[English Page] | [文档] | [API] | [DJ-SORA]



Data-Juicer 是一个一站式多模态数据处理系统,旨在为大语言模型 (LLM) 提供更高质量、更丰富、更易“消化”的数据。
Data-Juicer(包含DJ-SORA)正在积极更新和维护中,我们将定期强化和新增更多的功能和数据菜谱。热烈欢迎您加入我们,一起推进LLM数据的开发和研究!
我们提供了一个基于 JupyterLab 的 Playground,您可以从浏览器中在线试用 Data-Juicer。
如果Data-Juicer对您的研发有帮助,请引用我们的工作 。
欢迎提issues/PRs,以及加入我们的Slack频道 或钉钉群 进行讨论!
[2024-06-01] ModelScope-Sora“数据导演”创意竞速——第三届Data-Juicer大模型数据挑战赛已经正式启动!立即访问竞赛官网,了解赛事详情。
- [2024-01-10] 开启“数据混合”新视界——第二届Data-Juicer大模型数据挑战赛已经正式启动!立即访问竞赛官网,了解赛事详情。

-[2024-01-05] 现在,我们发布了 Data-Juicer v0.1.3 版本! 在这个新版本中,我们支持了更多Python版本(3.8-3.10),同时支持了多模态数据集的转换和处理(包括文本、图像和音频。更多模态也将会在之后支持)。 此外,我们的论文也更新到了第三版 。
-
[2023-10-13] 我们的第一届以数据为中心的 LLM 竞赛开始了! 请访问大赛官网,FT-Data Ranker(1B赛道 、7B赛道 ) ,了解更多信息。
-
[2023-10-8] 我们的论文更新至第二版,并发布了对应的Data-Juicer v0.1.2版本!

-
系统化 & 可复用:为用户提供系统化且可复用的80+核心算子,20+配置菜谱和20+专用工具池,旨在让多模态数据处理独立于特定的大语言模型数据集和处理流水线。
-
