Sends emails reliably (supports failover) using services such as Sendgrid and Mailgun
Queuing emails using RESTFul API endpoint:
POST: http://<server>:<port>/mail
[
{
"to": [{"email": "narasimha.gm@gmail.com"}],
"from": {"email": "postman.p@protonmail.com"},
"subject": "hello there",
"content": [ {
"type": "text/plain",
"value": "hello there, how are you doing?"
}
]
},
{
"to": [{"email": "narasimha.gm@gmail.com"}],
"from": {"email": "postman.p@protonmail.com"},
"subject": "hello there",
"content": [ {
"type": "text/plain",
"value": "hello there, great, how are you doing?"
}
]
}
]
Response:
{
"queued": true,
"tracking-ids": [
"0x587e6d1522401000",
"0x587e6d1522801000",
]
}
The response includes the ids (flake ids) assigned to the mails by the RESTFul api. (In future these ids could be used to track the email delivery status).
Worker sends email using sendgrid:

Emails Received:
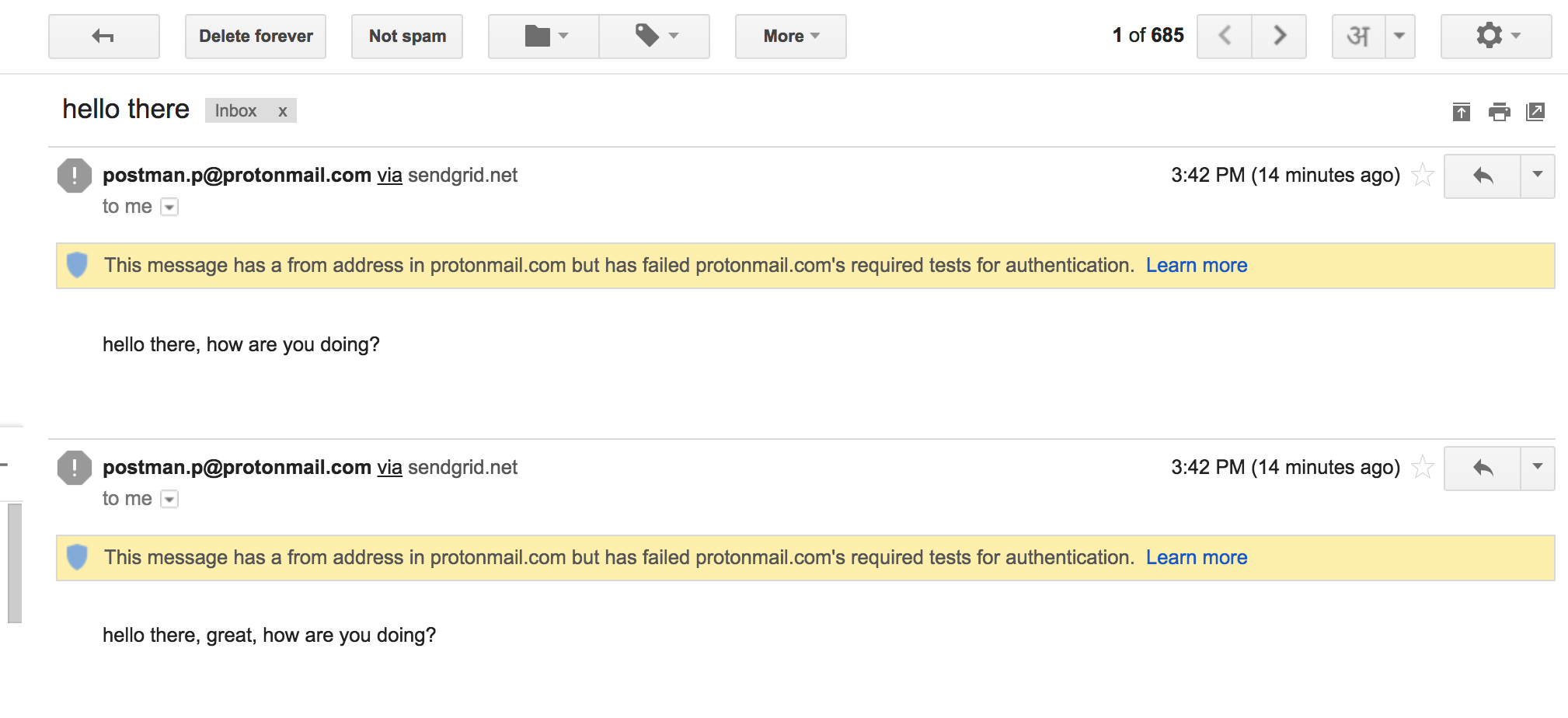
I have employed two fake providers (Fake provider - Lamda and Fake provider - Delta) which fail to send message every second request.
