
We introduce a supervised method for detecting pedestrian crosswalks with DCNNs and Python. The project is based on YOLO framework, developed by Ultralytics. The code is written on Google Colab, a platform to execute code on the Cloud, in the form of Jupyter Notebook. It provides also a GPU, needed for the project. The v1.2.0 of the detector uses YOLOv5, then we updated it to state-of-art model YOLOv8 in the version v1.4.0.
We have created a detector for pedestrian crossings, as more and more often we hear about road accidents with the involvement of pedestrians. Every 32 hours, a pedestrian is run over and killed, a staggering number. This explains the reason for our research. In addition, this detector can also be used by blind people, ensuring greater safety on the road.
In this phase we took the photos, at different times of the day (morning, afternoon, evening), in different light conditions, with different cameras, in different weather conditions and different perspectives. To label the images we used “LabelImg”, completely free tool. LabelImg generates a YOLO .txt file for each image. It has coordinates in YOLO format object-id, center_x, center_y, width, height.
- object-id represents the number corresponding to the category of objects listed in the 'classes.txt' file
- center_x and center_y represent the central point of the selection rectangle
- width and height represent the width and height of the rectangle.

We labeled two pedestrian crossings at a time, to avoid selecting too large a portion of the image.
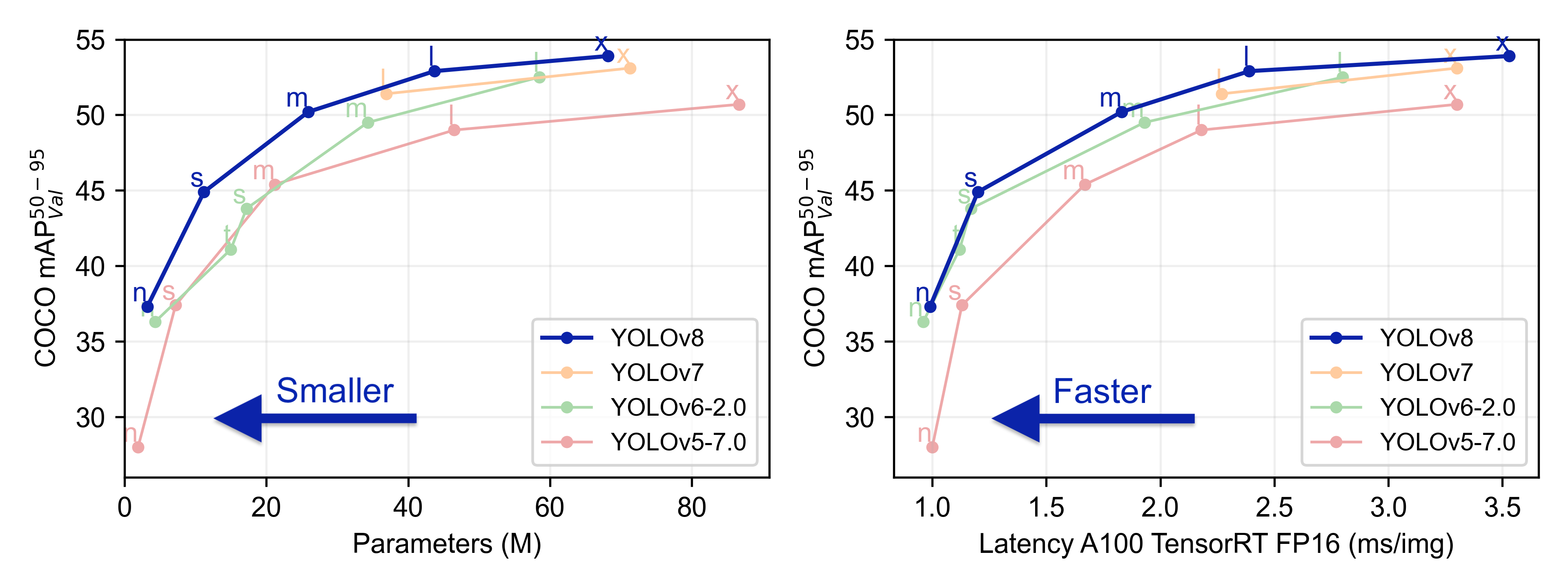
We took the pre-trained model YOLOv8m, then re-trained it with 300 epochs; we could not choose a better model due to the GPU RAM limitations of Google Colaboratory. YOLOv8 is the version of YOLO that was chosen, not only for its effectiveness but above all for its speed, as well as for the possibility of choosing the pre-trained weight to use.