数据反馈回路 & 沙盒实验室:支持一站式数据-模型协同开发,通过沙盒实验室快速迭代,基于数据和模型反馈回路、可视化和多维度自动评估等功能,使您更了解和改进您的数据和模型。
-
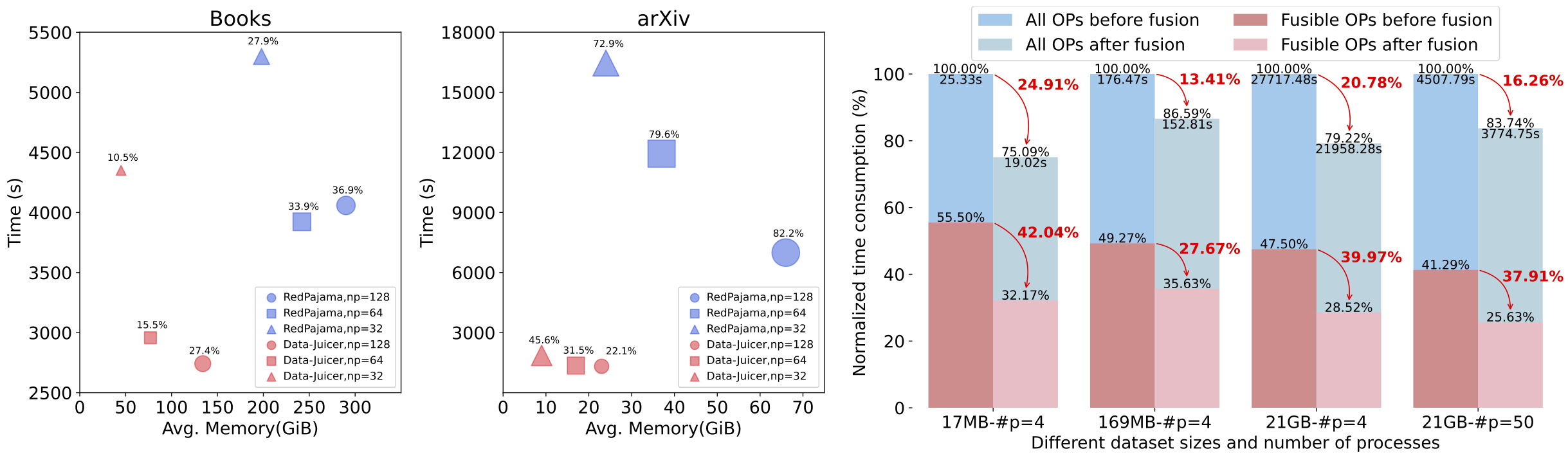
效率增强:提供高效并行化的数据处理流水线(Aliyun-PAI\Ray\Slurm\CUDA\算子融合),减少内存占用和CPU开销,提高生产力。
-
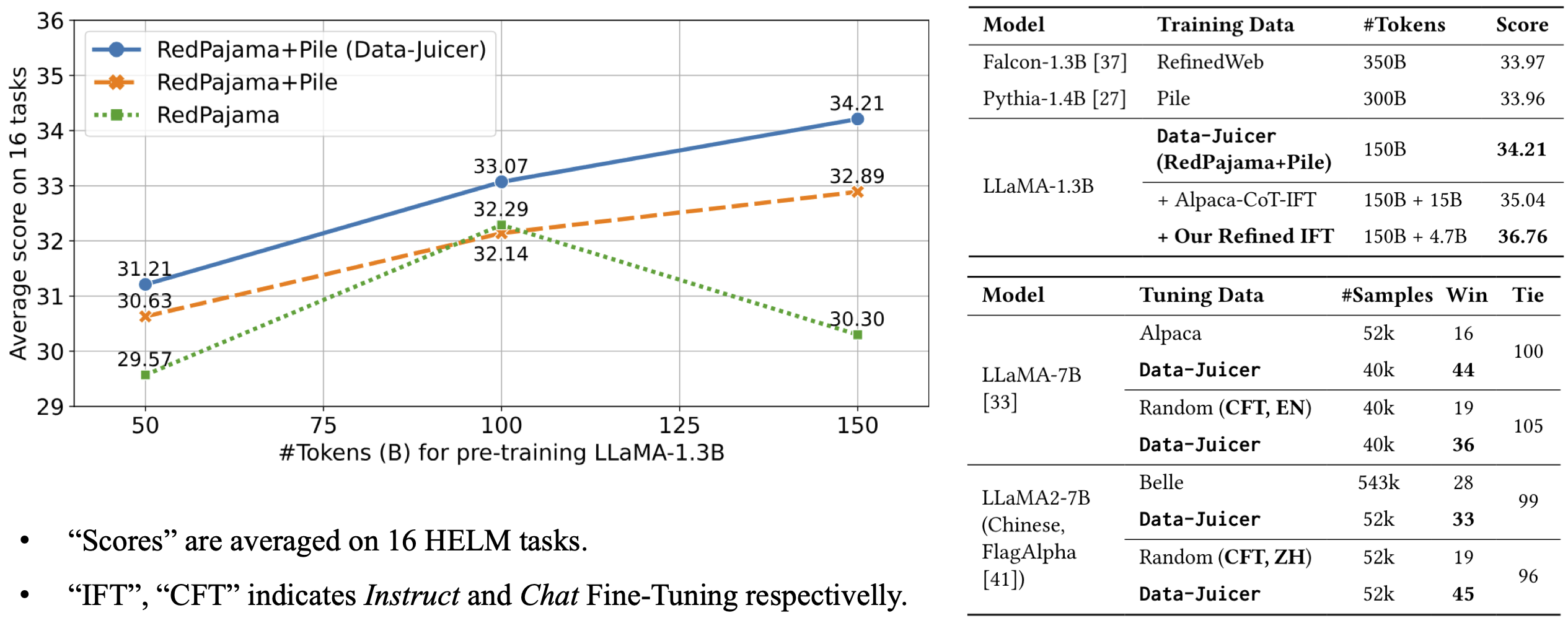
全面的数据处理菜谱:为pre-training、fine-tuning、中英文等场景提供数十种预构建的数据处理菜谱。 在LLaMA、LLaVA等模型上有效验证。
-
灵活 & 易扩展:支持大多数数据格式(如jsonl、parquet、csv等),并允许灵活组合算子。支持自定义算子,以执行定制化的数据处理。
- Data-Juicer 介绍 [ModelScope] [HuggingFace]
- 数据可视化:
- 基础指标统计 [ModelScope] [HuggingFace]
- 词汇多样性 [ModelScope] [HuggingFace]
- 算子洞察(单OP) [ModelScope] [HuggingFace]
- 算子效果(多OP) [ModelScope] [HuggingFace]
- 数据处理:
- 科学文献 (例如 arXiv) [ModelScope] [HuggingFace]
- 编程代码 (例如 TheStack) [ModelScope] [HuggingFace]
- 中文指令数据 (例如 Alpaca-CoT) [ModelScope] [HuggingFace]
- 工具池:
- 按语言分割数据集 [ModelScope] [HuggingFace]
- CommonCrawl 质量分类器 [ModelScope] [HuggingFace]
- 基于 HELM 的自动评测 [ModelScope] [HuggingFace]
