{kind=link}
{kind=link}
This is an alternative dashboard for Corona Virus case numbers in some German regions. It does not rely solely on data provided by Robert Koch Institute like many others do. Instead most of the data comes from crawling websites and APIs (sometimes hidden) of those regions which include much more detailed data like the number of recovered or actively affected patients. Additionally this data is made available over time which can lead to some interesting conclusions and allows for simple forecasting.
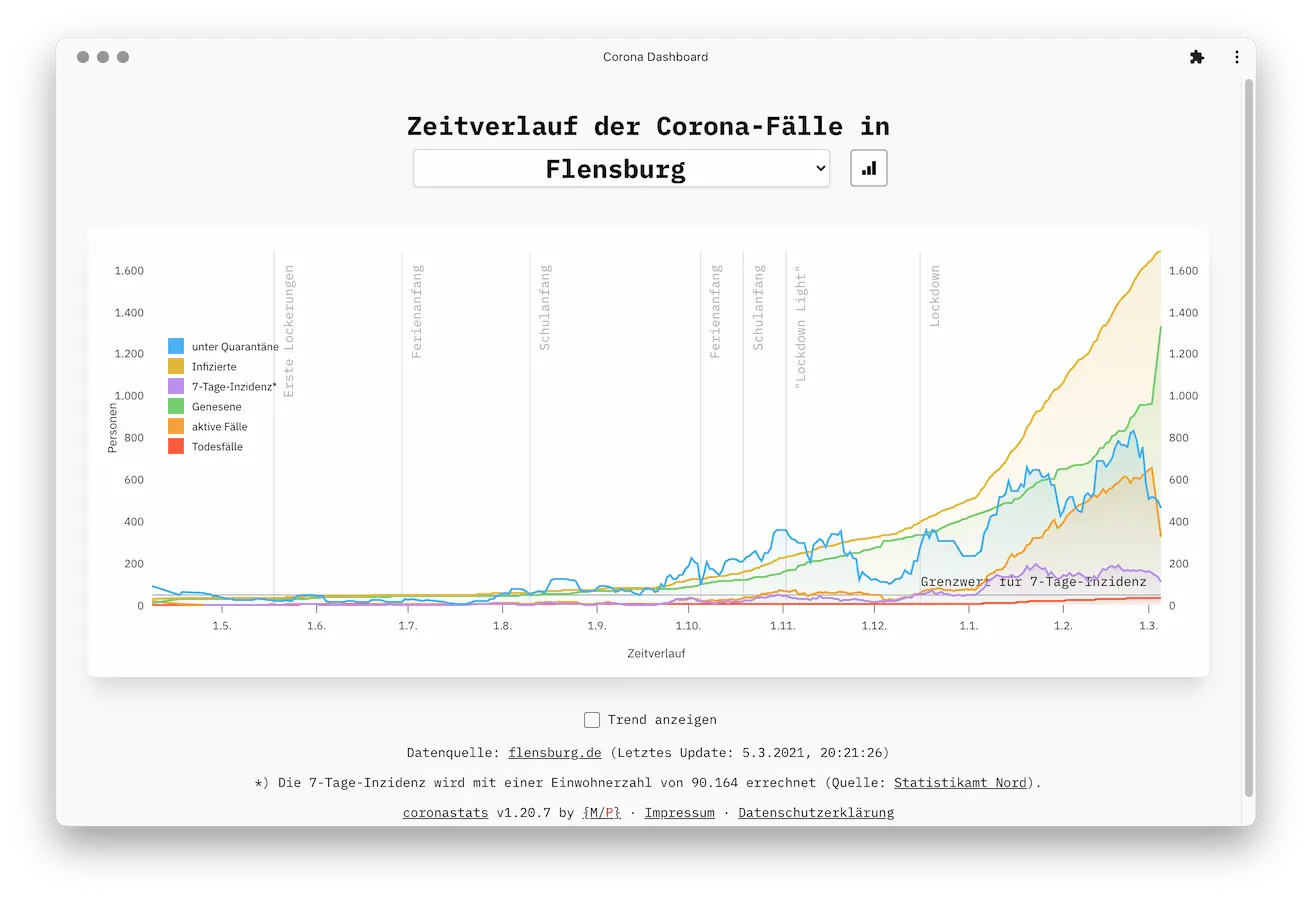

Currently the following regions are supported:
- Flensburg
- Kassel
- Landkreis Kassel
- Landkreis Lüneburg
- Landkreis Rotenburg
- Leipzig
- Kreis Herzogtum Lauenburg
- Kreis Plön
- Kreis Rendsburg-Eckernförde
- Kreis Schleswig-Flensburg
- Kreis Stormarn
The selection is just a result of personal preference and user requests. Be free to suggest others or – even better – provide a pull request for a crawler for other regions!
The frontend consists of a simple React web application that also works as a PWA (so it can be installed as a local app). Data is held in browser storage using PouchDB and synced in the background. Syncing is done transparently as needed and in real-time.
Together with employing Service Workers, this enables full offline support (as you'd expect from a locally installed app).
Data is presented either as an interactive line chart or a sortable table (see screenshots above). You can also enable forecasting which will add a trend analysis for the next 3 days based on the data available. This is done live in the browser using the Timeseries Analysis package.
Data is stored in an Apache CouchDB database. You can find the design documents in the _design folder (only used for authentication for now).
All data is being made publically available via common CouchDB APIs. Drop me a message if you want to use it for other projects!
The crawler is based on Node.js. It's expected to be perdiodically run by a systemd timer or cron job and consists of an individual module per region. The modules usually use jsdom to parse websites or just fetch data from APIs.
Each crawler module is expected to return a promise resolving with an array of objects. These objects should each contain data for a single day of a region. Here's an example for such an object:
[
{
"areacode": "fl",
"date": "2021-02-16T00:00:00.000Z",
"deaths": 27,
"infected": 1344,
"quarantined": 676,
"recovered": 780,
"active": 537
}
]areacode, date, deaths and infected are required. quarantined, recovered and active are optional.
Pull requests for more crawlers / regions are always welcome!
This project's code is free software. You can redistribute it and/or modify it under the terms of the GNU General Public License v3.0.