention To
- Part 3: The 6 Research Directions of Deep Recommendation Systems That Will Change The Game
- Part 4: The 7 Variants of Matrix Factorization for Collaborative Filtering
- Part 5: The 5 Variants of Multi-Layer Perceptron for Collaborative Filtering
- Part 6: The 6 Variants of Autoencoders for Collaborative Filtering
- Part 7: The 3 Variants of Boltzmann Machines for Collaborative Filtering