- 数据采样及混合 [ModelScope] [HuggingFace]
- 数据处理回路 [ModelScope] [HuggingFace]
- 推荐 Python>=3.8,<=3.10
- gcc >= 5 (at least C++14 support)
- 运行以下命令以安装
data_juicer可编辑模式的最新基础版本
cd <path_to_data_juicer>
pip install -v -e .- 部分算子功能依赖于较大的或者平台兼容性不是很好的第三方库,因此用户可按需额外安装可选的依赖项:
cd <path_to_data_juicer>
pip install -v -e . # 安装最小依赖,支持基础功能
pip install -v -e .[tools] # 安装部分工具库的依赖依赖选项如下表所示:
| 标签 | 描述 |
|---|---|
. 或者 .[mini] |
安装支持 Data-Juicer 基础功能的最小依赖项 |
.[all] |
安装除了沙盒实验以外的所有依赖项 |
.[sci] |
安装所有算子的全量依赖 |
.[dist] |
安装以分布式方式进行数据处理的依赖(实验性功能) |
.[dev] |
安装作为贡献者开发 Data-Juicer 所需的依赖项 |
.[tools] |
安装专用工具库(如质量分类器)所需的依赖项 |
.[sandbox] |
安装沙盒实验室的基础依赖 |
- 运行以下命令用
pip安装data_juicer的最新发布版本:
pip install py-data-juicer- 注意:
- 您可以选择
-
从DockerHub直接拉取我们的预置镜像:
docker pull datajuicer/data-juicer:<version_tag>
-
或者运行如下命令用我们提供的 Dockerfile 来构建包括最新版本的
data-juicer的 docker 镜像:docker build -t datajuicer/data-juicer:<version_tag> .
