OriginalDesignDoc
- Developer Experience
- Services API
- Logging
- Job Status
- Job status tracking and error handling
As simple as possible, but no simpler should be the goal. This framework needs to enable developers to create complex and interactive reports while also guiding them towards solutions that will ensure good performance and reduce errors.
$ npx seasketch-geoprocessing init
⌛ cloning template
⌛copying name and email from git config
What would you like to name your project?
BermudaReports
creating ./BermudaReports
Please write a description
MPA habitat and socio-economic impact reports for the Blue Prosperity Bermuda project.
Please provide a git repository where this project will be hosted:
https://github.com/seasketch/BermudaReports
Provide a homepage for your project [optional]
⌛ writing package config
⌛ installing dependencies
Your project configuration can be found in ./BermudaReports/project.yml
Next steps:
* `npm run add_gp` to create a new geoprocessing service
* `npm run add_preprocessing` to create a new preprocessing service
* `npm run add_report` to create a new report client
* `npm run add_tab` to create a new report client tab
Tips:
* Create examples in SeaSketch, then export them as GeoJSON and save them in
./examples for use in test cases and when designing reports
* The ./data directory is where you can store scripts for generating data
products for use in your geoprocessing. It's already setup with some useful
Docker containers with data-prep software.
$ npm run add_gp
What would you like to call your geoprocessing service?
Habitats
Will this service use Docker containers [N/y]?
n
What execution model should this service run on?
1) Sync - Best for quick (< 2s) running reports
2) Async - Better for long-running processes
Would you like to use typescript [Y/n]?
⌛ creating service scaffolding
⌛ updating config
New geoprocessing service can be found under src/services/Habitats
User can then
- Populate
./exampleswith test case sketches - Store raw data in
./dataand use tools to build data products like indexed & subdividedVectorDataSource's - Write type definitions for expected geoprocessing output
- Implement geoprocessing function and test cases
- Create new report and report tabs that use the output data, interactively testing using Storybook
- Deploy to S3
- Integrate with their project on S3
This documentation pertains to the internals of the http request api. Users of the framework shouldn't need to concern themselves with these details
@seasketch/geoprocessing should support many report implementations over a long period of time. This will require a solid API design for running tasks that can evolve through versioning and support different client implementations. This system is to be decoupled from the main SeaSketch infrastructure and support 3rd party developers. Key challenges that the design needs to address include:
- Serving results to clients with low latency
- Getting potentially very large geometries to geoprocessing scripts in an efficient and secure manner
- Securing access to geoprocessing scripts and data themselves
- Supporting both quick-running reports and long-running analyses that may run for hours
- Includes client-side javascript implementation of the reports api
- Support client-side and offline geoprocessing when possible
- Suports authoring of PreProcessing services to validate and modify user input
