In this project, you will learn how to optimize the performance of a program on a pipelined Y86-64 processor. Our target is the pipelined Y86-64 processor implementation called PIPE-Stall that does not support data forwarding. You need to optimize the bmp_diag() function written in Project #3 so that you can get the most out of the PIPE-Stall processor.
In addition to the original Y86-64 instructions, the PIPE-Stall processor supports the following instructions. You are free to use these instructions in your program.
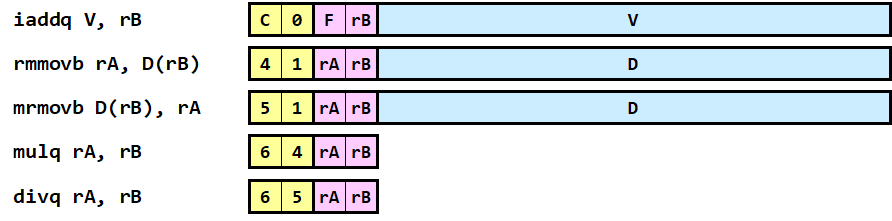
The iaddq instruction adds the 64-bit constant value V to the register rB. The condition code is set accordingly.
The rmmovb instruction stores the LSB (Least Significant Byte) of the register rA into the memory address rB + D, where D is a 64-bit constant. No condition code is affected.
The mrmovb instruction reads a single byte from the memory address rB + D and stores it into the LSB (Least Significant Byte) of the register rA. Other remaining bits in the register rA are cleared to 0. No condition code is affected.
The mulq instruction multiplies rA and rB and stores the result to the register rB. The condition code is set accordingly.
The divq instruction divides rB by rA and stores the result to the register rB. The result is the same as that of the integer division in C (i.e., non-integral results are truncated toward 0). When the divisor (the value of rA) is zero, the result is set to TMin (= 0x8000000000000000) and the OF flag is set. Other ZF and SF flags are set according to the result (even when the divisor is zero).
The original PIPE processor described in the textbook uses data forwarding whenever there is a data dependency among instructions. However, the PIPE-Stall processor stalls if there is a data hazard. Some of example cases are shown below.

Due to the data dependency on the %rax register, the pipeline is stalled for 3 cycles (gray boxes) until the irmovq instruction writes the value to the %rax register in the W stage.

The load/use data hazard is treated in the same way as the data hazard shown above. The addq instruction is stalled for 3 cycles (yellow boxes) until the value read from memory is written into the %rax register. In the above example, note that the mrmovq instruction is stalled for 3 cycles as well (gray boxes), because there is a data dependency on the %rdx register with the previous irmovq instruction.
The call and ret instructions have a data dependency to each other as both require the access to the %rsp register. Also, they have data dependencies to other instructions that manipulate the %rsp register. Let us consider the following program.
0x000: irmovq Stack, %rsp
0x00a: call sub
0x013: halt
0x014: sub:
0x014: xorq %rax, %rax
0x016: ret
.pos 0x100
0x100: Stack:
The above program will be executed in our PIPE-Stall processor as follows:

First, the call instruction is stalled for 3 cycles (yellow boxes) until the location of the stack is written into the %rsp register by the irmovq instruction. The xorq instruction in the procedure sub immediately follows the call instruction because we supply the address of sub (valC of the call instruction) to the next F stage.
Second, the ret instruction is stalled for 2 cycles (gray boxes) in the D stage because it has a data dependency with the previous call instruction for the %rsp register. It cannot proceed until the call instruction writes the modified value to the %rsp register.
Finally, once the ret instruction resumes its execution, the F stage should be stalled until the return address is available (red boxes). The return address becomes available at the end of the M stage of the ret instruction, and this address is fed back to the F stage in the W stage of the ret instruction.
The mispredicted branch is handled in the same way as the original PIPE processor. We also use the always-taken prediction, so the next instruction in the branch target is fetched immediately. The branch outcome is known at the end of the E stage in the conditional branch instruction.