-
<version_tag>的格式类似于v0.2.0,与发布(Release)的版本号相同。
-
import data_juicer as dj
print(dj.__version__)在使用视频相关算子之前,应该安装 FFmpeg 并确保其可通过 $PATH 环境变量访问。
你可以使用包管理器安装 FFmpeg(例如,在 Debian/Ubuntu 上使用 sudo apt install ffmpeg,在 OS X 上使用 brew install ffmpeg),或访问官方FFmpeg链接。
随后在终端运行 ffmpeg 命令检查环境是否设置正确。
- 以配置文件路径作为参数来运行
process_data.py或者dj-process命令行工具来处理数据集。
# 适用于从源码安装
python tools/process_data.py --config configs/demo/process.yaml
# 使用命令行工具
dj-process --config configs/demo/process.yaml-
注意:使用未保存在本地的第三方模型或资源的算子第一次运行可能会很慢,因为这些算子需要将相应的资源下载到缓存目录中。默认的下载缓存目录为
~/.cache/data_juicer。您可通过设置 shell 环境变量DATA_JUICER_CACHE_HOME更改缓存目录位置,您也可以通过同样的方式更改DATA_JUICER_MODELS_CACHE或DATA_JUICER_ASSETS_CACHE来分别修改模型缓存或资源缓存目录: -
注意:对于使用了第三方模型的算子,在填写config文件时需要去声明其对应的
mem_required(可以参考config_all.yaml文件中的设置)。Data-Juicer在运行过程中会根据内存情况和算子模型所需的memory大小来控制对应的进程数,以达成更好的数据处理的性能效率。而在使用CUDA环境运行时,如果不正确的声明算子的mem_required情况,则有可能导致CUDA Out of Memory。
# 缓存主目录
export DATA_JUICER_CACHE_HOME="/path/to/another/directory"
# 模型缓存目录
export DATA_JUICER_MODELS_CACHE="/path/to/another/directory/models"
# 资源缓存目录
export DATA_JUICER_ASSETS_CACHE="/path/to/another/directory/assets"Data-Juicer 现在基于RAY实现了多机分布式数据处理。 对应Demo可以通过如下命令运行:
# 运行文字数据处理
python tools/process_data.py --config ./demos/process_on_ray/configs/demo.yaml
# 运行视频数据处理
python tools/process_data.py --config ./demos/process_video_on_ray/configs/demo.yaml