These are configured (deliberatly) as Primary and Secondary in the cirrcuit-breaker (more about circuit-breaker below). In spite of these two functions failing for every second call, all the mails are delivered.
The point to note is that circuit breaker keeps switching to the provider that works:
(The request and response to RESTful API remain same, but four emails are queued)
Below is the screenshot of fake providers working in tandem:
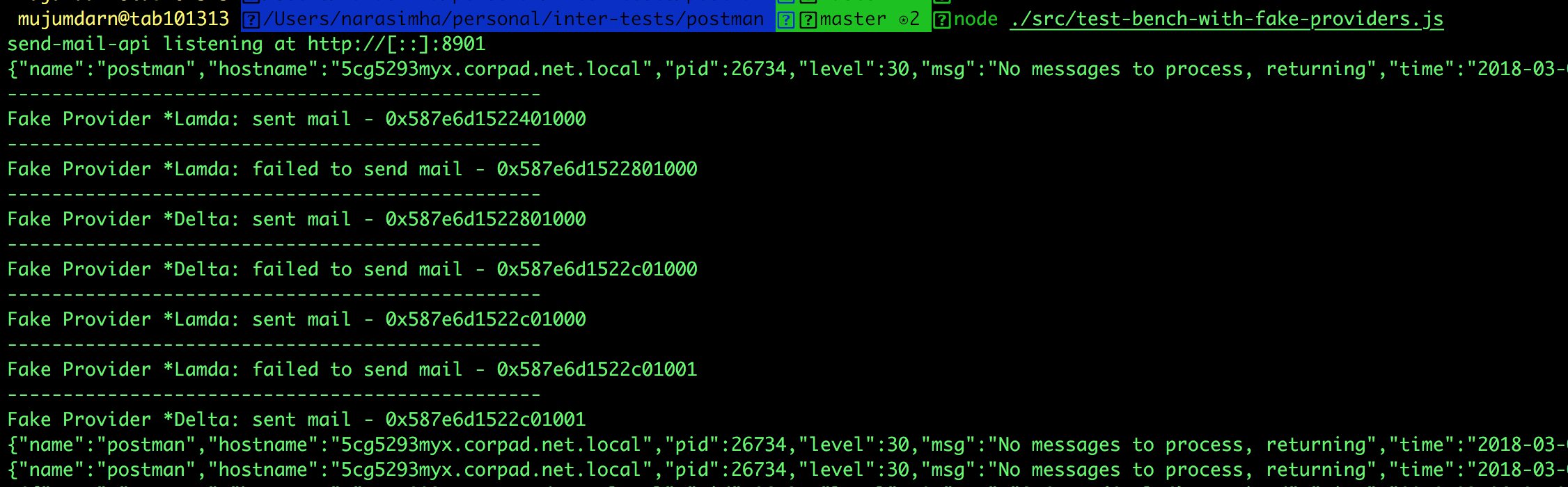
Whats happening above is:
1. Fake Provider *Lamda: sent mail - 0x587e6d1522401000
Sending of mail with id: 0x587e6d1522401000 succeeds with "Fake Provider *Lamda" as the provider
2. Fake Provider *Lamda: failed to send mail - 0x587e6d1522801000
Sending of second mail with id: 0x587e6d1522801000 fails with "Fake Provider *Lamda" as the provider (second request fails).
Now circuit breaker tries using the secondary _Fake Provider *Delta_ as provider and succeeds in sending 0x587e6d1522801000
3. Fake Provider *Delta: sent mail - 0x587e6d1522801000_
Now it starts using "Fake Provider *Delta" as the primary and attempts to send the next mail (id = 0x587e6d1522c01000) using as that as the provider.
But as it is the second call to "Fake Provider *Delta" it fails:
Fake Provider *Delta: failed to send mail - 0x587e6d1522c01000
4. It then attempts to fall back on prrimary "Fake Provider *Lamda" and succeeds:
Fake Provider *Lamda: sent mail - 0x587e6d1522c01000
The same situation is repeated for the last mail that has to be delivered:
Fake Provider *Lamda: failed to send mail - 0x587e6d1522c01001
------------------------------------------------
Fake Provider *Delta: sent mail - 0x587e6d1522c01001
-
Reliablity The service should be able to failover from one provider (say Sendgrid) to another provider (say Mailgun) if the either of the services are not available to deliver emails.
-
Minimal data loss In case there are issues with the providers it should not (ideally) lead to loss of any mails that are to be delivered
-
Configurable It should be possible to plug in new providers or retire existing ones without impacting the availiblity of the system.
-
Scailiblity It should be possible to horizontally scale the service by adding more instances.
-
Flexibity in deployment It should be possible encapsuatle the core functionalities in such way that it if we required we can deploy the service on AWS, Google Cloud, in data centers. A side effect of this goal, is that it should be possible to easily run and debug the application locally.