When the branch is mispredicted, the following two instructions are turned into the nop instructions. Consider the following example.
0x000: irmovq $3, %rax
0x00a: miss:
0x00a: iaddq $-4, %rax
0x014: jg miss
0x01d: addq %rcx, %rdx
0x01f: halt
The following diagram shows how the above program is executed in our PIPE-Stall processor.

The iaddq instruction is stalled for 3 cycles (yellow boxes) due to the data dependency on the %rax register with the previous irmovq instruction. As soon as the jg instruction is fetched on cycle 5, the next iaddq and jg instructions are fetched on cycle 6 and 7, respectively, assuming that the conditional branch is taken. However, when the first jg instruction reaches the E stage on cycle 7, it is known that the branch is not taken. Hence, two instructions fetched on cycle 6 and 7 are turned into the nop instructions on cycle 8. Meanwhile, the original jg instruction supplies the address of the next instruction in the M stage so that the addq instruction is fetched on cycle 8.
Your task is to rewrite the bmp_diag() function you have written in Project #3 to optimize its performance on the PIPE-Stall processor. The prototype of bmp_diag() is same as the one in Project #3:
void bmp_diag (unsigned char *imgptr, long long width, long long height, long long gap);
As in Project #3, four arguments are passed in %rdi, %rsi, %rdx, and %rcx registers, respectively. There is no limitation in the register use in this project. You can freely use all the registers available in the Y86-64 architecture (e.g., %rax, %rbx, %rcx, %rdx, %rsi, %rdi, %rbp, %rsp, %r8 ~ %r14). Remember that there is no %r15 in Y86-64.
The following figure shows the memory layout when your program is running. When the power is turned on, the PIPE-Stall processor begins its execution by fetching an instruction at 0x0000. The startup code first sets the stack pointer, initializes registers with arguments for bmp_diag(), and calls the bmp_diag() function which is located at 0x400. The image data is stored in a memory region starting at 0x1000. Due to this layout, the maximum stack size is limited to about 709 bytes (0x300 - startup code size).
0x0000 -> +-----------------------------------------+
| Startup code |
+-----------------------------------------+
| |
| Stack |
0x0300 -> +-----------------------------------------+
0x0400 -> +-----------------------------------------+
| Your code for |
| bmp_diag() |
| |
| |
0x0C00 -> +-----------------------------------------+
| |
0x1000 -> +-----------------------------------------+
| |
| BMP data |
| |
| |
| |
| |
| |
| |
| |
+-----------------------------------------+
The performance of your code will be measured by the total number of cycles to complete the given task. Note that our PIPE-Stall processor stalls for 3 cycles whenever there is a data dependency among instructions. Also, it has 2-cycle penalty for the mispredicted branch and 3-cycle penalty for the ret instruction. Considering these characteristics of the PIPE-Stall processor, you have to optimize the performance of bmp_diag(). You may make any semantics perserving transformations to the bmp_diag() function such as reordering instructions. You may also find it useful to read about loop unrolling in Section 5.8 of the textbook. Loop unrolling is a program transformation that reduces the number of iterations for a loop by increasing the number of elements computed on each iteration.
To receive any credit in this project, your code must be correct first. The 30% of your credit will depend on the test cases which check whether your code is correct or not.
Once you pass all the test cases, you will get a different amount of credits depending on the performance of your code. We will express the performance of your code in units of cycles per pixels (CPP). That is, if the simulated code requires C cycles to complete on the PIPE-Stall processor to change N pixels in the given BMP file, then CPP is C/N.