- 如果需要在多机上使用RAY执行数据处理,需要确保所有节点都可以访问对应的数据路径,即将对应的数据路径挂载在共享文件系统(如NAS)中。
- RAY 模式下的去重算子与单机版本不同,所有 RAY 模式下的去重算子名称都以
ray作为前缀,例如ray_video_deduplicator和ray_document_deduplicator。这些去重算子依赖于 Redis 实例.因此使用前除启动 RAY 集群外还需要启动 Redis 实例,并在对应的配置文件中填写 Redis 实例的host和port。
用户也可以不使用 RAY,拆分数据集后使用 Slurm / 阿里云 PAI-DLC 在集群上运行,此时使用不包含 RAY 的原版 Data-Juicer 即可。
- 以配置文件路径为参数运行
analyze_data.py或者dj-analyze命令行工具来分析数据集。
# 适用于从源码安装
python tools/analyze_data.py --config configs/demo/analyser.yaml
# 使用命令行工具
dj-analyze --config configs/demo/analyser.yaml- 注意:Analyser 只计算 Filter 算子的状态,其他的算子(例如 Mapper 和 Deduplicator)会在分析过程中被忽略。
- 运行
app.py来在浏览器中可视化您的数据集。 - 注意:只可用于从源码安装的方法。
streamlit run app.py- 配置文件包含一系列全局参数和用于数据处理的算子列表。您需要设置:
- 全局参数:输入/输出 数据集路径,worker 进程数量等。
- 算子列表:列出用于处理数据集的算子及其参数。
- 您可以通过如下方式构建自己的配置文件:
- ➖:修改我们的样例配置文件
config_all.yaml。该文件包含了所有算子以及算子对应的默认参数。您只需要移除不需要的算子并重新设置部分算子的参数即可。 - ➕:从头开始构建自己的配置文件。您可以参考我们提供的样例配置文件
config_all.yaml,算子文档,以及 开发者指南. - 除了使用 yaml 文件外,您还可以在命令行上指定一个或多个参数,这些参数将覆盖 yaml 文件中的值。
- ➖:修改我们的样例配置文件
python xxx.py --config configs/demo/process.yaml --language_id_score_filter.lang=en-
基础的配置项格式及定义如下图所示

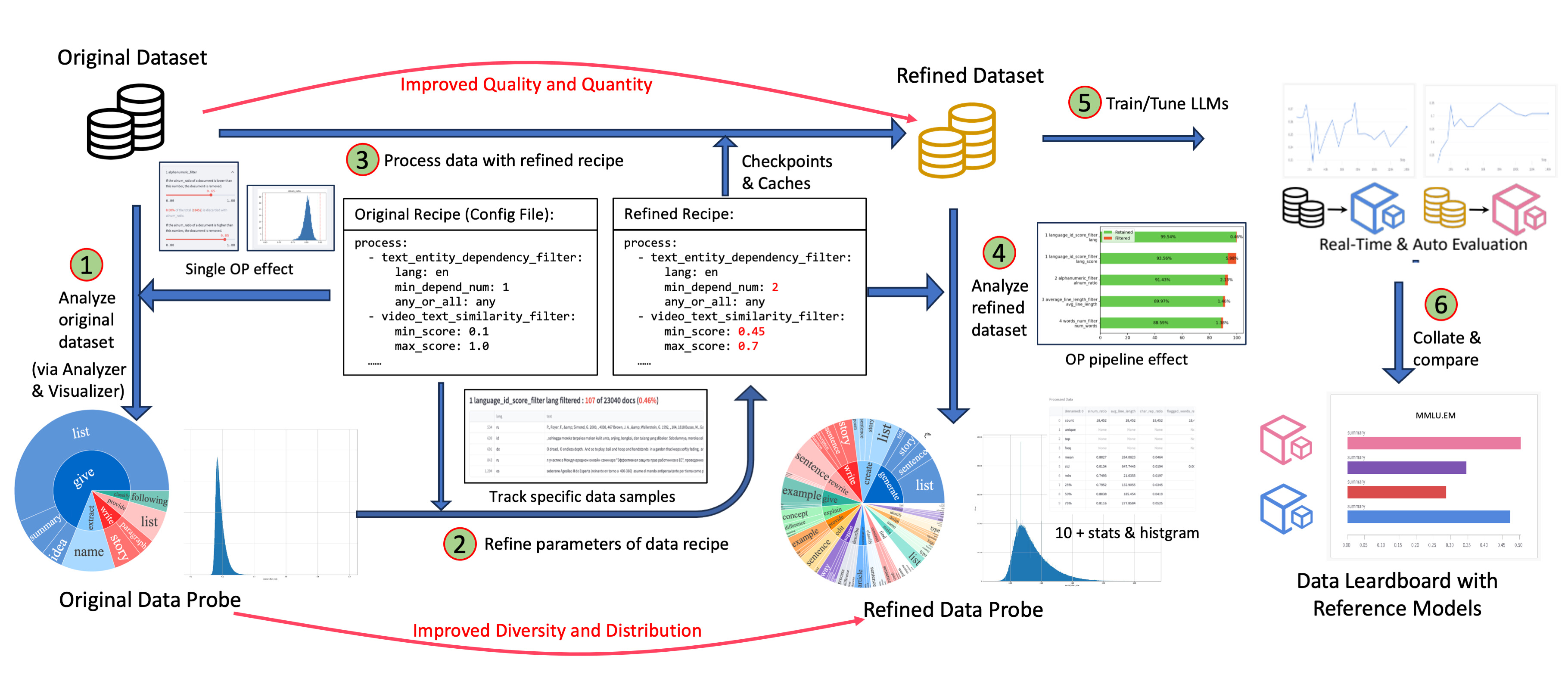
数据沙盒实验室 (DJ-Sandbox) 为用户提供了持续生产数据菜谱的最佳实践,其具有低开销、可迁移、有指导性等特点。
- 用户在沙盒中可以基于一些小规模数据集、模型对数据菜谱进行快速实验、迭代、优化,再迁移到更大尺度上,大规模生产高质量数据以服务大模型。
- 用户在沙盒中,除了Data-Juicer基础的数据优化与数据菜谱微调功能外,还可以便捷地使用数据洞察与分析、沙盒模型训练与评测、基于数据和模型反馈优化数据菜谱等可配置组件,共同组成完整的一站式数据-模型研发流水线。
沙盒默认通过如下命令运行,更多介绍和细节请参阅沙盒文档.