- Provide mechanisms to author Digitizing Feedback Handlers that interactively clip and/or validate user input as they draw, as well as show key stats on habitats and other areas captured.
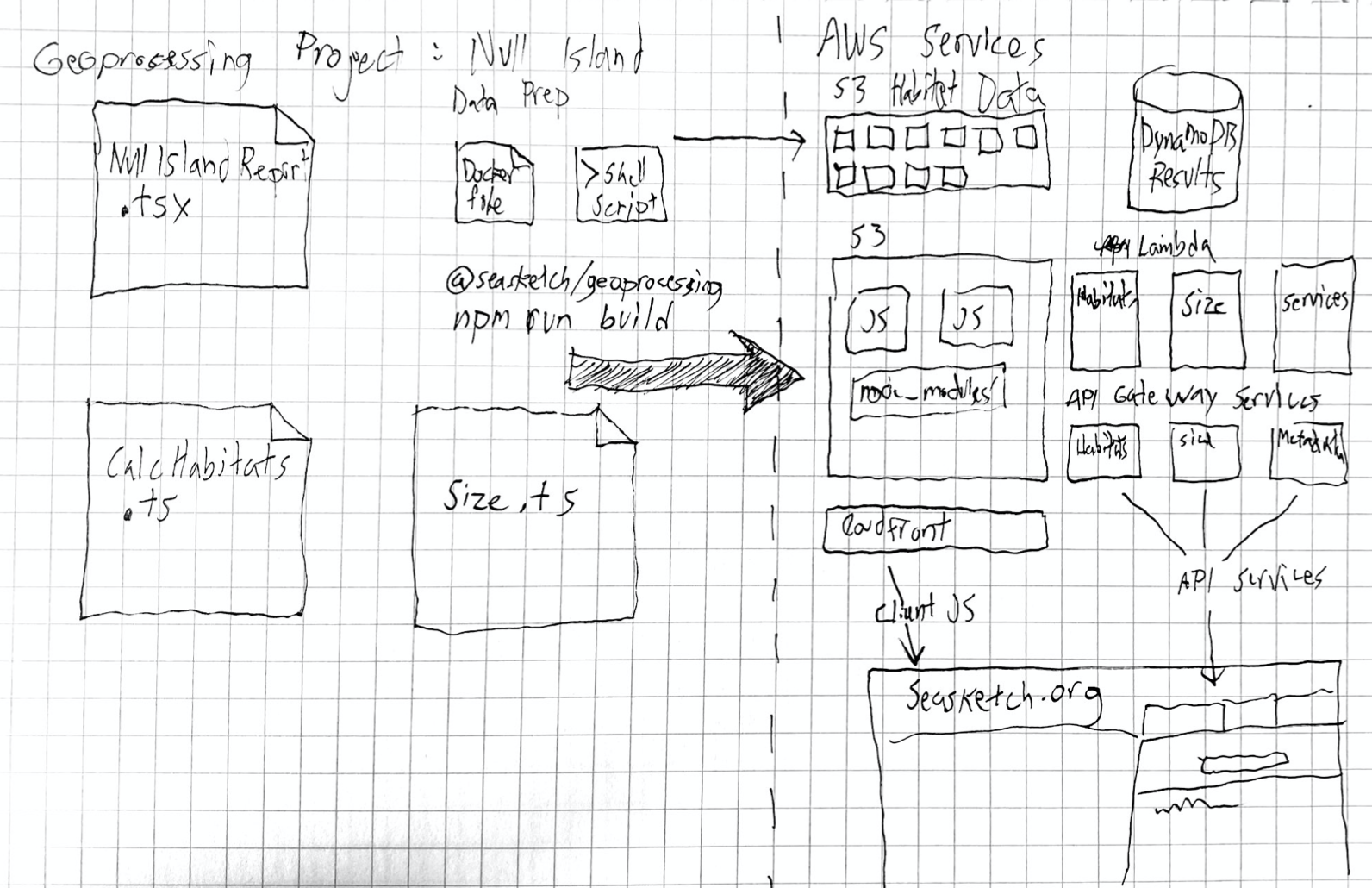
Geoprocessing services are deployed as part of a Project. A Project contains one or more services and reporting client implementations. This enables authors to include multiple implementations within the same source repo in support of a single SeaSketch site.
The root service endpoint contains details about all service and javascript clients in the project. This info can be exposed in the admin interface of a SeaSketch project, and used to inform clients how to interact with services. It is updated each time the project is published.
GET /
// response
interface GeoprocessingProject {
apiVersion: string; // semver
serviceUri: string;
geoprocessingServices: GeoprocessingService[];
preprocessingServices: PreProcessingService[];
clients: ReportClient[];
feedbackClients: DigitizingFeedbackClient[];
// Labelling and attribution information may be displayed
// in the SeaSketch admin interface
title: string;
author: string;
organization?: string;
relatedUrl?: string; // May link to github or an org url
sourceUri?: string; // github repo or similar
published: string; // ISO 8601 date
}
interface GeoprocessingService {
title: string;
endpoint: string;
type: GeoprocessingServiceType;
executionMode: ExecutionMode;
usesAttributes: string[];
medianDuration: number; //ms
medianCost: number; //usd
timeout: number; //ms
rateLimited: boolean;
rateLimitPeriod: RateLimitPeriod;
rateLimit: number;
rateLimitConsumed: number;
// if set, requests must include a token with an allowed issuer (iss)
restrictedAccess: boolean;
// e.g. [sensitive-project.seasketch.org]
issAllowList?: Array<string>;
// for low-latency clientside processing and offline use
// v2 or later
clientSideBundle?: ClientCode;
}
interface ClientCode {
uri: string; // public bundle location
offlineSupported: boolean;
}
interface PreprocessingService {
title: string;
endpoint: string;
usesAttributes: string[];
timeout: number; //ms
// if set, requests must include a token with an allowed issuer (iss)
restrictedAccess: boolean;
// e.g. [sensitive-project.seasketch.org]
issAllowList?: Array<string>;
// for low-latency clientside processing and offline use
// v2 or later
clientSideBundle?: ClientCode;
}
interface ReportClient {
title: string;
uri: string;
bundleSize: number; //bytes
apiVersion: string;
tabs: ReportTab[];
}
interface ReportTab {
title: string;
}
type ExecutionMode = "async" | "sync";
type RateLimitPeriod = "monthly" | "daily";
type GeoprocessingServiceType = "javascript" | "container";
interface DigitizingFeedbackClient {
title: string;
uri: string;
bundleSize: number; //bytes
apiVersion: string;
offlineSupport: boolean;
}Making a geoprocessing request involves POST-ing a json document to the service endpoint in the following format:
interface GeoprocessingRequest {
geometry?: Feature | SeaSketchFeatureCollection;
geometryUri?: string; // must be https and return a GeoBuf
token?: string; // jwt token that can be verified using .well-known/jwks.json
cacheKey?: string;
}Geometries in SeaSketch can be represented by plain GeoJSON, with the exception
of Collections. A GeoJSON FeatureCollection has no properties element, where
in SeaSketch it is important that attribute information is included. So a Collection
can be represented with a schema like so:
import { GeoJsonProperties, FeatureCollection } from 'geojson';