Since some cycles are used to set up the call to bmp_diag() and to set up the loops, you will get different CPP values for different combinations of image heights, image widths, and the gap values. We will therefore evaluate the performance of your code by computing the average of the CPPs for different parameters. If your average CPP is c, then your remaining credit S will be determined as follows:
| Condition | Score |
|---|---|
| c <= 5.0 | S = 70 points + 10 points bonus |
| 5.0 < c <= 5.5 | S = 70 points |
| 5.5 < c <= 6.0 | S = 65 points |
| 6.0 < c <= 6.5 | S = 60 points |
| 6.5 < c <= 7.0 | S = 55 points |
| 7.0 < c <= 7.5 | S = 50 points |
| 7.5 < c <= 8.0 | S = 45 points |
| 8.0 < c <= 9.0 | S = 40 points |
| 9.0 < c <= 10.0 | S = 35 points |
| 10.0 < c <= 11.0 | S = 30 points |
| 11.0 < c <= 12.0 | S = 25 points |
| 12.0 < c <= 14.0 | S = 20 points |
| 14.0 < c <= 16.0 | S = 15 points |
| 16.0 < c <= 20.0 | S = 10 points |
| 20.0 < c <= 30.0 | S = 5 points |
| c > 30.0 | S = 0 points |
You can use the sequential Y86-64 simulator called ssim to verify the logical correctness of your code. We provide you with the pre-built Linux binary for ssim that understands new iaddq, rmmovb, mrmovb, mulq, and divq instructions, and a sample image data along with the corresponding simulator output (result.out). The output generated by ssim (with the option "-s") for the given image data should match the content of the result.out file. (Try "make test" to compare the result.) The actual number of cycles taken on the PIPE-Stall processor will be available when you run your code on the grading server.
The following skeleton code is provided for this project.
| File | Description |
|---|---|
Makefile |
The main Makefile for this project. |
bmpmain.ys |
The Y86-64 assembly file which contains the startup code and the sample image data. |
bmpdiag.ys |
The Y86-64 assembly file for implementing bmp_diag(). You should submit this file. |
yas |
This is the pre-built Linux binary for Y86-64 assembler that understands new iaddq, rmmovb, mrmovb, mulq, and divq instructions. |
yas-mac |
This is the pre-built macOS binary for yac. |
ssim |
This is the pre-built Linux binary for sequential Y86-64 simulator. Use this simulator to verify the correctness of your implementation. Note that this simulator executes just one instruction at a time. |
ssim-mac |
This is the pre-built macOS binary for ssim. |
result.out |
The sample output. When you give the "-s" option to the ssim simulator, it will automatically dump the memory locations whose values are changed into the file named memory.out. The contents of the memory.out should be identical to this file. (cf. run "make test") |
You can build the Y86-64 object code (*.yo) using the make command. The name of the final Y86-64 object code is bmptest.yo. You can also perform make test to see if your output is correct or not, as shown below.
$ git clone https://github.com/snu-csl/ca-pa4.git
$ cd ca-pa4
$ ls -l
drwxrwxr-x 2 jinsoo jinsoo 4096 5월 27 20:22 .
drwxrwxr-x 11 jinsoo jinsoo 4096 5월 27 19:24 ..