python tools/sandbox_starter.py --config configs/demo/sandbox/sandbox.yaml- 我们的 Formatter 目前支持一些常见的输入数据集格式:
- 单个文件中包含多个样本:jsonl/json、parquet、csv/tsv 等。
- 单个文件中包含单个样本:txt、code、docx、pdf 等。
- 但来自不同源的数据是复杂和多样化的,例如:
- 从 S3 下载的 arXiv 原始数据 包括数千个 tar 文件以及更多的 gzip 文件,并且所需的 tex 文件在 gzip 文件中,很难直接获取。
- 一些爬取的数据包含不同类型的文件(pdf、html、docx 等),并且很难提取额外的信息,例如表格、图表等。
- Data-Juicer 不可能处理所有类型的数据,欢迎提 Issues/PRs,贡献对新数据类型的处理能力!
- 因此我们在
tools/preprocess中提供了一些常见的预处理工具,用于预处理这些类型各异的数据。- 欢迎您为社区贡献新的预处理工具。
- 我们强烈建议将复杂的数据预处理为 jsonl 或 parquet 文件。
- 如果您构建或者拉取了
data-juicer的 docker 镜像,您可以使用这个 docker 镜像来运行上面提到的这些命令或者工具。 - 直接运行:
# 直接运行数据处理
docker run --rm \ # 在处理结束后将容器移除
--name dj \ # 容器名称
-v <host_data_path>:<image_data_path> \ # 将本地的数据或者配置目录挂载到容器中
-v ~/.cache/:/root/.cache/ \ # 将 cache 目录挂载到容器以复用 cache 和模型资源(推荐)
datajuicer/data-juicer:<version_tag> \ # 运行的镜像
dj-process --config /path/to/config.yaml # 类似的数据处理命令- 或者您可以进入正在运行的容器,然后在可编辑模式下运行命令:
# 启动容器
docker run -dit \ # 在后台启动容器
--rm \
--name dj \
-v <host_data_path>:<image_data_path> \
-v ~/.cache/:/root/.cache/ \
datajuicer/data-juicer:latest /bin/bash
# 进入这个容器,然后您可以在编辑模式下使用 data-juicer
docker exec -it <container_id> bashData-Juicer 在 Apache License 2.0 协议下发布。
大模型是一个高速发展的领域,我们非常欢迎贡献新功能、修复漏洞以及文档改善。请参考开发者指南。
如果您有任何问题,欢迎加入我们的讨论群 。
Data-Juicer 被各种 LLM产品和研究工作使用,包括来自阿里云-通义的行业大模型,例如点金 (金融分析),智文(阅读助手),还有阿里云人工智能平台 (PAI)。 我们期待更多您的体验反馈、建议和合作共建!
Data-Juicer 感谢并参考了社区开源项目: Huggingface-Datasets, Bloom, RedPajama, Pile, Alpaca-Cot, Megatron-LM, DeepSpeed, Arrow, Ray, Beam, LM-Harness, HELM, ....
如果您发现我们的工作对您的研发有帮助,请引用以下论文 。
@inproceedings{chen2024datajuicer,
title={Data-Juicer: A One-Stop Data Processing System for Large Language Models},
author={Daoyuan Chen and Yilun Huang and Zhijian Ma and Hesen Chen and Xuchen Pan and Ce Ge and Dawei Gao and Yuexiang Xie and Zhaoyang Liu and Jinyang Gao and Yaliang Li and Bolin Ding and Jingren Zhou},
booktitle={International Conference on Management of Data},
year={2024}
}