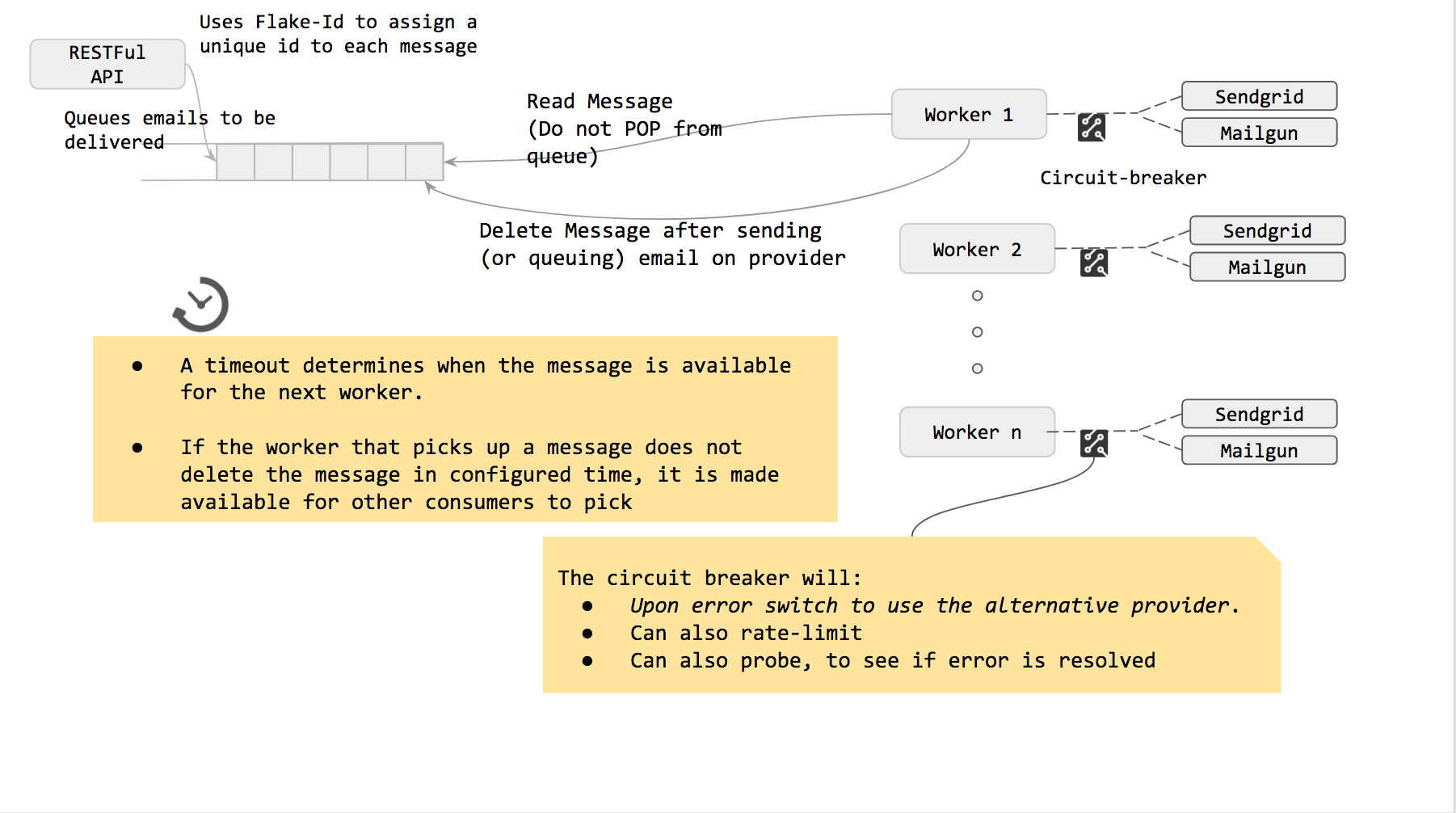
1. The code idea is to have a set of workers fetch mails that need to delivered and pass them the providers.
2. In case the worker faces an issue sending the mail one provider (let us call it the primary), it needs to use an alternative (let us call it the secondary).
2.a. If an error has occured recently in using a provider (say provider A), there is a very good probablity that it might continue to fail for the next few calls.
2.b Thus it is essential for the worker to continue to use the provider that works currently.
2.c. It could try and see if the error (for provider A) is now resolved
2.d If yes, it can move to using provider A
3. The workers can randomly select a provider as primary and other provider as secondary. This way there would be a good distribution of providers being used across workers.
Point 2 calls for the use of circuit breaker. The solution includes a circuit breaker that can accomplish Point 2. It also includes a customizable functionality (injected as functions) to determine:
- When the probe (an attempt to see if the error is now resolved) should be carried out
- Determine if an encountered error is due to provider or something else (most commonly input errors)
The circuit breaker developed in this solution can be used as a library across other projects. It has been unit tested with an attempt to cover all the scenarios.