A major challenge was to merge the various bounding boxes. For our problem, in the state of art, we could not find any algorithm already tested and working. For this reason, we have personally implemented an algorithm for bounding boxes merge in Python, using OpenCV.

We know that OpenCV, in order to construct a rectangle, uses the coordinates of the highest left vertex and the lowest right vertex expressed in pixels, while the YOLO labels provide us with the coordinates of the center, width and height of the single bounding box. In our algorithm, after transforming the coordinates from YOLO to OpenCV, we took the minimum x and y coordinates for the top left vertex, while the maximum x and y coordinates for the lower right vertex.
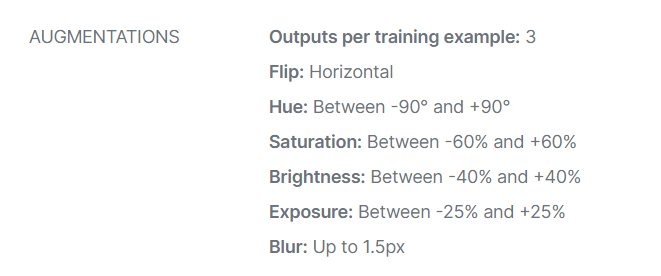
The photos were taken personally, then the dataset was uploaded into Roboflow to create the dataset. At this point, we carried out the augmentation step, as we can see the image below.
As results we have 1046 images for training, 224 for validation, and 224 to calculate the test metrics. We reserved 75% of the images for training, 15% for validation and 15% for testing. We took an additional 202 photos which we used to calculate the inferences.