interface SeaSketchFeatureCollection extends FeatureCollection {
properties: GeoJsonProperties;
}
For now SeaSketch does not allow nesting of SeaSketchFeatureCollections, but the
application will support the use of arbitrary folders for organization purposes.
This information is exposed via a folderId? property in each feature.
There is flexibility in how data is provided to the service. For testing clients and cases where the
geometry is very simple, embedding GeoJSON in the request body is sufficient. In
many cases it will be necessary to use geometryUri as an alternative. Some
FeatureSets may be too big to stuff into a request body, and often clients just
don't have the full GeoJSON to send if they are rendering simplified or tiled
representations of the geometry.
Responses to geometryUri requests should return data encoded as a geobuf. This compact encoding should decrease latency between components of the system.
When fetching the geometry via network the geometry must be accessible solely
using the value of geometryUri. There are many ways to secure user data, such as
using an long and opaque unique url, embedding a
jwt in the
request parameters (which could utilize exp), and/or whitelisting the
geoprocessing service host. These details are left for the clients to implement.
Certain reports may be restricted because they contain sensitive data or are
just to costly to run for unauthorized users. Project authors can in these cases
set the service to have restrictedAccess along with a set of allowed token issuers as seen in the metadata endpoint. Clients in this case must provide a JSON Web Token in each request. This token must be verifiable using the issuer's JSON Web Key Set endpoint and the service will respect the token's expiration field.
The token itself will identify the issuer so that the service can evaluate whether to grant access. There is also a deeper level of access control that token issuers may use to limit their own users to a subset of services. The jwt payload may include an allowedEndpoints list.
{
"allowedEndpoints": ["1234abcd.execute-api.us-west-2.amazonaws.com/serviceA", "..."]
}Using this scheme clients such as SeaSketch may provide project administrators the option to limit certain services to certain users, and pass those restrictions on to the geoprocessing service to enforce.
In all cases, failed authorization will result in a 403 Forbidden response.
Responding to requests as quickly as possible means first and foremost avoiding extra work. Clients are ultimately responsible for providing a cache key with their request. This will be combined with either a hash of the geojson provided or the geometryUri to avoid security issues with users requesting access to results that don't belong to them. Clients can create these cache keys using varying complexities of approaches.
- The easiest, don't provide a key but get no caching
- hash(updatedAt.toString() + id)
- Use the
usesAttributesservice metadata to determine what attributes are utilized by the service, and create an appropriate hash e.g. hash(geometryHash + propA + propB) - hash(geometryHash + sketchPropertiesHash)
Note that for collections, hashes must be combined for each child. #3 & #4 could get complicated, but also could be very efficient if geometryHashes are pre-calculated on the server. This is the approach we should take for seasketch-next ultimately, but in the meantime approach #2 should be adequate.
