crypto performance notes in iojs v1.8.0
OpenSSL in iojs v1.8.0 was upgraded from 1.0.1m to 1.0.2a. The new version of OpenSSL includes the AVX/AVX2(Advanced Vector Extensions) support which makes the most use of CPU performance on the latest Intel processors such as Haswell. This feature gives iojs several performance gains to crypt, tls and https modules for
- Calculations in RSA, DSA and DH
- Hash generations of SHA-1, SHA256 and SHA512
- GCM operations especially with AES
In the iojs of v1.8.0, its build system was changed so as to check the version of assembler and use AVX/AVX2 assembly codes if available.
This note describes its requirements and shows some benchmark results in comparison between iojs-v1.7.1 and 1.8.0 running on Haswell and Ivy Bridge.
In order to use AVX or AVX2 support in iojs, the following version of assembler is needed.
Visual Studio Version >= 2012, llvm version >= 3.3 or GNU as version >= 2.23
You can find the version for gcc on Linux by
$ gcc -Wa,-v -c -o /dev/null -x assembler /dev/null
GNU assembler version 2.24 (x86_64-linux-gnu) using BFD version (GNU Binutils for Ubuntu) 2.24and for clang on MacOS by
$ cc -v
Apple LLVM version 6.1.0 (clang-602.0.49) (based on LLVM 3.6.0svn)
Target: x86_64-apple-darwin14.3.0
Thread model: posixIf the assembler does not meets the requirement above, iojs is built with assembly codes without AVX/AVX2 support.
AVX is supported since Sandy Bridge and AVX2 is supported since Haswell. You can check it by obtaining a CPU model with
$ ./iojs -e "console.log(require('os').cpus()[0].model)"
Intel(R) Xeon(R) CPU E5-2666 v3 @ 2.90GHzand look up the processor spec at http://ark.intel.com/products/81706 that shows Instruction Set Extensions is AVX 2.0.
On Linux, it can be found at the flags field in /proc/cpuinfo
$ grep avx2 /proc/cpuinfo
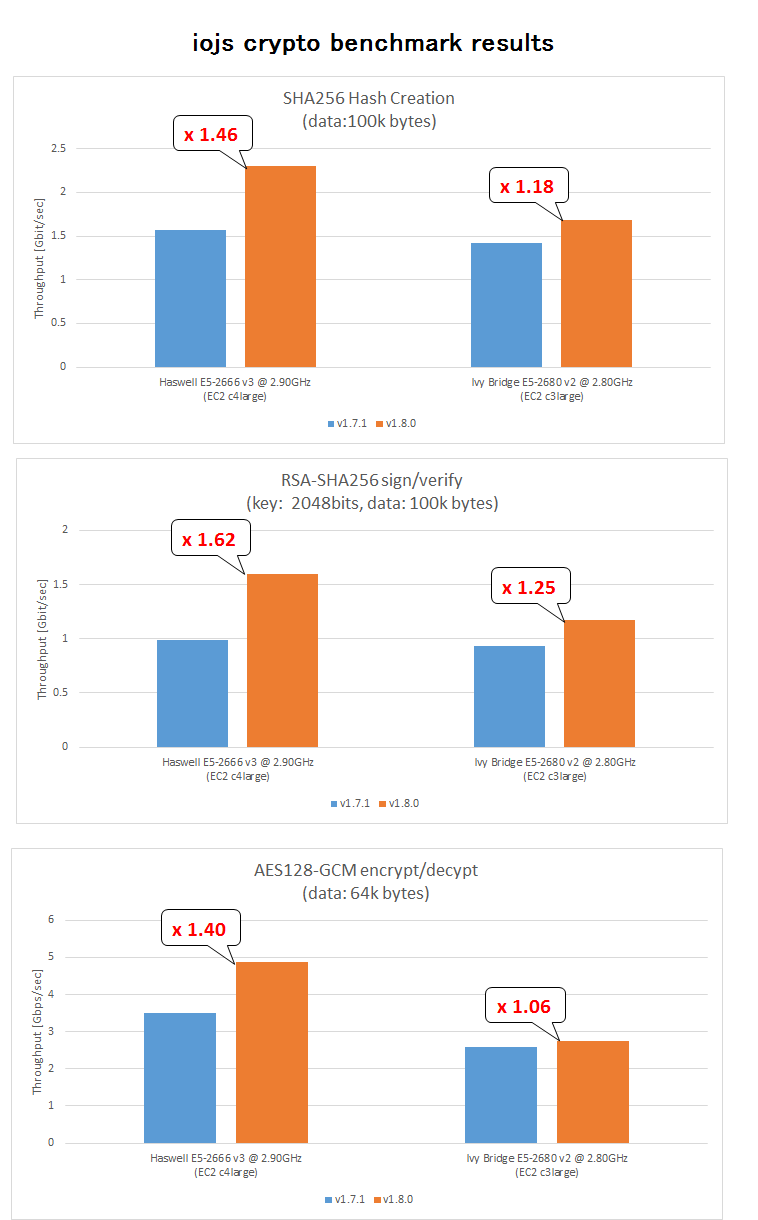
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx rdtscp lm constant_tsc rep_good nopl xtopology eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm xsaveopt fsgsbase bmi1 avx2 smep bmi2 erms invpcidThe benchmarks of SHA256, RSA and AES128-GCM throughput were made on AWS EC2. The instance type of c4large use Haswell(AVX/AVX2) and that of c3large does Ivy Bridge(AVX).
The figure in below shows that about 140% - 160% performance gain on Haswell in iojs-v1.8.0 and up to 125% on Ivy Bridge in RSA, SHA256 and AES-GCM operations. It is noted that smaller size of data has so much gains as this. With the increase of the data size, the gain is increased and saturated up to around 160% at the size of several mega bytes in the case of Haswell.