-rw-rw-r-- 1 jinsoo jinsoo 774 5월 27 10:38 bmpdiag.ys
-rw-rw-r-- 1 jinsoo jinsoo 242798 5월 27 10:37 bmpmain.ys
-rw-rw-r-- 1 jinsoo jinsoo 944 5월 27 19:59 Makefile
-rw-rw-r-- 1 jinsoo jinsoo 18503 5월 27 20:16 README.md
-rw-rw-r-- 1 jinsoo jinsoo 100348 5월 27 10:57 result.out
-rwxrwxr-x 1 jinsoo jinsoo 944816 5월 27 20:20 ssim
-rwxrwxr-x 1 jinsoo jinsoo 1021416 5월 27 20:22 yas
$
$ make
/bin/cat bmpmain.ys bmpdiag.ys > bmptest.ys
./yas bmptest.ys bmptest.yo
$
$ ./ssim -v 2 bmptest.yo
31789 bytes of code read
IF: Fetched irmovq at 0x0. ra=----, rb=%rsp, valC = 0x300
IF: Fetched irmovq at 0xa. ra=----, rb=%rdi, valC = 0x1000
IF: Fetched irmovq at 0x14. ra=----, rb=%rsi, valC = 0x66
IF: Fetched irmovq at 0x1e. ra=----, rb=%rdx, valC = 0x67
IF: Fetched irmovq at 0x28. ra=----, rb=%rcx, valC = 0xa
IF: Fetched call at 0x32. ra=----, rb=----, valC = 0x400
Wrote 0x3b to address 0x2f8
IF: Fetched ret at 0x400. ra=----, rb=----, valC = 0x0
IF: Fetched halt at 0x3b. ra=----, rb=----, valC = 0x0
8 instructions executed
Status = HLT
Condition Codes: Z=1 S=0 O=0
Changed Register State:
%rcx: 0x0000000000000000 0x000000000000000a
%rdx: 0x0000000000000000 0x0000000000000067
%rsp: 0x0000000000000000 0x0000000000000300
%rsi: 0x0000000000000000 0x0000000000000066
%rdi: 0x0000000000000000 0x0000000000001000
Changed Memory State:
0x02f8: 0x0000000000000000 0x000000000000003b
$
$ make test
make[1]: Entering directory '/home/jinsoo/ca-pa4'
./ssim -s bmptest.yo
8 instructions executed
make[1]: Leaving directory '/home/jinsoo/ca-pa4'
1a2,2182
> 0x1000: 0x33b02815d1c865fe 0x00002815d1c865fe
> 0x1008: 0x4dd6da7e1fa90d63 0x4dd6da7e1fa90dff
> 0x1018: 0x73ca4175ec41ec9d 0x73ca4175ecff0000
> 0x1020: 0x1eeef5bbbb4492a6 0x1eff0000bb4492a6
...
Makefile:46: recipe for target 'test' failed
$
The skeleton code can be downloaded from Github at https://github.com/snu-csl/ca-pa4/. If you don't have the git utility, you need to install it first by performing "sudo apt install git" command.
The skeleton code has pre-built macOS binaries, yas-mac and ssim-mac. If you want to work on macOS, you need to specify the use of these executable files in Makefile as follows:
...
YAS = ./yas-mac
SSIM = ./ssim-mac
...
In addition, yas-mac requires the flex (lexical analyzer) library. The flex library can be installed using the Homebrew utility which is a package manager for Macs. If you don't have Homebrew yet, install it using the following command:
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
Now, the flex library can be installed by issuing the followign command:
$ brew install flex
-
The code size of
bmp_diag()should be less than or equal to 1024 bytes. Thebmp_diag()function starts at the address0x400. Therefore the address of your code should be within0x800. -
Your
bmp_diag()implementation should work for BMP images of any size. -
Your
bmp_diag()implementation should work for any positive value ofgap. -
Your
bmp_diag()implementation should leave the bytes in the padding area untouched. -
There is no restriction in the register usage. You can freely use any of Y86-64 registers. Also, you can use stack for temporary storage, but the maximum stack size is limited to 709 bytes.
-
The total number of cycles in the PIPE-Stall simulator is set to 10,000,000 cycles. If your program runs longer than this limit, it will be terminated.
- Submit only the
bmpdiag.ysfile to the submission server.
- You will work on this project alone.
- Only the upload submitted before the deadline will receive the full credit. 25% of the credit will be deducted for every single day delay.
- You can use up to 5 slip days during this semester. If your submission is delayed by 1 day and if you decided to use 1 slip day, there will be no penalty. In this case, you should explicitly declare the number of slip days you want to use in the QnA board of the submission server after each submission. Saving the slip days for later projects is highly recommended!
- Any attempt to copy others' work will result in heavy penalty (for both the copier and the originator). Don't take a risk.
This is your last project. Good luck and thanks for all your hard work during this semester.
Jin-Soo Kim
Systems Software and Architecture Laboratory
Dept. of Computer Science and Engineering
Seoul National University