All services respond with the following JSON but will need to be interpreted differently by clients depending on the executionMode.
interface GeoprocessingTask {
location: string;
startedAt: string; //ISO 8601
duration?: string; //ms
logUriTemplate: string;
geometryUri: string;
status: GeoprocessingTaskStatus;
wss?: string; // websocket for listening to status updates
data?: object; // result data can take any json-serializable form
}
type GeoprocessingTaskStatus = "pending" | "completed" | "failed";For sync services the initial request will respond with a GeoprocessingTask
object with a status of "completed" or "failed". These are very simple to
interpret. Asynchronous responses are more complex. They will very likely return
in a "pending" state and the client will need to either poll location (not
recommended) or subscribe to the websocket connection wss.
Using the wss endpoint for async tasks can be accomplished with the native
WebSocket API.
The event data sent to clients will be the same GeoprocessingTask object, but
with updates to status and result data. Once status has changed to "completed"
or "failed" the connection will be closed by the server. Upon connection to
socket, if the task is already complete the server will send the completed
GeoprocessingTask event and close the connection immediately. This way there
should be no race condition when attempting to retrieve results.
While waiting for a geoprocessing task to complete there is information that can
be used to provide progress indicators and log messages. The
GeoprocessingService metadata object contains a medianDuration in ms. By keeping
track of the start time clients can show a progress indicator based on this ETA.
For async services the logUriTemplate can be used to display logs before the
results are complete. location can be linked in the UI to take users to a page
that includes lots of useful debugging information about a geoprocessing task
run.
logUriTemplate can be resolved to retrieve log messages. It is limited to 100
messages by default but can be specified using the limit query param. The
nextToken param can also be used to specify an offset if a limit is reached
and returned in the previous results.
Preprocessing is a good deal different from the Geoprocessing use-case. Clients send a user-drawn geometry that is expected to be validated by the preprocessing script. Shapes may fail validation for issues such as being outside the study area, or inside military test areas. Preprocessing scripts also modify user shapes, nearly always clipping them to shoreline, but also possibly against other features such as management regimes or around infrastructure.
There's not much to it. No need for caching since user drawings are unlikely to be the same, and this process should be fast. Sensitive data is not expected to be used and so there are no security measures in place other than generic rate-limiting. Because of these simple properties, it's just a matter of POSTing a GeoJSON document directly to the endpoint with a Point, Line, or Polygon feature.
The only important detail is that a PreprocessingService may have usesAttributes
specified, in which case these attributes should be in the Feature's properties.
Note that in SeaSketch-Next, most preprocessing will ideally be done in the client for minimum latency. The server may then use the lambda service to verify the geometry has not been tampered with by clients (this may not be necessary).
Logging is a thorny problem in this space and frankly it's appaling that AWS doesn't provide better tools. For this system to work, logs from potentially multiple lambda processes and Fargate containers need to be correlated. Because this situation and the buzzwords around potential solutions are so confusing I'm going to be recording my thoughts here.
This service is bandied about as a solution for debugging multiple event sources and microservices around a single request. It does not seem to handle logs however. I may need to more deeply research this and maybe even make a demo app to understand it.
One solution would be to store IDs for each service in a list on the GeoprocessingTask record so that Cloudwatch logs can be filtered using them later. It would be better to have a single ID but if that's not possible... it's just not possible.
how do?
All cloudwatch messages for all geoprocessing scripts are routed to the same sqs channel and interpretted by the central analysis server. It keeps records of requestIds and forwards them to an internal database. In a way it is using the store correlation ids approach, but it relies in certain cases on discovering new correlation ids by identifying new ones in the same message as a known requestID.
This requires a lot of processing, but makes fetching logs out of the db cheap and enables pushing them to the client. The amount of effort and compute resources needed to support this is out of touch with how useful log push is though. In the next version logs should just be polled. They aren't used for much other than debugging.
By default logs should be purged after a reasonable interval, say 30 days. If it's easy it would nice to have a user setting but it's not a high priority.
Updating the geoprocessing task status to indicate a pending, failed, or completed state helps drive appropriate client display and is needed to report outages.
The prototype seasketch-sls-geoprocessing project managed status updates by looking for indicators in logs. The rationale for this approach was that logs were being pushed into sqs anyways, and exceptions were difficult to handle prior to lambda supporting async/await.
Catching exceptions is easier with v10 so it should be possible to catch them in the lambda and report them via dynamodb. Failures of the surrounding handler should be very rare to non-existent, but some facility to catch them via timeouts should be considered.
How do?