The results are in line with what was expected.
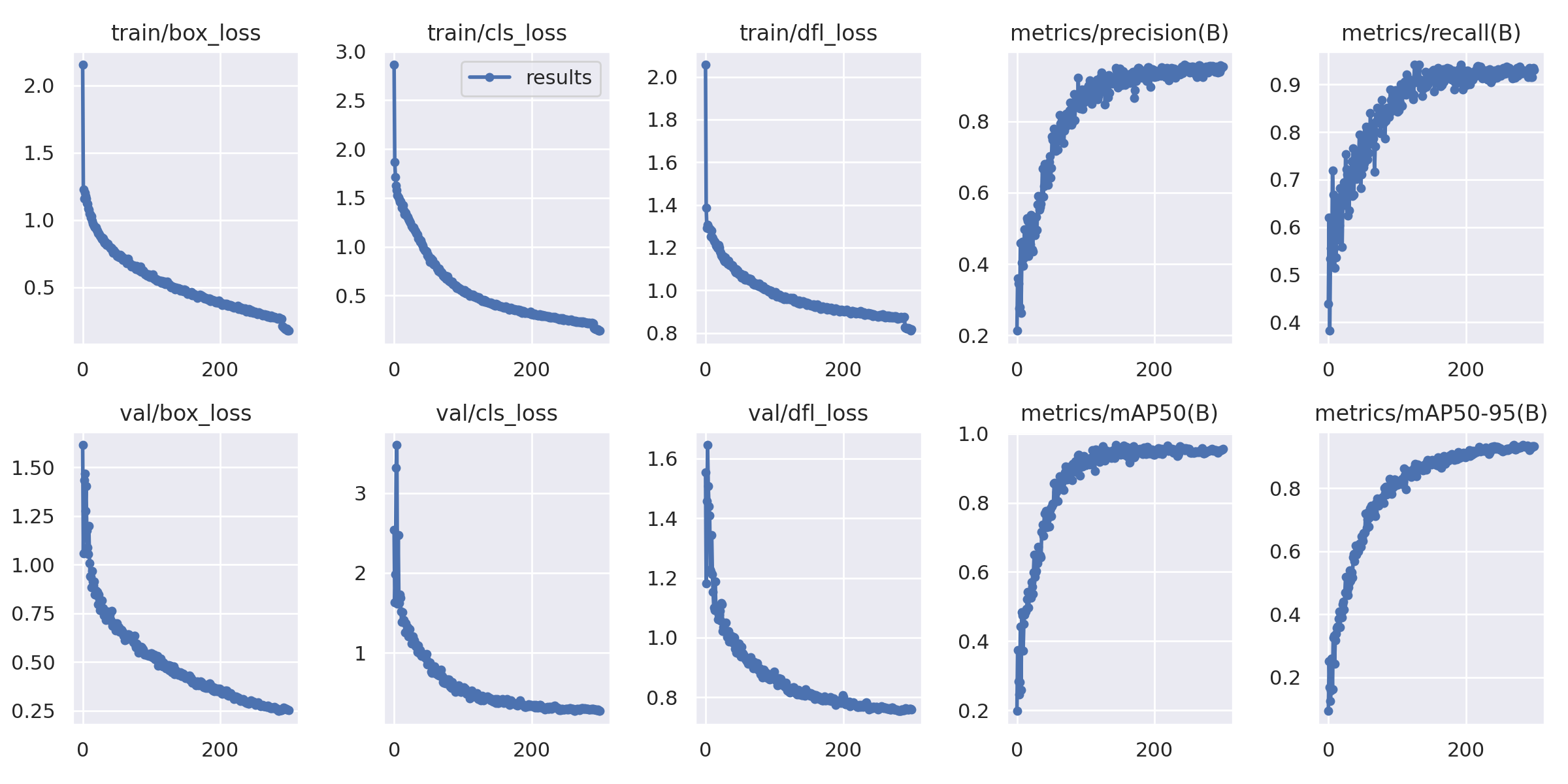
The final model we have taken into consideration is what is called best.pt, and is chosen by YOLO through these metrics, giving a greater weight to the mAP 0.5: 0.95, a lower weight to the mAP 0.5 and a zero weight to recall and precision. The data we get from the training are also automatically graphed as follows.
The results on the test data are:
- Precision of 0.96
- Recall value of 0.93
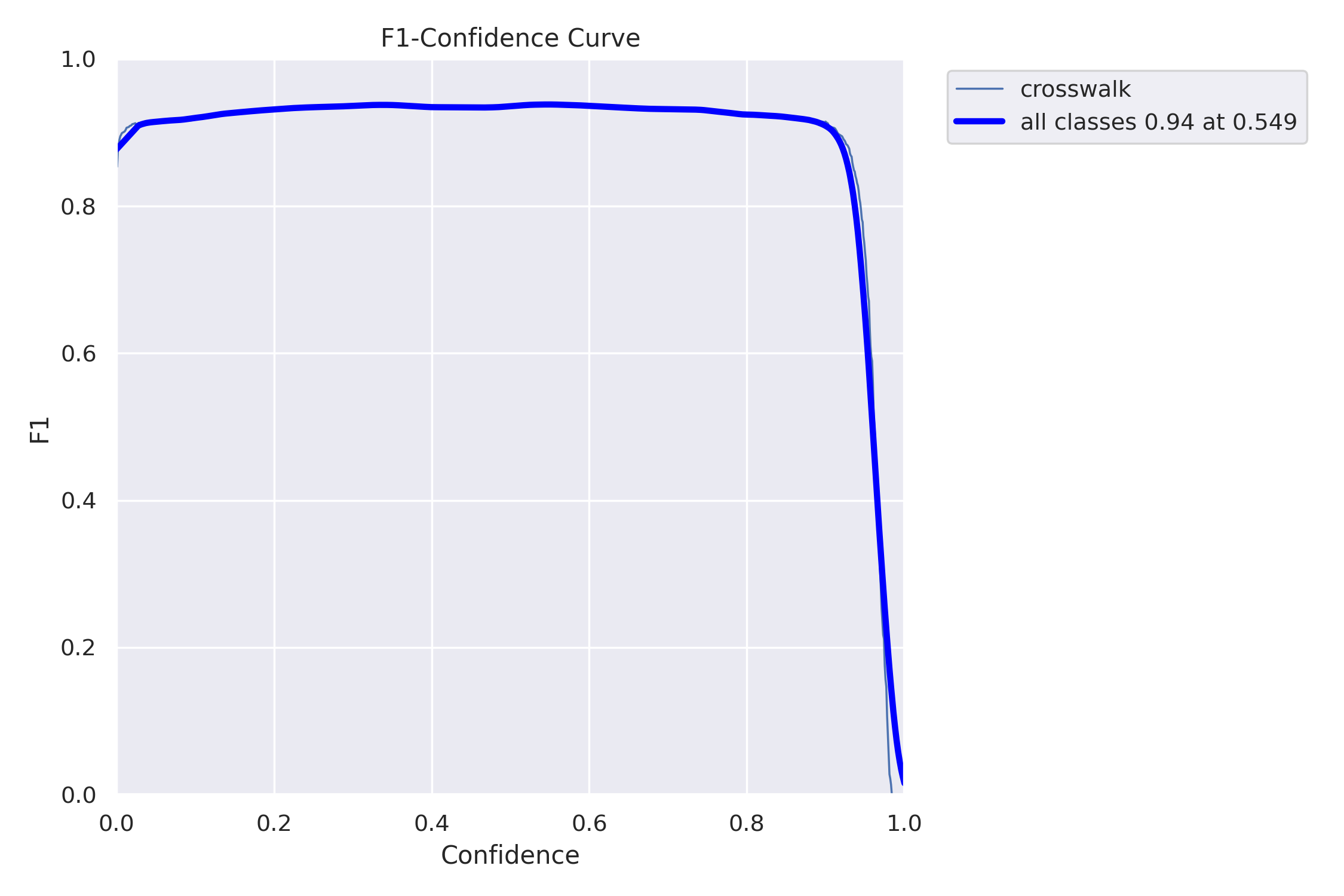
F1 Score:
We wrote oursleves the algorithm to test the IoU metric, obtaining a result equal to 0.63.
Now we describe the extra work we did on our project. The first training on v1.0.0 was almost perfect, but we wanted more. The first run we did was on 250 epochs on yolov5m pre-trained model. We wanted to use yolov5l, but we were limited on GPU RAM by Colab (for better GPU Colab Pro is needed). When we did the first detection, we noticed some problems. First of all, some stop road markings were identified as pedestrian crossings; secondly, not all pedestrian crossings were fully identified. For these reasons, we modified training dataset and parameters. In the version v1.2.0 we used yolov5m as the first run, but this time with 300 epochs. In the training dataset, we did a better augmentation (parameters are explained in dataset paragraph), and then we added some examples of stop road markings, with empty label; in this way, CNN has learned to recognize stops correctly. In the v1.4.0 we used the same dataset and parameters just described , this time with updated yolov8m weight. In the image below, we can see on the left the detection obtained with the first model. On the right, the detection disappeared, as expected.

In this image, instead, we can see that the second model performs better, as it detected a larger portion of the crosswalk.

Last thing we did was to merge YOLO bounding boxes. This was necessary as we have labelled two crosswalks at a time; in this way the model performs better, but in the detection phase crosswalks are identified several times. As you can see from the figure below, we have achieved excellent results and we have also managed to save the maximum confidence.

This work is under GPL-3.0 License, check LICENSE file for details. All rights reserved to Ultralytics for the YOLO model.
For code bug reports and feature requests feel free to ask in Discussions.