One of the problems with above approach is this:
- Assume a worker fetches an item from the queue. The item is deleted (dequeued).
- The worker is unable to send the message
This results in the data loss which we are aiming to avoid. To overcome this the queue should support:
- Ability to read from the queue without deleting the item, but at the same time the item not being availble for other workers.
- We can treat
item read by a worker and not being available for other workersas an item being "assigned" to a worker - We need an ability for this "assignment" to expire. (aka visiblity timeout)
- An ability to move an "item" to a
dead-queueafter "n" trials by workers. This effectively takes cares of "poisoned messages" which have errors that cannot be recovered from.
- AWS SQS is a natural choice as it supports all the features that we need "out of the box".
- Redis Queue. Reference: https://redis.io/commands/rpoplpush Sub-section: Pattern : Reliable queue
- In memory queue: This is to used ONLY on local machines for development and debugging.
In a distributed scenario we would have to use AWS SQS or Redis Queue. _The important idea is that the solution encapsulates the queue in such way that any of implementations can be used (as long as they support the required features).
Workers can be deployed as standalone processes or as serverless functions (Ex: AWS lambda).
- It is critical that the workers are fault tolerant and do not exit when it is attempting to send a email. Of course there is very little a worker can do when it is being shutdown forcibily. It can still attempt to try and finish the task in progress. To accomplish this the project employes what is called as a "gaurd".
A gaurd is like a critical section which the worker can use to keep track of things that are in progress. If things are in progress and the worker receives a SIGNINT, it can try and wait until things are finished.
I have not implemented this yet in the solution. This needs to be added.
Assume that there just before the worker posts a mail for delivery, it checks with a store to see if that mail has already been sent. The prescence of such a store would reduce of the occurance of sending duplciate mails (either because a worker died before deleting a mail (but after sending it), or there are duplciate messages on the queues (when the queue does not guarantee only once delivery).
Such a store needs to support atomic insert and lookup. It could get its data from 'proxy that observes all the requests and responses from workers to providers.
This ledger could prevent (all though not all) cases of duplicate messages.
The ledger is currently implemented as a in-memory solution, but ideally is implemented using a datbase such as postgres.
- Start the gaurd
- Read from queue
- Has the ledger seen this mail? is that mail already marked as delivered? (Identified by id: unique flake id)
- If yes, then delete the mail from the queue, return
- If no, then send it (using the circuit breaker)
- Mark the mail as sent in ledger. (This could be done by a proxy later on)
- delete the email
- End the gaurd
We exponse the following RESTFul API to post messages for delivery:
POST: http://<server-url>/mail
Body:
content-type: application/json
content:
[
{
"to": [{"email": "narasimha.gm@gmail.com"}],
"from": {"email": "postman.p@protonmail.com"},
"subject": "hello there",
"content": [ {
"type": "text/plain",
"value": "hello there, how are you doing?"
}
]
}
]
The format supports multiple mails in a single request. The request is valdiated using a JSON validation libraray called strummer (https://www.npmjs.com/package/strummer). Valdations are done against the following definition:
const MaxBatchSize = 10;
const MaxEmailsInTo = 100;
const email = new s.object({
email: new s.email()
});
const content = new s.object({
type: new s.enum({values: ['text/plain']}),
value: s.string()
})
const mailMessage = new s.object({
to: s.array({min: 1, max: MaxEmailsInTo, of: email}),
from: email,
cc: s.optional(s.array({min: 0, max: MaxEmailsInTo, of: email})),
bcc: s.optional(s.array({min: 0, max: MaxEmailsInTo, of: email})),
subject: s.string(),
content: s.array({of: content})
});
const requestPayload = new s.array({min: 1, max: MaxBatchSize, of: mailMessage});
The solution can be deployed over AWS, with SQS as the queues. Ledger stored in postgres (or redis). Workers could be deployed as lambda services.
- Code to use SQS, Redis as queues
- Deployment of worker as lamda function
- Ledger using a Database such postgres (or redis)
- Implement
gaurdfunctinality
Next Step: Deploy on AWS
-
Multi queues to scale the queue (http://arxiv.org/pdf/1411.1209.pdf) A single queue could be subject to contention when the workers tries to get the next mail to send. Instead we could maintain multiple queues to be able scale the solution.
-
Extending circuit breaker to monitor the health of worker Is the worker consuming messages at a lot lesser rate than the average (depending on the number of messages outstanding in the queue)
-
Potential use of proxy to determine if a mail has already been sent A proxy (Ex: nginix reverse proxy) could correlate requests and responses (do any of the providers support this?)
-
Tracking of queued messages (queued on providers) - next step
Appendix: Flake ids http://yellerapp.com/posts/2015-02-09-flake-ids.html